
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
本文讲解如何通过数据库客户端界面工具DBeaver连接远程Kerberos环境下的Hive。
因为在远程服务器上的命令行里写SQL查询Hive表,如果数据量和表字段比较多,命令行界面不利于分析表数据,所以需要客户端工具如DBeave远程连接Hive查询数据,但是DBeaver默认的不能访问Kerberos下的Hive,需要一些配置才可以访问,这里记录一下。
1、DBeaver连接Hive
关于DBeaver如何连接正常的不带Kerberos认证的Hive,请参考通过数据库客户端界面工具DBeaver连接Hive,本文只讲解如何在Windows上用DBeaver对kerberos认证
2、安装Kerberos客户端
官网下载https://web.mit.edu/kerberos/dist/index.html,我下载的是这个:Kerberos for Windows Release 4.1 - current release
下载下来后,一键安装
3、krb5.ini
我的kerberos客户端安装目录为D:\program\company\kerberos,将集群上的/etc/krb5.conf,复制到此目录下,改名为krb5.ini,内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25[libdefaults]
renew_lifetime = 7d
forwardable = true
default_realm = INDATA.COM
ticket_lifetime = 24h
dns_lookup_realm = false
dns_lookup_kdc = false
default_ccache_name = /tmp/krb5cc_%{uid}
#default_tgs_enctypes = aes des3-cbc-sha1 rc4 des-cbc-md5
#default_tkt_enctypes = aes des3-cbc-sha1 rc4 des-cbc-md5
[domain_realm]
indata.com = INDATA.COM
[logging]
default = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
kdc = FILE:/var/log/krb5kdc.log
[realms]
INDATA.COM = {
admin_server = indata-192.168.44.128.indata.com:17490
kdc = indata-192.168.44.128.indata.com
