
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
之前很少用MOR表,现在来学习总结一下。首先总结一下 compaction 遇到的问题。
版本
- Flink 1.15.4
- Hudi 0.13.0
表类型
COW 和 MOR
- COW:COW COPY_ON_WRITE 写时复制,写性能相比于MOR表差一点,因为每次写数据都会合并文件,但是能及时读取到最新的表数据。数据文件只有 parquet
- MOR:MERGE_ON_READ 读时合并,写性能相比于COW会快,因为写数据时只追加不合并(.log文件),只有compaction才会合并文件,将.log文件合并为 paruqet文件。有两种表类型 ro、rt,ro表只会读parquet文件,rt 表会将paruqet文件和.log文件合并。也就是虽然rt表可以读取所有的最新的数据,但是要先合并文件,性能要比读取COW表差一些。
compaction
官方文档:https://hudi.apache.org/docs/compaction
compaction 只在MOR表中有,COW表是没有的,所以相比较而言,COW表使用起来相对简单,问题也少,这也是为啥开始我们主要是COW表的原因。
Compaction is a table service employed by Hudi specifically in Merge On Read(MOR) tables to merge updates from row-based log files to the corresponding columnar-based base file periodically to produce a new version of the base file. Compaction is not applicable to Copy On Write(COW) tables and only applies to MOR tables.
压缩(Compaction)是Hudi专门在读取合并(MOR)表中使用的一种表服务,用于定期将基于行的日志文件(.log)的更新合并到相应的基于列的基础文件(如.parquet),以生成基础文件的新版本。压缩不适用于写入时复制(COW)表,仅适用于MOR表。
compaction 参数
一般以hoodie开头的参数为Hudi公共参数,不是以hoodie开头的为 hudi flink独有参数,在类
FlinkOptions。
- compaction.async.enabled 是否开启异步,默认true (Flink 独有)
