
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

1、需求背景
通过Spark将关系型数据库(以Oracle为例)的表同步的Hive表,要求用Spark建表,有字段注释的也要加上注释。Spark建表,有两种方法:
- 用Spark Sql,在程序里组建表语句,然后用Spark.sql(“建表语句”)建表,这种方法麻烦的地方在于你要读取Oracle表的详细的表结构信息,且要进行Oracle和Hive的字段类型进行一一对应
- 用DataFrame 的saveAsTable方法,这种方法如果对应的数据库里没有表,则Spark会根据DataFrame的schema自动建表,比较简单,不用考虑字段类型匹配转化问题,但是这种方法有一个问题,Spark读取Oracle的表为DataFrame时,并不能将表字段的注释读进来,所以就有了如标题所示的需求。(一开始以为DataFrame不能加注释,经过研究,发现是可以的!)
2、如何查看DataFrame是否有注释
前面讲到DataFrame里没有Oracle的注释信息,但是如果数据源为Hive的话,是可以将注释获取到的。
2.1 新建Hive测试表(带注释)
1 | create table `test` ( |

2.2 Spark读取hive表并打印注释(在spark-shell里执行)
若不清楚Spark如何连接hive,可以参考:spark连接hive(spark-shell和eclipse两种方式)
首先看一下df.printSchema里并没有注释信息1
2
3sql("use test")
val df = spark.table("test")
df.printSchema1
2
3root
|-- id: string (nullable = true)
|-- name: string (nullable = true)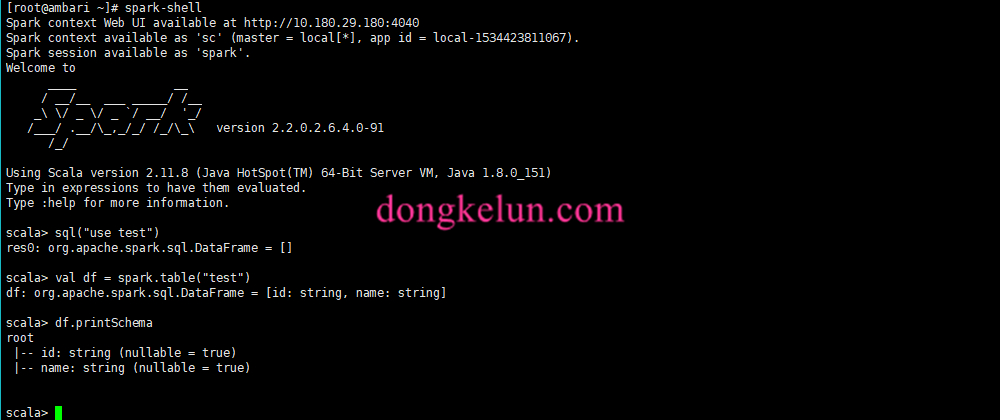
用下面这行代码便可以打印注释信息:1
df.schema.foreach(s=>println(s.name,s.metadata))
1
2(id,{"comment":"ID","HIVE_TYPE_STRING":"string"})
(name,{"comment":"名字","HIVE_TYPE_STRING":"string"})
3、读取Oracle表并打印DataFrmae的元数据信息
3.1 新建Oracle测试表(带注释)
1 | CREATE TABLE ORA_TEST ( |
- 注:上面的注释语句和建表语句需要分开执行,或者也可以在数据库工具执行脚本,比如我用的DBeaver用快捷键Alt+x即可。当然也可以在工具的界面直接建表均可。