kdc = indata-192.168.44.129.indata.com
}
4、配置kerberos环境变量
KRB5_CONFIG:D:\program\company\kerberos\krb5.ini
KRB5CCNAME:D:\tmp\krb5cache
重启生效
5、验证keberos命令
将集群服务器上的keytab文件下载到本地,这里为D:\conf\inspur\hive.service.keytab,然后用下面的命令验证1
kinit -kt D:\conf\inspur\hive.service.keytab hive/indata-192.168.44.128.indata.com@INDATA.COM
我的报了下面的异常1
2
3
4
5Exception: too many parameters
java.lang.IllegalArgumentException: too many parameters
at sun.security.krb5.internal.tools.KinitOptions.<init>(KinitOptions.java:153)
at sun.security.krb5.internal.tools.Kinit.<init>(Kinit.java:147)
at sun.security.krb5.internal.tools.Kinit.main(Kinit.java:113)
一开始很奇怪,因为kinit命令就是这么用的,为啥会报参数过多呢,网上查资料发现,原来是jdk也自带了一个kinit命令,这里用的是jdk自带的kinit命令,需要再配置一下环境变量,在path里添加D:\program\company\kerberos\bin,需要注意的是要加在java的环境变量(%JAVA_HOME%\jre\bin)的前面。然后重试上面的命令,发现不报错了,用klist验证
1 | klist |
也可以在kerberos界面上查看,如下图:

注意:后面的用DBeaver连接Hive时,首先用kinit 命令进行缓存票据
6、配置DBeaver
在配置文件D:\program\company\dbeaver\dbeaver.ini最后添加1
2
3-Djavax.security.auth.useSubjectCredsOnly=false
-Djava.security.krb5.conf=D:\program\company\kerberos\krb5.ini
-Dsun.security.krb5.debug=true
注意-Djava.security.krb5.conf对应的值不要加引号””,网上很多教程都是加””,这样会导致DBeaver识别不到krb5.ini的配置文件,从而导致对kerberos的认证失败。这里坑了我很长时间,一直搞不清为啥认证失败。。。
