
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
记录Spark Client 配置,这里的 Spark Client 和 HDFS、YARN 不在一个节点,只是一个单节点的 Spark Client,需要能连接其他节点的大数据集群的 Hive 和 能提交到Yarn 。
环境信息
大数据节点(已配置好Spark):
192.168.44.154
192.168.44.155
192.168.44.156
客户端:
192.168.44.157 (新装操作系统)
1、配置Java
从154节点拷贝jdk安装目录到157
安装目录:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_641
2
3
4
5mkdir /usr/lib/jvm
scp -P 6233 -r /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64 192.168.44.157:/usr/lib/jvm/
scp -P 6233 /etc/profile.d/java.sh 192.168.44.157:/etc/profile.d/
source /etc/profile
ln -s /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64 /usr/local/jdk
添加软连接是因为在 spark-env.sh 中配置了:export JAVA_HOME=/usr/local/jdk 。可参考:Spark Standalone 集群配置
java.sh1
2
3
4export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
2、网络
客户端和大数据节点网络互通,如果开启了防火墙,需要添加白名单1
2
3
4
5
6
7firewall-cmd --permanent --add-rich-rule="rule family='ipv4' source address='192.168.44.157' accept"
firewall-cmd --reload
firewall-cmd --list-all
firewall-cmd --permanent --add-rich-rule="rule family='ipv4' source address='192.168.44.0/24' accept"
firewall-cmd --reload
firewall-cmd --list-all
3、配置hosts