- compaction.trigger.strategy 默认 num_commits ,可选项有 num_commits、time_elapsed、num_and_time、num_or_time (Flink 独有)
num_commits:当达到N个增量提交时触发压缩
time_elapsed:当自上次压缩以来经过的时间>N秒时触发压缩
num_and_time:当同时满足num_COMMITS和time_ELAPSED时触发压缩
num_or_time:当满足num_COMMITS或time_ELAPSED时触发压缩 - compaction.delta_commits 触发Compaction所需要的最大deltacommit次数,默认5次 (Flink 独有)
- hoodie.compact.inline 默认false,当设置为true时,每次写入后都会触发压缩服务。虽然操作更简单,但这会增加写入路径上的额外延迟。(也需要判断compaction.delta_commits) (公共参数)
- hoodie.compact.inline.max.delta.commits 默认5次, 在上次压缩之后,在尝试调度新压缩之前的增量提交数。此配置仅对基于提交数量的压缩触发策略生效,即NUM_commits、NUM_commits_AFER_LAST_REQUEST、NUM_AND_TIME和NUM_OR_TIME。 (公共参数)
- hoodie.log.compaction.inline 默认false,当设置为true时,每次写入后都会触发压缩服务。虽然操作更简单,但这会增加写入路径上的额外延迟。(也需要判断compaction.delta_commits)(公共参数)
- hoodie.compact.schedule.inline 默认false,当设置为true时,压缩服务将在每次写入后尝试进行内联调度。用户必须确保他们有一个单独的作业来为这个编写器调度的作业运行异步压缩(执行)。用户可以选择将
hoodie.compact.inline和hoodie.comcompact.schedule.inline都设置为false,并由任何异步进程触发调度和执行。但是,如果hoodie.compact.inline设置为false,而hoodie.comcompact.schedule.inline则设置为true,则常规编写器将内联调度压缩,但用户需要触发异步作业来执行。如果hoodie.compact.inline设置为true,则常规编写器将以内联方式进行调度和执行以进行压缩。(公共参数)实际测试:仅设置hoodie.compact.inline 为true,生效;
仅设置 hoodie.compact.schedule.inline 为true 不生效;