7、连接Spark Thrift Server
首先启动Spark Thrift Server,关于怎么启动,参考https://dongkelun.com/2021/02/19/javaSparkThriftServer/
然后在Dbeaver里:新建->数据库连接->选择Hadoop-Spark Hive->输入主机IP、端口、数据库->然后编辑驱动设置,删除原来的驱动,添加这个项目的jar包https://github.com/dongkelun/java-spark-thrift-server-demo
其中这里的数据库为default;principal=HTTP/indata-192.168.44.128.indata.com@INDATA.COM?hive.server2.transport.mode=http;hive.server2.thrift.http.path=cliservice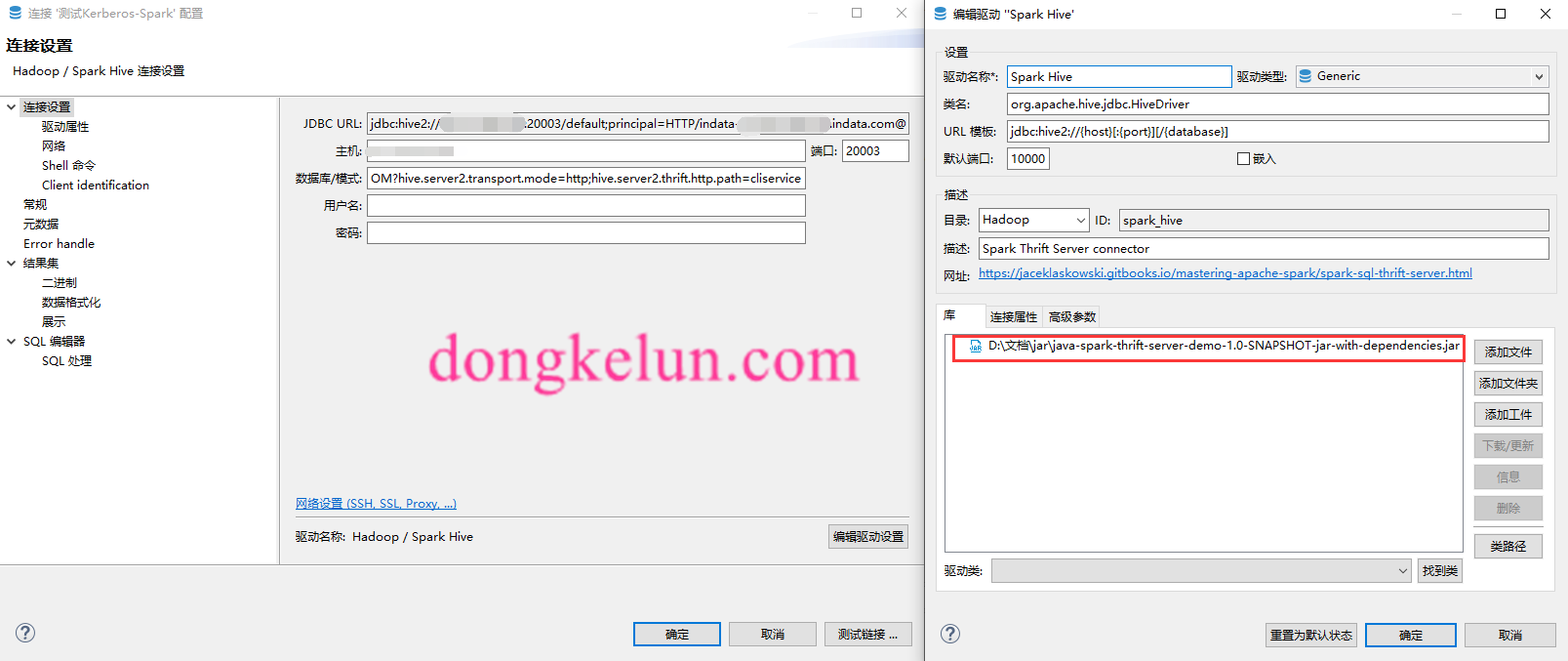
然后测试连接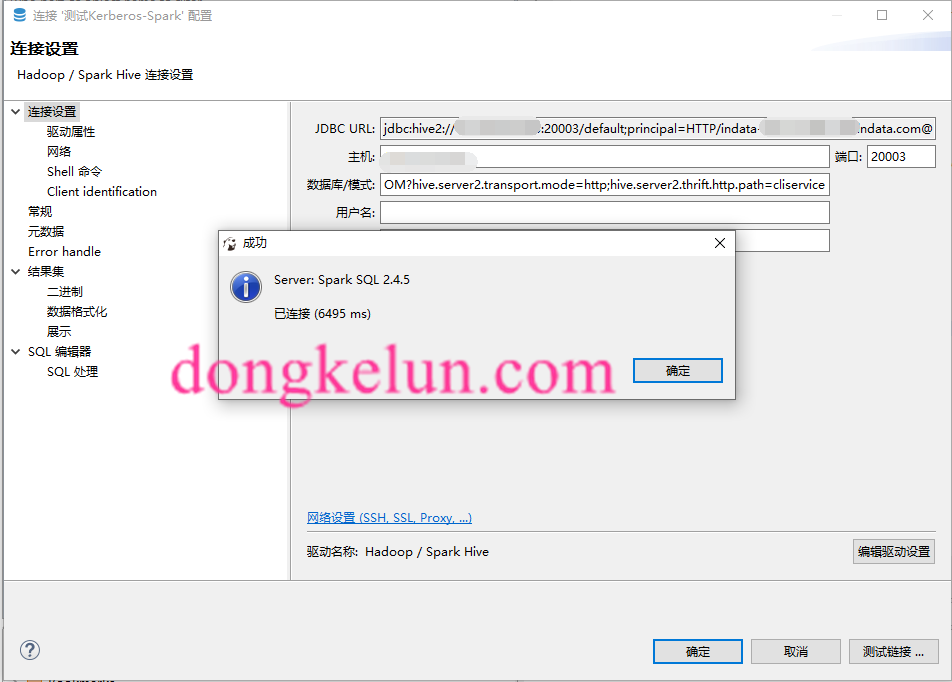
如果不成功,检查一下上述的配置
8、连接Hive Server
测试连接前先启动hive相关的服务,然后在Dbeaver里:新建->数据库连接->选择Hadoop-Spark Hive->输入主机IP、端口、数据库->然后编辑驱动设置,删除原来的驱动,添加这个项目的jar包https://github.com/dongkelun/java-spark-thrift-server-demo
其中这里的数据库为default;principal=hive/indata-192.168.44.128.indata.com@INDATA.COM

然后测试连接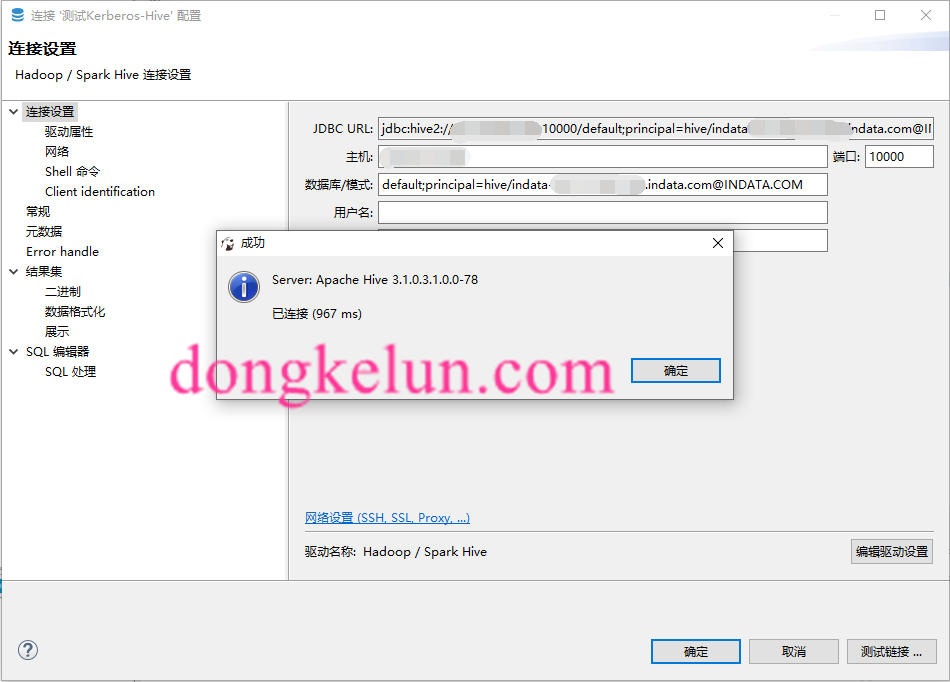
参考
- 使用DBeaver访问Kerberos环境下的Hive
- DBeaver实战之访问Kerberos环境下的Hive
- 新版DBeaver访问Kerberos环境下的Impala,详细配置过程,看完不会你打我!
相关阅读
- 通过数据库客户端界面工具DBeaver连接Hive
- Java 连接 Kereros认证下的Spark Thrift Server/Hive Server总结
- Spark 本地连接远程服务器上带有kerberos认证的Hive


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:通过DBeaver本地访问远程Kerberos环境下的Hive
本文链接:https://dongkelun.com/2021/06/03/dbeaverConnectKerberosHive/
欢迎关注我的公众号