
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
本文总结了Spark架构原理,其中主要包括五个组件:Driver、Master、Worker、Executor和Task,简要概括了每个组件是干啥的,并总结提交spark程序之后,这五个组件运行的详细步骤。
1、流程图
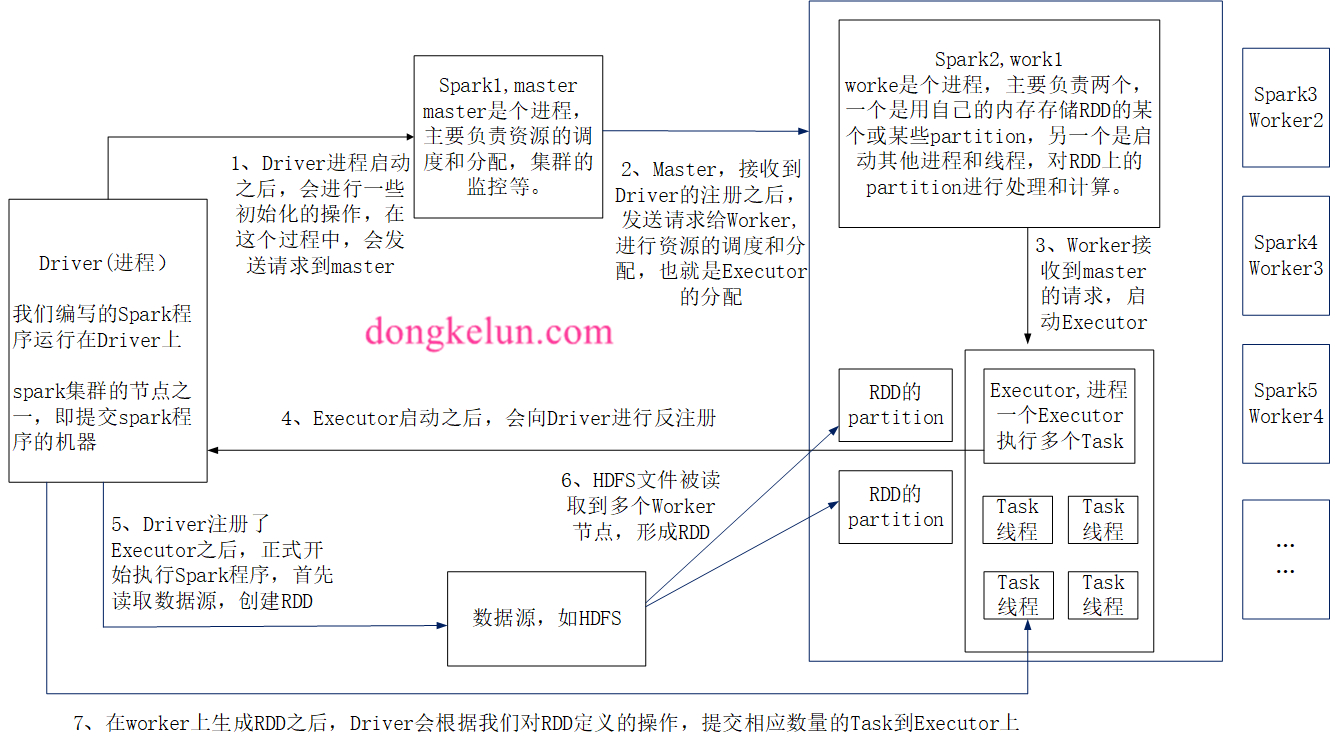
2、Driver
driver是一个进程,我们编写的spark程序运行在driver上,由dirver进程执行,driver是作业的主进程,具有main函数,是程序的入口点,driver进程启动后,向master发送请求,进行注册,申请资源,在后面的executor启动后,会向dirver进行反注册,dirver注册了executor后,正式执行spark程序,读取数据源,创建rdd或dataframe,生成stage,提交task到executor
3、Master
Master是个进程,主要负责资源的调度和分配,集群的监控等。
4、Worker
worke是个进程,主要负责两个,一个是用自己的内存存储RDD的某个或某些partition,另一个是启动其他进程和线程,对RDD上的partition进行处理和计算。
5、Executor
Executor是个进程,一个Executor执行多个Task,多个Executor可以并行执行,可以通过–num-executors来指定Executor的数量,但是经过我的测试,Executor最大为集群可用的cpu核数减1,另一个core可能是用来作为master,另外如果master为yarn,则实际可用cpu核数为yarn的虚拟核数,可以通过yarn.nodemanager.resource.cpu-vcores设定,虚拟核数可以大于物理核数。
6、Task
Task是个线程,具体的spark任务是在Task上运行的,某些并行的算子,有多少个分区就有多少个task,但是有些算子像take这样的只有一个task。
7、详细的流程
1、Driver进程启动之后,会进行一些初始化的操作,在这个过程中,会发送请求到master
2、Master,接收到Driver的注册之后,发送请求给Worker,进行资源的调度和分配,也就是Executor的分配
3、Worker接收到master的请求,启动Executor
4、Executor启动之后,会向Driver进行反注册
5、Driver注册了Executor之后,正式开始执行Spark程序,首先读取数据源,创建RDD
6、HDFS文件被读取到多个Worker节点,形成RDD
7、在worker上生成RDD之后,Driver会根据我们对RDD定义的操作,提交相应数量的Task到Executor上


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Spark架构原理
本文链接:https://dongkelun.com/2018/06/09/sparkArchitecturePrinciples/
欢迎关注我的公众号