hoodie.compact.inline 和 hoodie.compact.schedule.inline 都设置为true 报错:Caused by: java.lang.IllegalArgumentException: Either of inline compaction (hoodie.compact.inline) or schedule inline compaction (hoodie.compact.schedule.inline) can be enabled. Both can’t be set to true at the same time. true, true;
hoodie.log.compaction.inline 设置为true,报错:java.lang.UnsupportedOperationException: Log compaction is not supported for this table type(mor和和cow都报错,但写的数据是完整的可以成的查出来)。
总结:只设置 hoodie.compact.inline = true 即可。 - compaction.tasks 执行实际压缩的任务的并行性,默认与写入任务的并行度相同 (Flink 独有)
批写
批写:source 有界。
批写时,使用默认 compaction 参数会有问题,因为默认情况下 compaction 为异步的,比如只插入一条数据,当写数据的流程完成后,程序就会关闭,这时异步的 compaction 就会失败。
所以应该将异步关闭,使用 inline :
1 | 'compaction.async.enabled'= 'false', |
实际使用中不能将 compaction.delta_commits 和 hoodie.compact.inline.max.delta.commits 设置为1,因为这意味着每一次都会合并log文件,和cow表一样,这样比如直接用cow表了。设置为1只是为了更快的验证 compaction 。另外如果想验证或调试 查询时 paruqet和log文件合并的逻辑,应该将次数这是为2,否则查询时只会读parquet文件。
批写实测:
RUNTIME_MODE = STREAMING 时 (默认为STREAMING):
- 1、默认参数,即compaction.async.enabled = true:第一次(compaction.delta_commits,默认第五次)生成 compaction.requested,下一次生成 .compaction.inflight,然后会报异常,接下来每次都报同样的异常,具体异常见后面的异常分析。
