
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
本文利用SparkStreaming和Kafka实现基于缓存的实时wordcount程序,什么意思呢,因为一般的SparkStreaming的wordcount程序比如官网上的,只能统计最新时间间隔内的每个单词的数量,而不能将历史的累加起来,本文是看了教程之后,自己实现了一下kafka的程序,记录在这里。其实没什么难度,只是用了一个updateStateByKey算子就能实现,因为第一次用这个算子,所以正好学习一下。
1、数据
数据是我随机在kafka里生产的几条,单词以空格区分开
2、kafka topic
首先在kafka建一个程序用到topic:UpdateStateBykeyWordCount1
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic UpdateStateBykeyWordCount
3、创建checkpoint的hdfs目录
我的目录为:/spark/dkl/kafka/wordcount_checkpoint1
hadoop fs -mkdir -p /spark/dkl/kafka/wordcount_checkpoint
4、Spark代码
启动下面的程序1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61package com.dkl.leanring.spark.kafka
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.Seconds
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object UpdateStateBykeyWordCount {
def main(args: Array[String]): Unit = {
//初始化,创建SparkSession
val spark = SparkSession.builder().appName("sskt").master("local[2]").enableHiveSupport().getOrCreate()
//初始化,创建sparkContext
val sc = spark.sparkContext
//初始化,创建StreamingContext,batchDuration为1秒
val ssc = new StreamingContext(sc, Seconds(5))
//开启checkpoint机制
ssc.checkpoint("hdfs://ambari.master.com:8020/spark/dkl/kafka/wordcount_checkpoint")
//kafka集群地址
val server = "ambari.master.com:6667"
//配置消费者
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> server, //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "UpdateStateBykeyWordCount", //消费者组名
"auto.offset.reset" -> "latest", //latest自动重置偏移量为最新的偏移量 earliest 、none
"enable.auto.commit" -> (false: java.lang.Boolean)) //如果是true,则这个消费者的偏移量会在后台自动提交
val topics = Array("UpdateStateBykeyWordCount") //消费主题
//基于Direct方式创建DStream
val stream = KafkaUtils.createDirectStream(ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams))
//开始执行WordCount程序
//以空格为切分符切分单词,并转化为 (word,1)形式
val words = stream.flatMap(_.value().split(" ")).map((_, 1))
val wordCounts = words.updateStateByKey(
//每个单词每次batch计算的时候都会调用这个函数
//第一个参数为每个key对应的新的值,可能有多个,比如(hello,1)(hello,1),那么values为(1,1)
//第二个参数为这个key对应的之前的状态
(values: Seq[Int], state: Option[Int]) => {
var newValue = state.getOrElse(0)
values.foreach(newValue += _)
Option(newValue)
})
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
5、生产几条数据
随便写几条即可
1 | bin/kafka-console-producer.sh --broker-list ambari.master.com:6667 --topic UpdateStateBykeyWordCount |
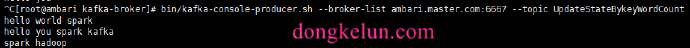
6、结果
根据结果可以看到,历史的单词也被统计打印出来了


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:SparkStreaming+Kafka 实现基于缓存的实时wordcount程序
本文链接:https://dongkelun.com/2018/06/14/updateStateBykeyWordCount/
欢迎关注我的公众号