将大数据节点的hosts配置内容拷贝到157
4、时间同步
Spark客户端要和大数据节点时间(包含时区)一致 (认证kerberos需要)1
2timedatectl set-timezone Asia/Shanghai
date -s "Fri May 17 10:23:00 CST 2024"
5、配置文件
hadoop1
2mkdir -p /etc/hadoop/conf
scp -P 6233 -r /usr/hdp/3.1.0.0-78/hadoop/conf/* 192.168.44.157:/etc/hadoop/confkerberos1
2
3mkdir /etc/security/keytabs/
scp -P 6233 /etc/security/keytabs/spark.service.keytab 192.168.44.157:/etc/security/keytabs/
scp -P 6233 /etc/krb5.conf 192.168.44.157:/etc/
6、Spark 安装包
将154 上的spark打包并传到157,然后解压
1 | cd /usr/hdp/3.1.0.0-78/ |
spark配置文件:spark 配置文件目录为软连接,所以打包拷贝时只是软连接,并没有拷贝实际内容,需要手动拷贝一下
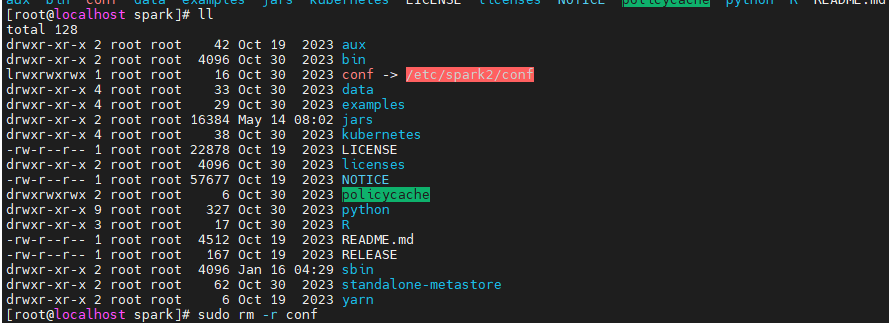
1 | scp -P 6233 /etc/spark2/conf 192.168.44.157:/opt/spark |
因为在154已经配置好Spark了为了保证版本一致和配置文件一致,所以选择直接从154拷贝,其中conf文件下需包含 hive-site.xml 这样才能连接 hive。如果没有已经配置好的Spark,可以下载对应版本的开源安装包,手动将hive-site.xml等文件拷贝到 conf 文件夹
7、环境变量
1 | export HADOOP_CONF_DIR=/etc/hadoop/conf |
这里的 HADOOP_CONF_DIR 是为了 Spark 获取 hadoop配置 :hdfs-site.xml core-site.xml yarn-site.xml 等,这样Spark才能提交到远程Yarn集群、读取Hive表。HADOOP_CONF_DIR 也可以在 spark-env.sh 中配置,同样可参考:Spark Standalone 集群配置
8、验证
spark-shell
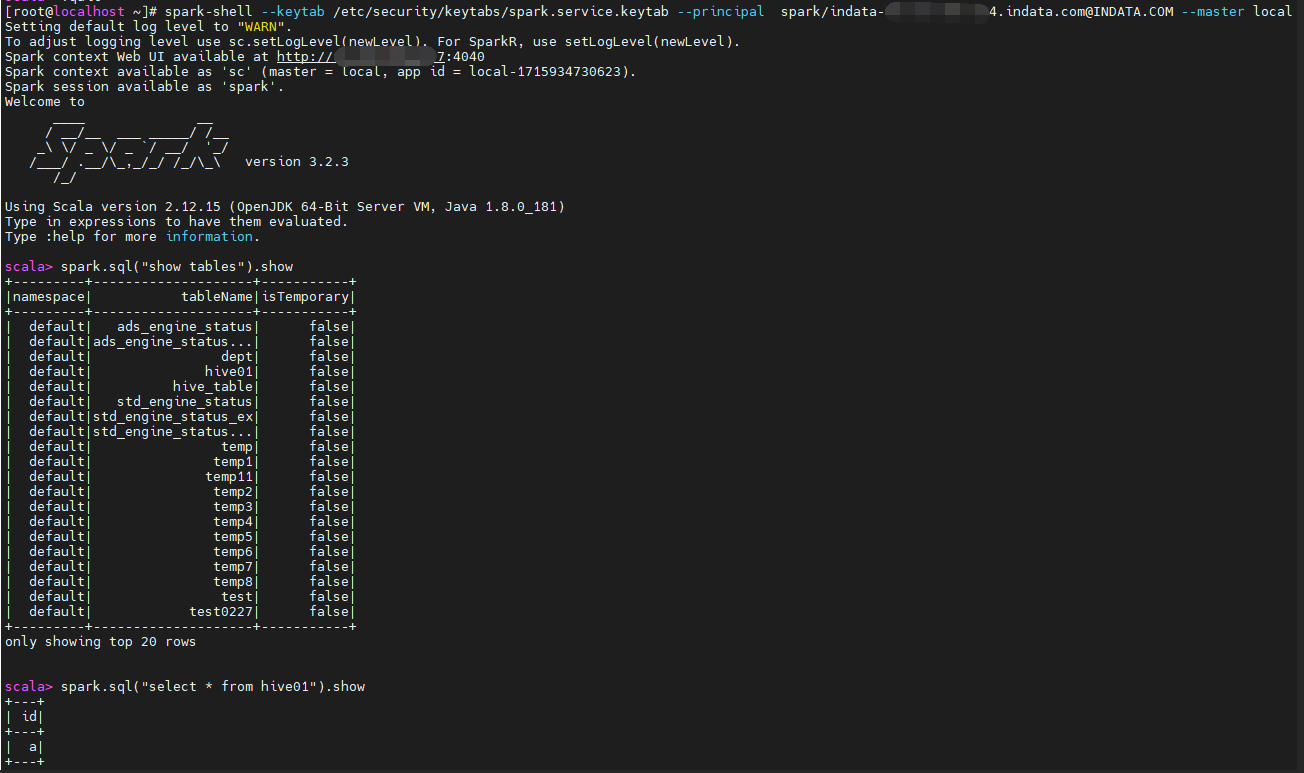
local 模式