- 2、仅设置 compaction.async.enabled = false: 只是 第一次生成.compaction.requested,后面便不再生成 .compaction.inflight 也就是不再会触发 compaction ,也不会报错,只有告警:BaseHoodieCompactionPlanGenerator: No operations are retrieved for /tmp/flink/hudi/test_mor,这样就一直只写 .log 文件,永远不合并。
- 3、仅设置 hoodie.compact.inline = true: 可以成功 compaction ,也就是第一次便会生成 .compaction.requested、.compaction.inflight、.commit,将 .log 文件合并成 .parquet 文件。(compaction.async.enabled 等于 true 或 false,结果都一样)
RUNTIME_MODE = BATCH 时
- 1、默认参数:可以成功 compaction (默认第五次 compaction)
- 2、显示设置 compaction.async.enabled = true: 可以成功 compaction
- 3、显示设置 hoodie.compact.inline = false: 可以成功 compaction
- ……
也就是当 RUNTIME_MODE = BATCH ,无论设置是否异步、是否inline 都可以成功 compaction。(原因见后面源码分析)
小结:
- 1、之所以单独总结批写的 compaction ,因为一般开始学习时喜欢使用批写,便于调试总结。而默认参数下 compaction 会失败,所以总结分析一下原因。
- 2、要想批写成功 compaction ,两种方法 1. 设置 RUNTIME_MODE = BATCH; 2. 设置 hoodie.compact.inline = true
如何设置 RUNTIME_MODE:
代码:
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
sql:1
2SET 'execution.runtime-mode' = 'batch'; -- execution mode either 'batch' or 'streaming'
set execution.runtime-mode=batch; -- 也可以不加引号
delta_commits
关于 compaction.delta_commits 和 hoodie.compact.inline.max.delta.commits ,官方并没有给出明确的关系和区别。经测试:
无论是否异步、是否 inline 、RUNTIME_MODE 是否等于BATCH,规律一样:这俩个参数单独显示设置哪个参数都会生效,如果这两个参数同时设置,则以 hoodie.compact.inline.max.delta.commits 为准,也就是 hoodie.compact.inline.max.delta.commits 优先级高,如果都不设置,则按照默认五次。
异常
默认参数下的异常:
1 | 24/05/22 17:21:09 ERROR CompactOperator: Executor executes action [Execute compaction for instant 20240522172031878 from task 3] error |
原因分析:默认参数下,使用异步 Compaction, 当写数据的流程完成后,程序就会关闭,这时异步的 compaction 还没完成,因主程序关闭导致读取 hoodie.properties 时报异常:java.nio.channels.ClosedByInterruptException,从而抛出:HoodieIOException: Could not load Hoodie properties from /tmp/flink/hudi/test_mor/.hoodie/hoodie.properties,导致 compaction 失败。
批写示例
索引:FLINK_STATE
代码
可以在Idea中调试,比较方便
SQL
test-mor.sql
1 | set execution.target=yarn-per-job; |
流写示例
代码
可以在Idea中调试,比较方便
SQL
test_streaming_mor.sql
1 | set parallelism.default=1; |
Hive查询
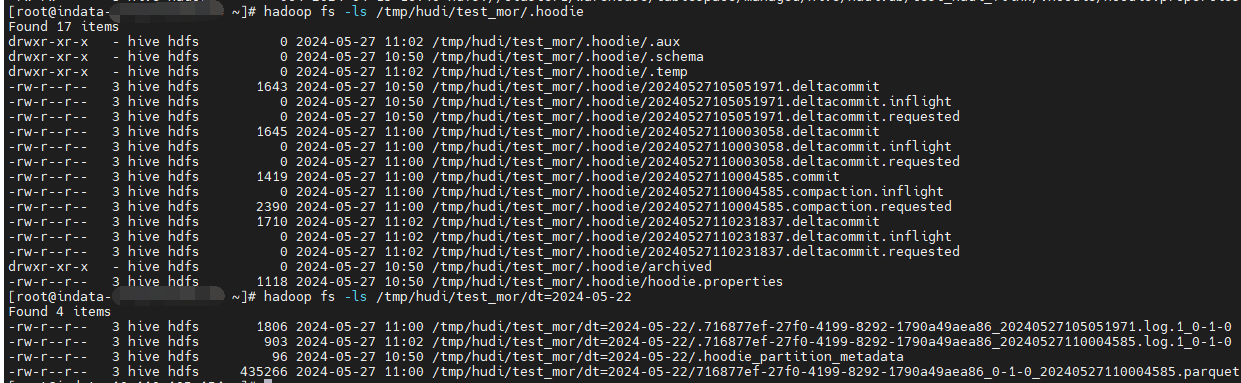
在第一次 compaction 没有完成之前,没有 .paruqet 文件只有 .log 文件。这时不论是 ro 表还是 rt表 ,hive 查询都为空,只有有了 .parquet 文件之后,查询 rt 表才会将 .parquet 文件和 .log 文件合并。(仅限Hive)
delta.commits 改成 2, insert 3次 , hive 查询结果:

表结构
.log 文件对应: .deltacommit.requested->.deltacommit.inflight->.deltacommit
.parquet 文件: .compaction.requested->.compaction.inflight->.commit
对比 cow 表:
.parquet 文件: .commit.requested->.inflight->.commit