3.2 读取Oracle表,并打印元数据
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21package com.dkl.leanring.spark.sql.Oracle
import org.apache.spark.sql.SparkSession
object OracleSchemaDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("OracleSchemaDemo").master("local").getOrCreate()
val df = spark.read
.format("jdbc")
.option("url", "jdbc:oracle:thin:@192.168.44.128:1521:orcl")
.option("dbtable", "ORA_TEST")
.option("user", "bigdata")
.option("password", "bigdata")
.option("driver", "oracle.jdbc.driver.OracleDriver")
.load()
df.schema.foreach(s => println(s.name, s.metadata))
spark.stop
}
}1
2(ID,{"name":"ID","scale":0})
(NAME,{"name":"NAME","scale":0})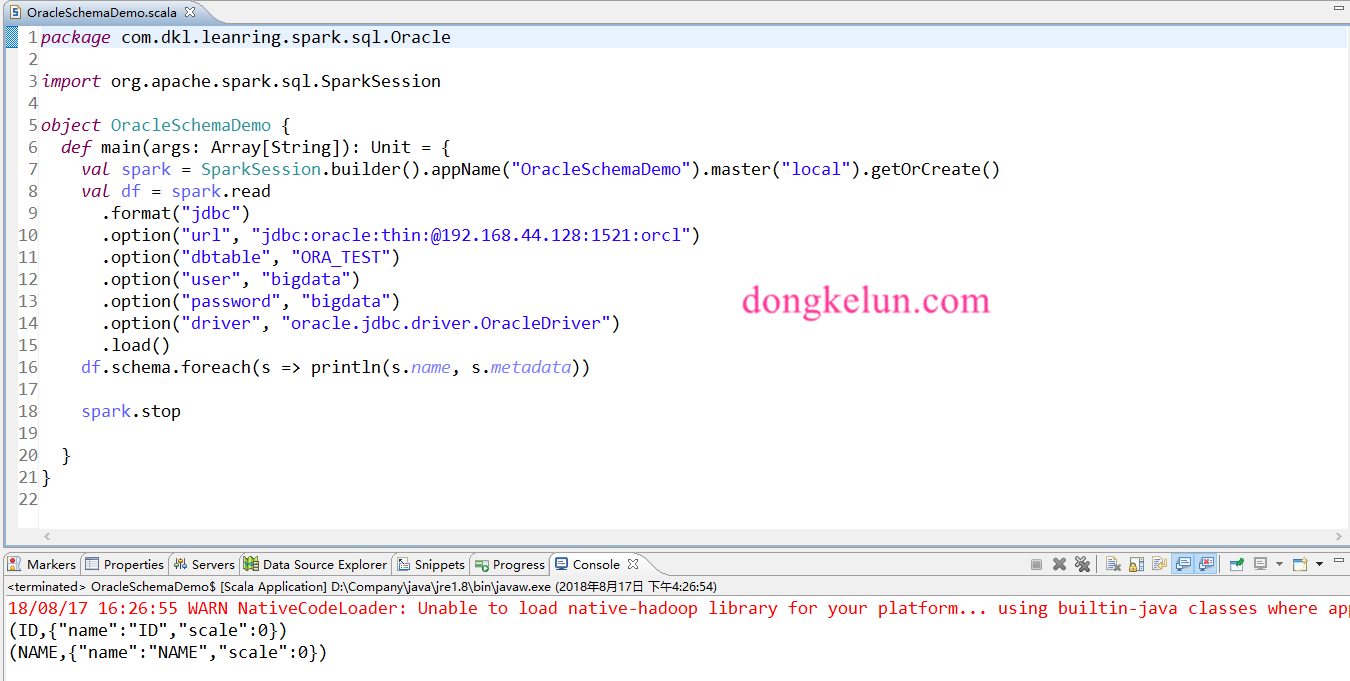
注:Spark2.3.0和Spark2.2.1的元数据不太一样,上面的结果是Spark2.2.1(也是我写博客测试用的),项目中用的Spark2.3.0,2.3.0的元数据是空的,如下1
2(ID,{})
(NAME,{})
可见并没有注释信息
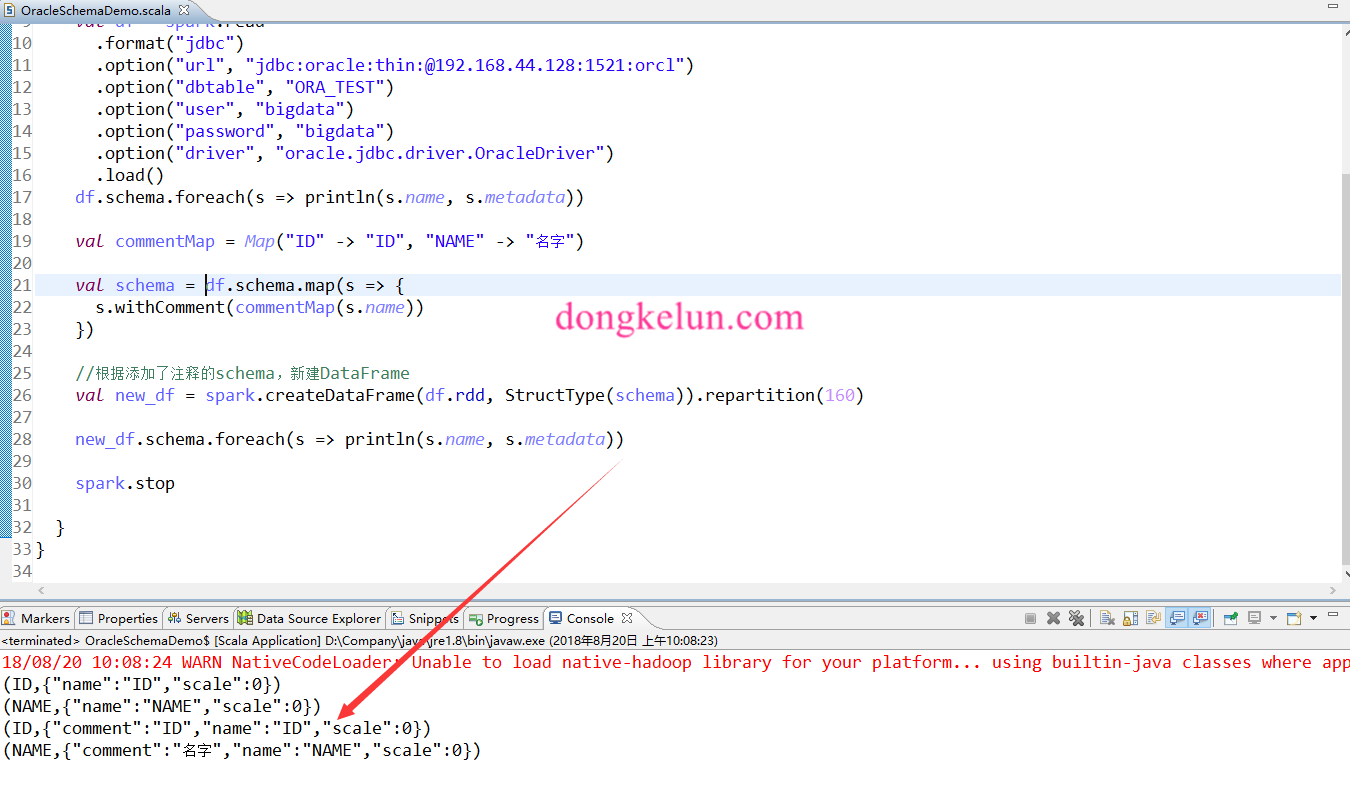
3.3 给DataFrame添加注释
1 | import org.apache.spark.sql.types._ |
1 | (ID,{"comment":"ID","name":"ID","scale":0}) |
4、 测试写到Hive表有没有注释
需将前面代码中的spark改为支持hive,即加上enableHiveSupport()1
2spark.sql("use test")
new_df.write.mode("overwrite").saveAsTable("ORA_TEST")
然后在hive里看一下,是否有注释