1 | spark-shell --keytab /etc/security/keytabs/spark.service.keytab --principal spark/indata-192-168-44-154.indata.com@INDATA.COM --master local |
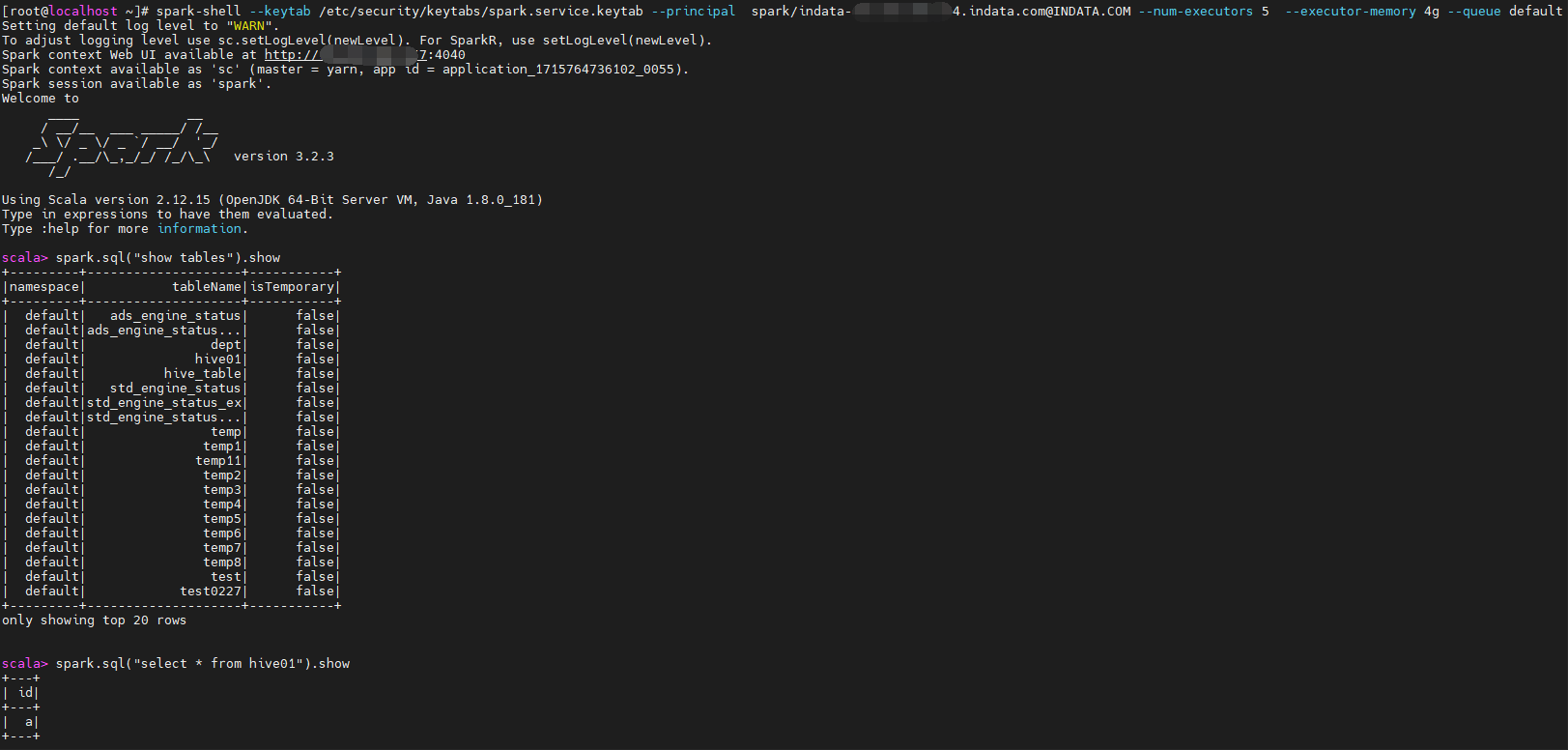
yarn 模式1
spark-shell --keytab /etc/security/keytabs/spark.service.keytab --principal spark/indata-192-168-44-154.indata.com@INDATA.COM --num-executors 5 --executor-memory 4g --queue default

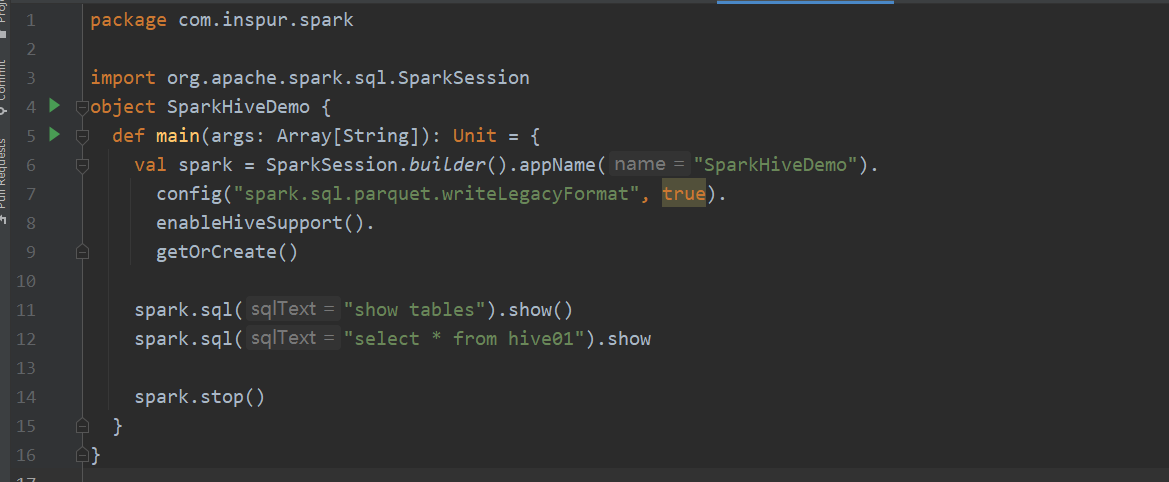
spark-submit jar包
1 | spark-submit --keytab /etc/security/keytabs/spark.service.keytab --principal spark/indata-192-168-44-154.indata.com@INDATA.COM --num-executors 5 --executor-memory 4g --queue default --class com.inspur.spark.SparkHiveDemo ~/spark-demo-1.0.jar |


9、pyspark
有的项目有使用 pyspark 的需求
安装Python3
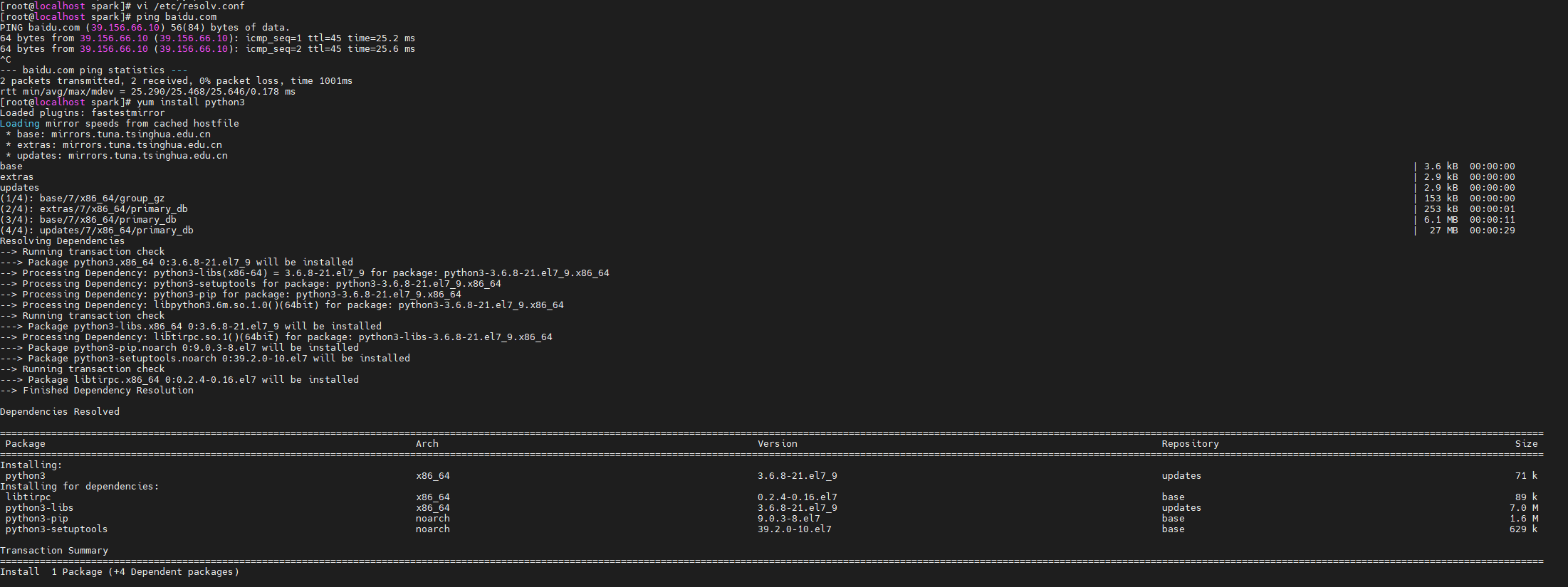
先配置连接外网环境1
yum install python3
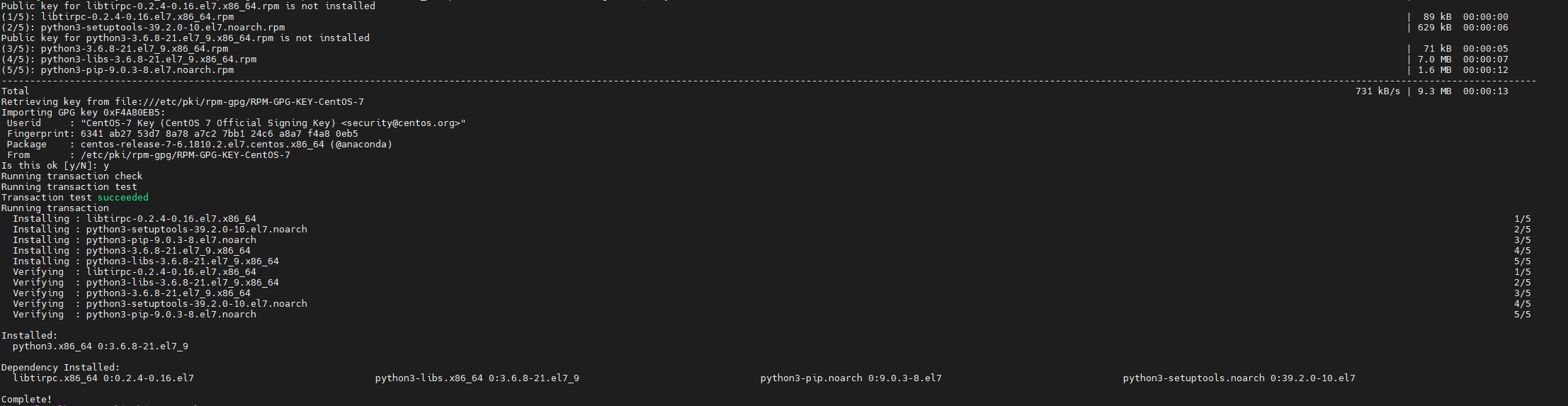
pyspark默认使用python3:
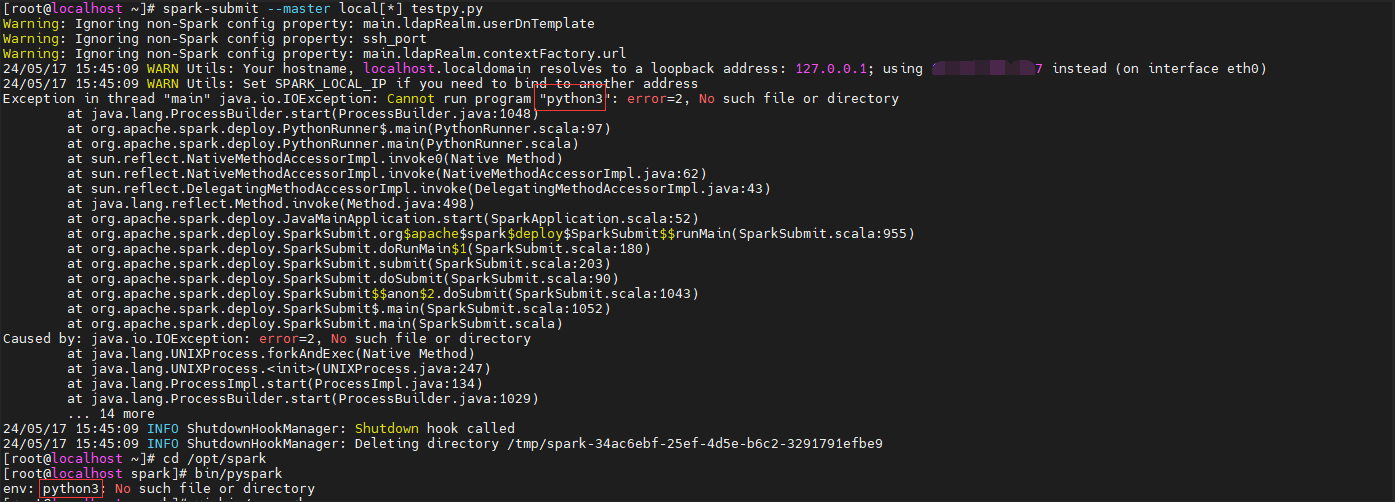
验证
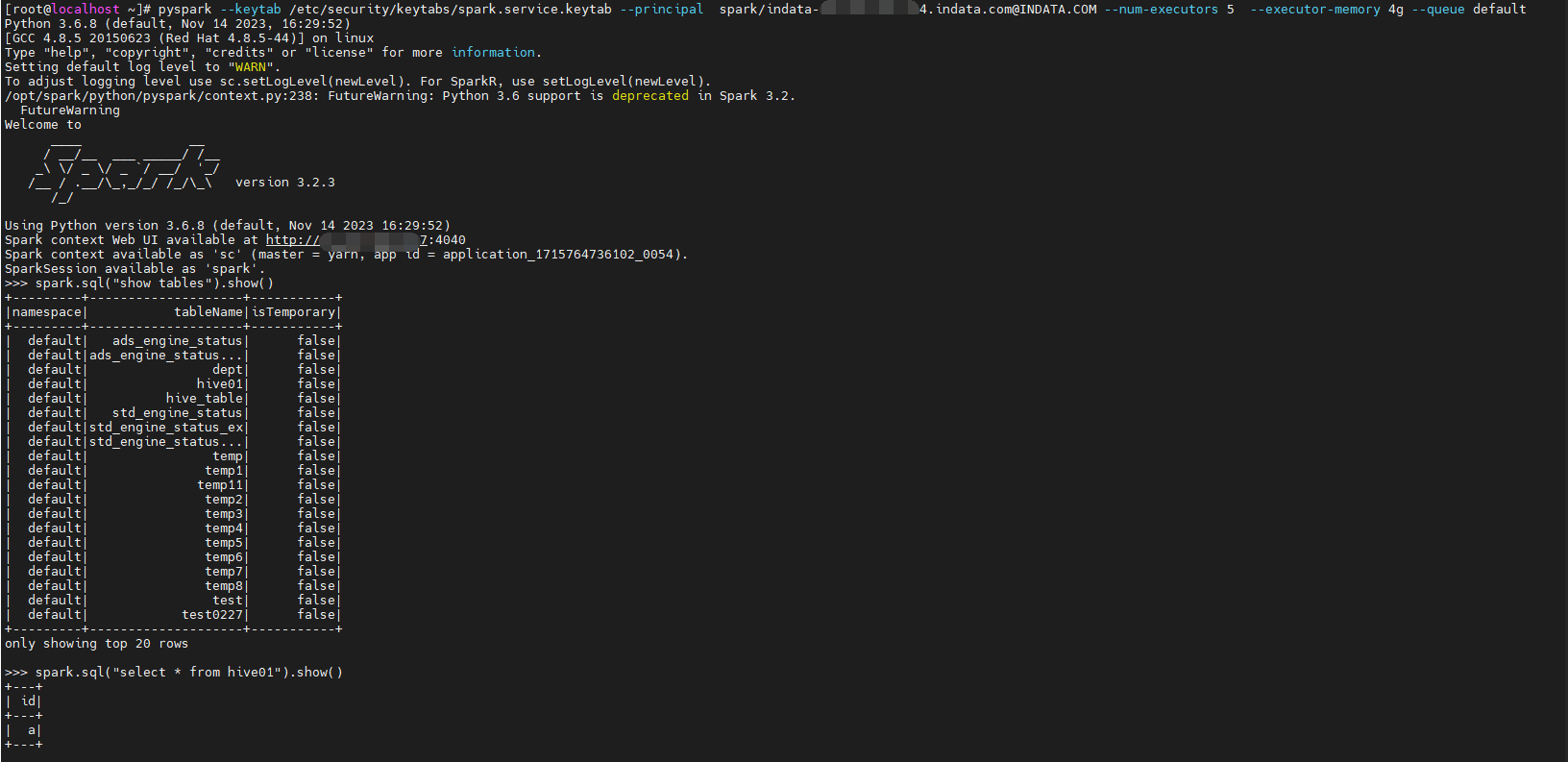
1 | pyspark --keytab /etc/security/keytabs/spark.service.keytab --principal spark/indata-192-168-44-154.indata.com@INDATA.COM --num-executors 5 --executor-memory 4g --queue default |
testpy.py1
2
3
4
5
6
7
8
9
10
