前言
本文讲解如何通过数据库客户端界面工具DBeaver连接hive,并解决驱动下载不下来的问题。
1、为什么使用客户端界面工具
为什么使用客户端界面工具而不用命令行使用hive
- 通过界面工具查看分析hive里的数据要方便很多
- 业务人员没有权限通过命令行连接hive
- 领导喜欢在界面工具上查看hive里的数据
2、为什么使用DBeaver
其实在网上搜一下,连接hive的工具还有很多,使用DBeaver的原因是因为我之前连接关系型数据库使用的就是DBeaver,正好DBeaver支持连接hive,且个人认为DBeaver确实挺好用的,支持各种关系型数据库,如连接Oracle数据库不需要像plsql那样自己配置连接文件,只需要在界面上输入url、用户名、密码即可,还有就是DBeaver的快捷键和Eclipse是一样的,比如注释、删除一行、复制一行到下一行等。
3、DBeaver下载、安装
之前我一直用的旧版的,现在在官网上下载了最新版的DBeaver,发现界面功能比旧版好用了很多,亲测连hive没有问题。
下载地址:https://dbeaver.io/download/
我下载的免安装版(不带jre),windows64位,大家可以根据自己情况下载对应版本。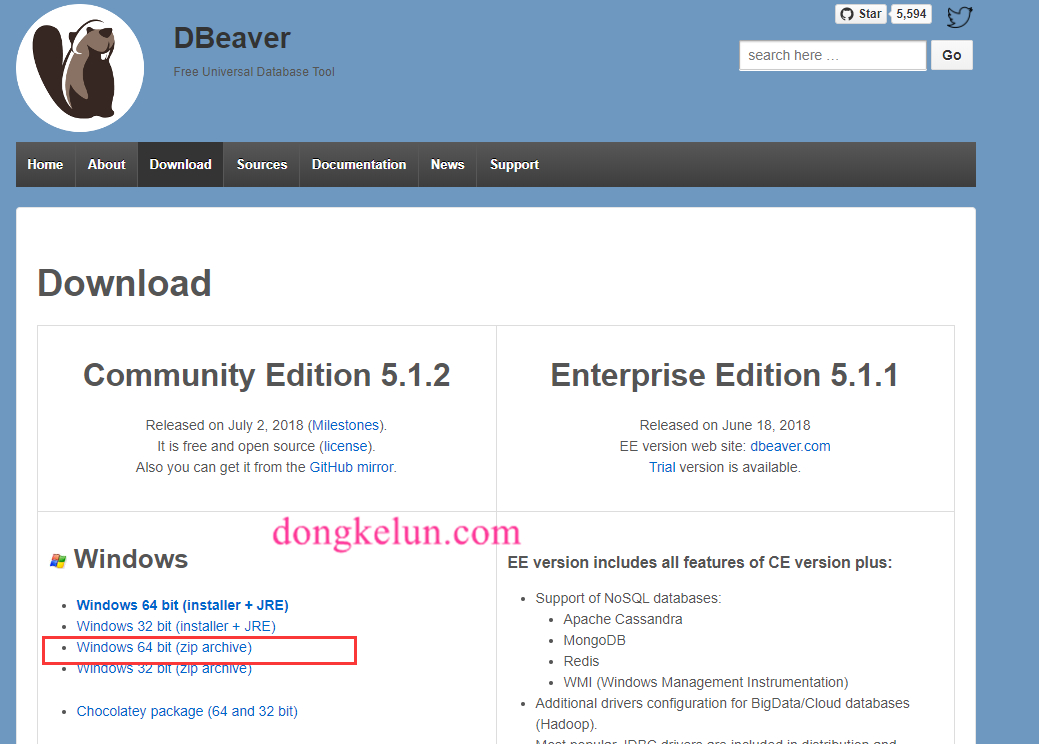
more >>