delta.commits 改成 2, insert 3次 查看
规律
FLINK_STATE 和 BUCKET 索引不完全相同; Linux 和 Windows 也不太一样
FLINK_STATE
Linux
由于只看最后结果不太明显,所以改为 insert 一次看一次
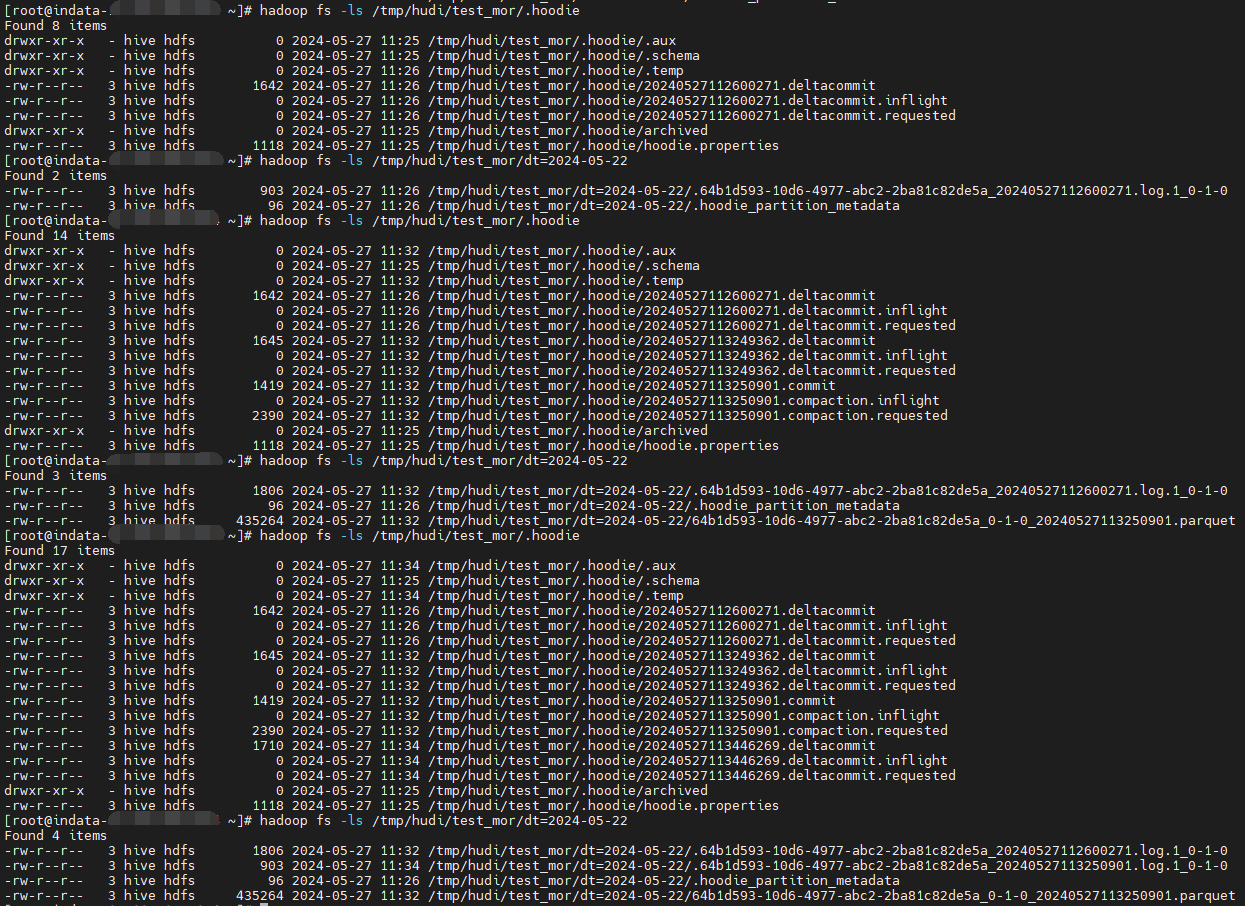
由上图:1
2
3
41、 20240527112600271.deltacommit -> .64b1d593-10d6-4977-abc2-2ba81c82de5a_20240527112600271.log.1_0-1-0
2.1、20240527113249362.deltacommit -> .64b1d593-10d6-4977-abc2-2ba81c82de5a_20240527112600271.log.1_0-1-0 (append写上次的文件)
2.2、20240527113250901.compaction -> 64b1d593-10d6-4977-abc2-2ba81c82de5a_0-1-0_20240527113250901.parquet
3、 20240527113446269.deltacommit ->.64b1d593-10d6-4977-abc2-2ba81c82de5a_20240527113250901.log.1_0-1-0
小结:
- 1、无论是.log 还是 .parquet 所有的文件前缀(fileId)都一样:64b1d593-10d6-4977-abc2-2ba81c82de5a
- 2、compaction 之前会 append 到同一个 .log 文件中,不会生成新的 .log 文件
- 3、compaction 之后生成新的 .log 文件
备注:上面的结论可能覆盖的测试场景并不全面(已包含 insert、update 场景)
Windows
每次 insert 主键不一样 (纯 insert)
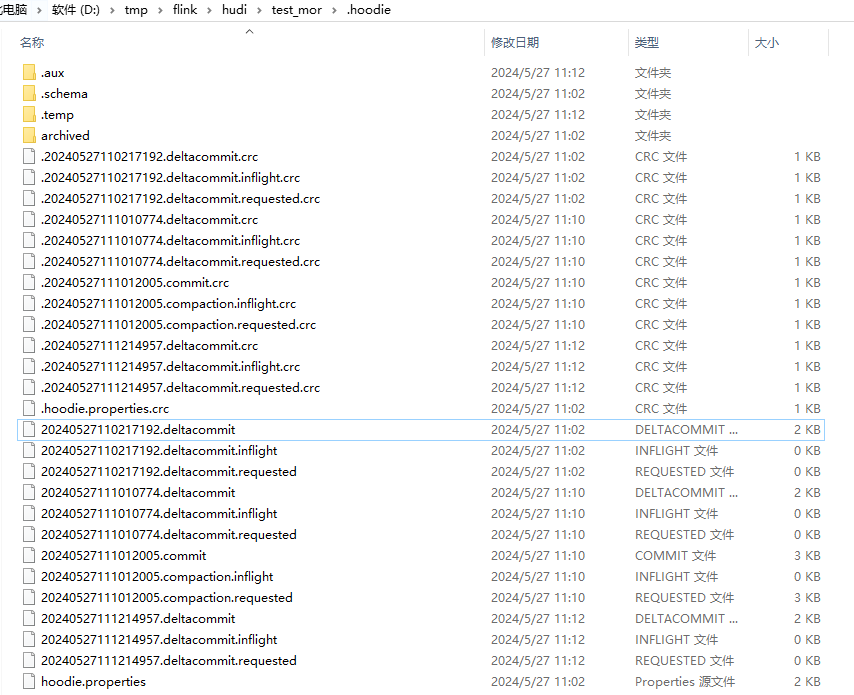
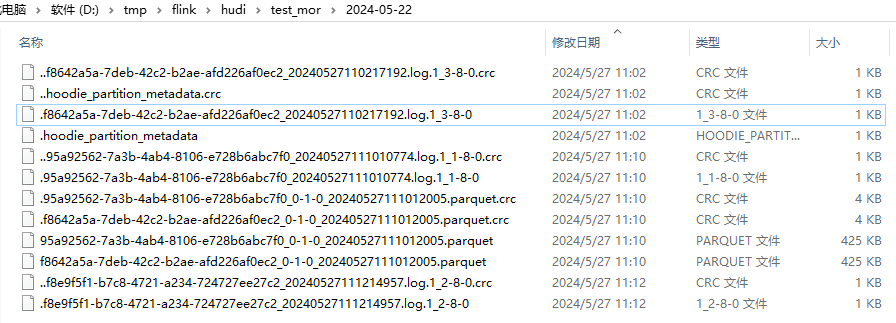
由上图:1
2
3
41、 20240527110217192.deltacommit -> .f8642a5a-7deb-42c2-b2ae-afd226af0ec2_20240527110217192.log.1_3-8-0
2.1、20240527111010774.deltacommit -> .95a92562-7a3b-4ab4-8106-e728b6abc7f0_20240527111010774.log.1_1-8-0