可以看到,成功的把注释也保存到里hive里
5、附录
附上在Eclipse运行的完整代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
package com.dkl.leanring.spark.sql.Oracle
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
object OracleSchemaDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("OracleSchemaDemo").master("local").enableHiveSupport().getOrCreate()
val df = spark.read
.format("jdbc")
.option("url", "jdbc:oracle:thin:@192.168.44.128:1521:orcl")
.option("dbtable", "ORA_TEST")
.option("user", "bigdata")
.option("password", "bigdata")
.option("driver", "oracle.jdbc.driver.OracleDriver")
.load()
df.schema.foreach(s => println(s.name, s.metadata))
val commentMap = Map("ID" -> "ID", "NAME" -> "名字")
val schema = df.schema.map(s => {
s.withComment(commentMap(s.name))
})
//根据添加了注释的schema,新建DataFrame
val new_df = spark.createDataFrame(df.rdd, StructType(schema)).repartition(160)
new_df.schema.foreach(s => println(s.name, s.metadata))
spark.sql("use test")
//保存到hive
new_df.write.mode("overwrite").saveAsTable("ORA_TEST")
spark.stop
}
}


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Spark通过修改DataFrame的schema给表字段添加注释
本文链接:https://dongkelun.com/2018/08/20/sparkDfAddComments/
欢迎关注我的公众号