11from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("PythonSparkHiveDemo") \
.enableHiveSupport() \
.getOrCreate()
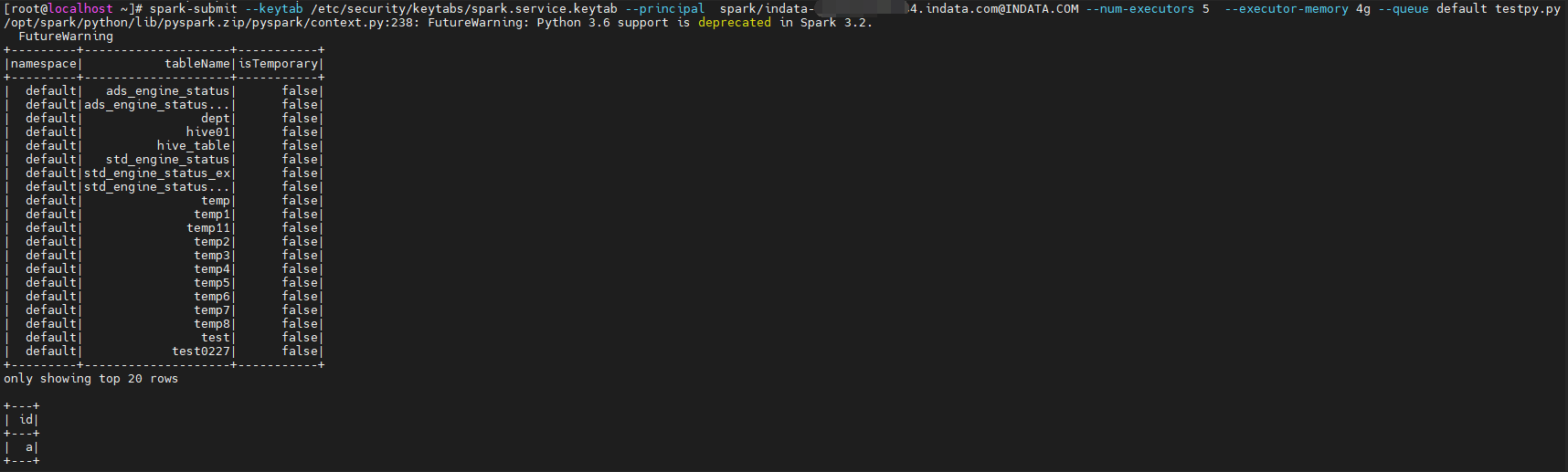
spark.sql("show tables").show()
spark.sql("select * from hive01").show()
spark.stop()1
spark-submit --keytab /etc/security/keytabs/spark.service.keytab --principal spark/indata-192-168-44-154.indata.com@INDATA.COM --num-executors 5 --executor-memory 4g --queue default testpy.py

相关阅读


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Spark Client 配置
本文链接:https://dongkelun.com/2024/05/18/spark/sparkClientConf/
欢迎关注我的公众号