2.2、20240527111012005.compaction -> f8642a5a-7deb-42c2-b2ae-afd226af0ec2_0-1-0_20240527111012005.parquet 和 95a92562-7a3b-4ab4-8106-e728b6abc7f0_0-1-0_20240527111012005.parquet
3、20240527111214957.deltacommit -> .f8e9f5f1-b7c8-4721-a234-724727ee27c2_20240527111214957.log.1_2-8-0
每次 insert 主键一样(update、upsert)

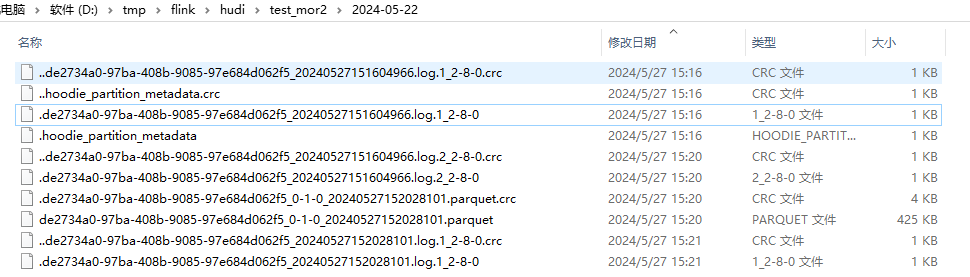
由上图:1
2
3
41、 20240527151604966.deltacommit -> .de2734a0-97ba-408b-9085-97e684d062f5_20240527151604966.log.1_2-8-0
2.1、 20240527152026848.deltacommit -> .de2734a0-97ba-408b-9085-97e684d062f5_20240527151604966.log.2_2-8-0
2.2、 20240527152028101.compaction -> de2734a0-97ba-408b-9085-97e684d062f5_0-1-0_20240527152028101.parquet
3、 20240527152141075.deltacommit -> .de2734a0-97ba-408b-9085-97e684d062f5_20240527152028101.log.1_2-8-0
小结:
- 1、对于主键不同的:每次 .log 的前缀不一样;主键相同:每次 .log 的前缀一样
- 2、每一次 .deltacommit 都会生成一个新的 .log ,无论前缀(fileId)是否一样;如果 fileId一样,compaction 之前的文件以 .log.1 .log.2 区分,时间后缀相同
- 3、compaction 时一个 fileId 文件对应 一个 .parquet 文件
- 4、主键不同时:后缀的时间都和元数据文件时间相同;主键相同时,后缀的时间和上一个文件相同,.log.1 .log.2 区分
备注:上面的截图每次都insert一条,经测试发现如果一次insert多条,里面包含上一个 .log 的文件里面的主键,和主键相同时的结论一样,所以对于主键相同的规律可以统一总结为 update、upsert 场景(只要有update即可)
BUCKET
Linux
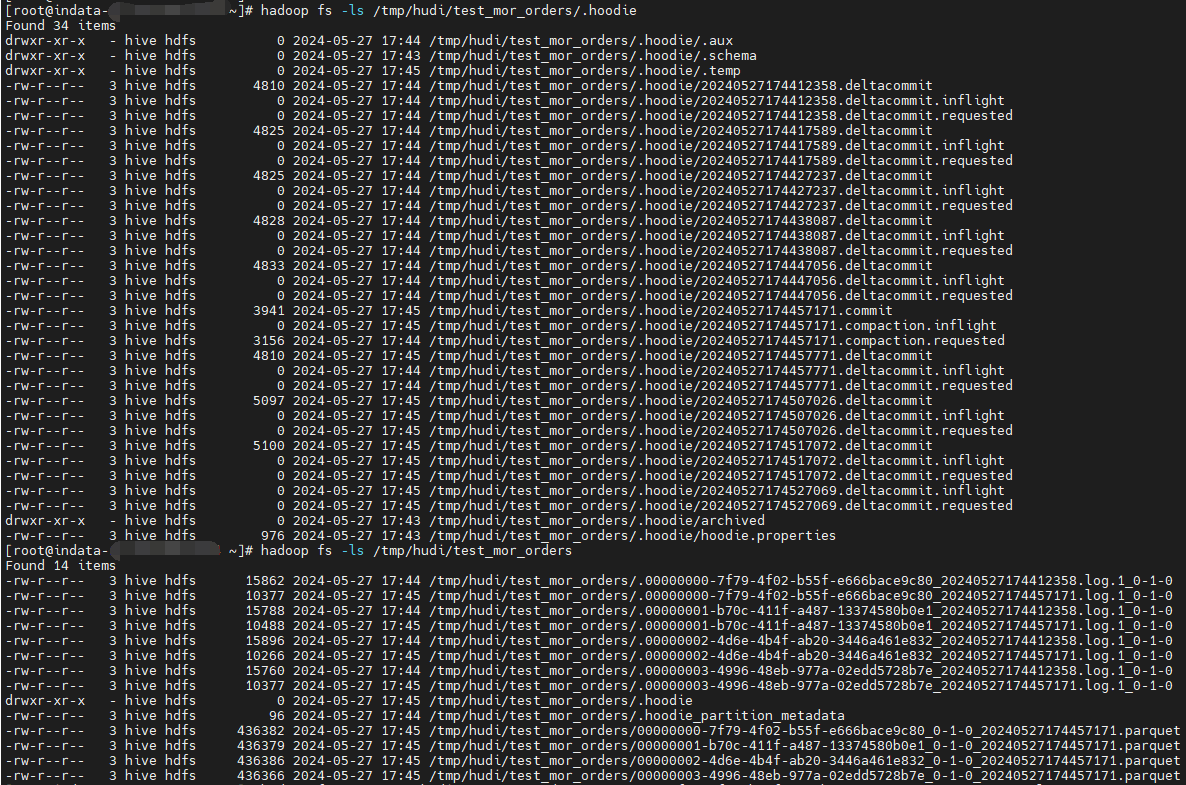
由上图:
- 1、由于是 BUCKET 索引,所以无论是.log 还是 .parquet 所有的文件前缀(fileId)都一样,且有4个,对应4个桶
- 2、compaction 之前会 append 到同一个 .log 文件中,不会生成新的 .log 文件
- 3、compaction 之后生成新的 .log 文件
- 4、默认五次触发 compaction
备注:由于流写不间断,不好一个一个看,可以自己分析文件内容
Windows
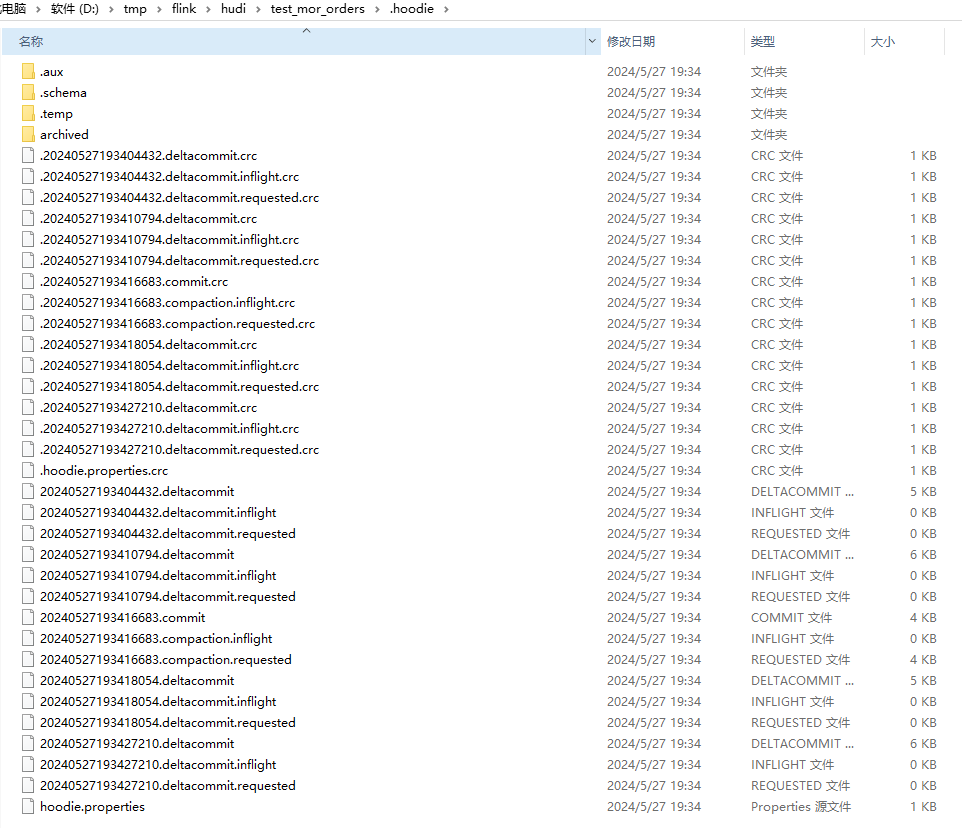
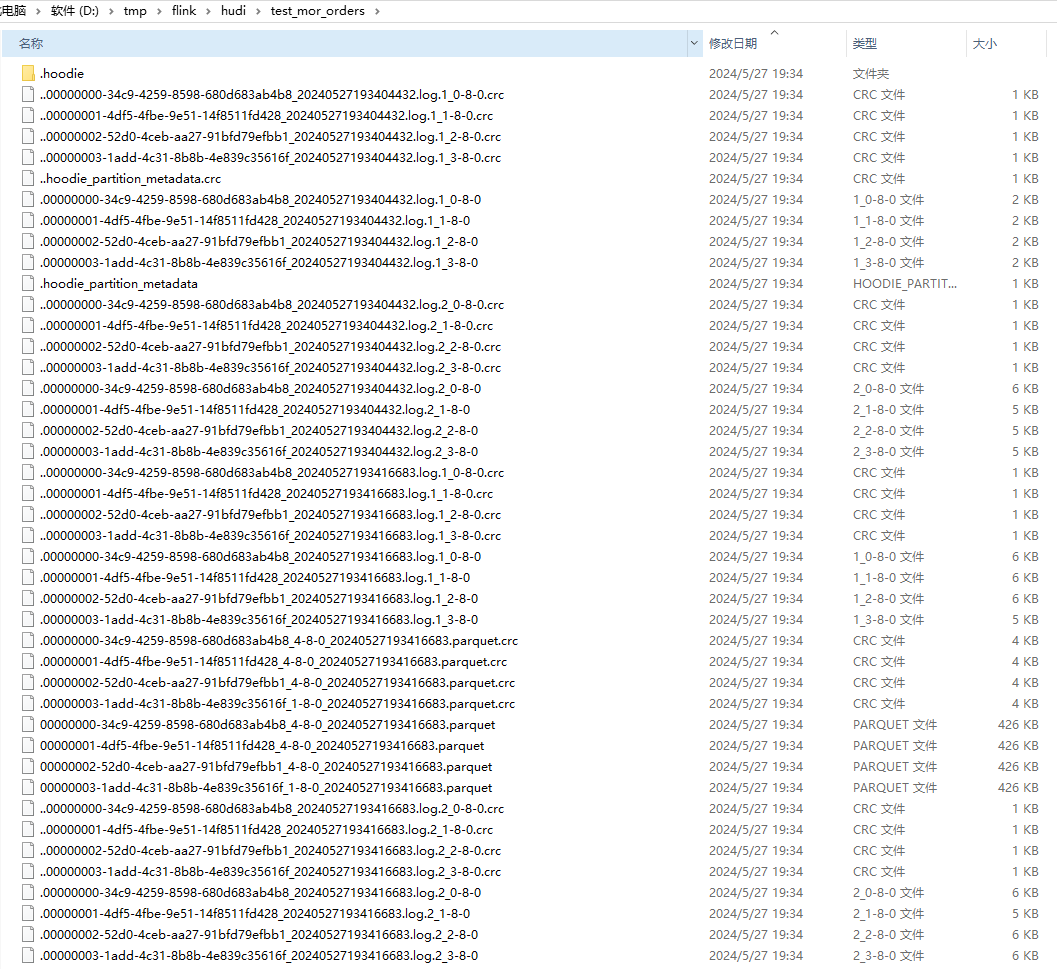
由上图:
- 1、由于是 BUCKET 索引,所以无论是.log 还是 .parquet 所有的文件前缀(fileId)都一样,且有4个,对应4个桶
- 2、每一次 .deltacommit 都会生成一个新的 .log, compaction 之前的文件以 .log.1 .log.2 区分,时间后缀相同
- 3、compaction 时一个 fileId 文件对应 一个 .parquet 文件,也就是 .parquet 文件数等于桶数
- 4、compation 之后生成的 .log 文件的前缀和 上次的 .parquet前缀相同,只是后缀不同,以 .log.1 .log.2 区分 。(这里的时间后缀并没有与 .deltacommit 对应 )
源码
HoodieTableSink.getSinkRuntimeProvider
1 | if (OptionsResolver.needsAsyncCompaction(conf)) { |
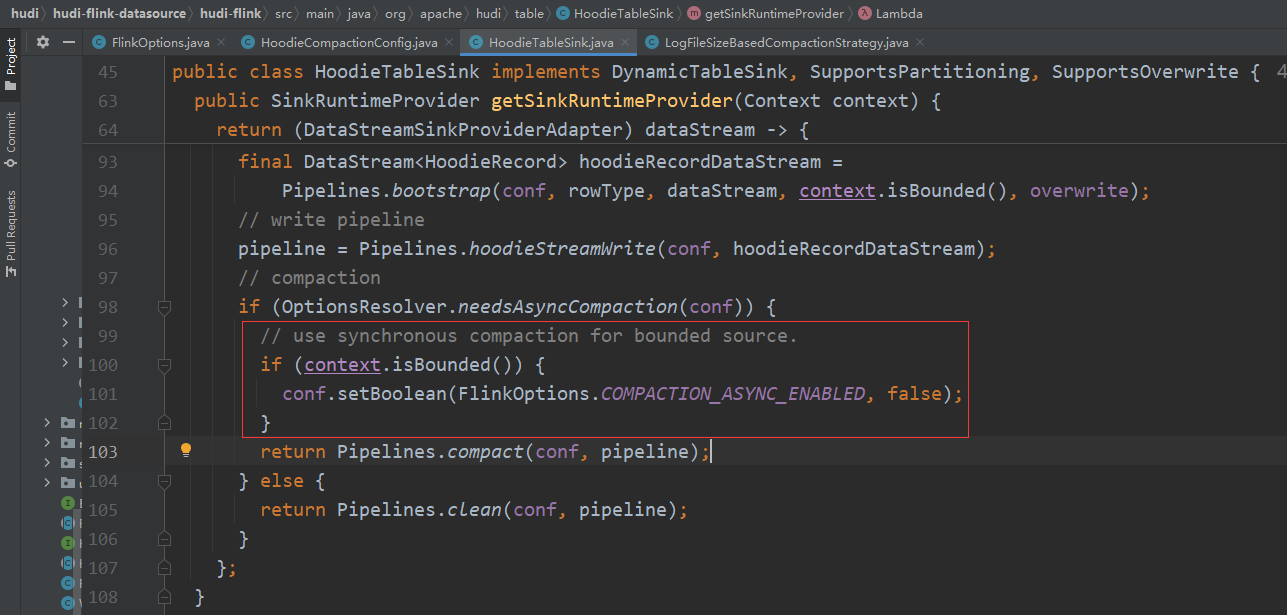
上面提到 RUNTIME_MODE 等于 BATCH 和 STREAMING 时的表现是不一样的,原因就在这一块源码里。根据注释,本意是想判断 source 有界是就将异步关掉,但是 context.isBounded() 只能判断 RUNTIME_MODE 是否为 BATCH ,并不能判断 source 是否有界。所以当 RUNTIME_MODE = BATCH 时 compaction 是成功的。如果这里的源码能判断 source 是否有界,无论 RUNTIME_MODE 是 STREAMING 还是 BATCH,compaction 都不会有问题。
相关阅读


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Hudi Flink MOR 学习总结
本文链接:https://dongkelun.com/2024/05/24/hudi/hudiFlinkMor/
欢迎关注我的公众号