
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
ogg即Oracle GoldenGate是Oracle的同步工具,本文讲如何配置ogg以实现Oracle数据库增量数据实时同步到kafka中,其中同步消息格式为json。
下面是我的源端和目标端的一些配置信息:
| 版本 | OGG版本 | ip | 别名 | |
|---|---|---|---|---|
| 源端 | OracleRelease 11.2.0.1.0 | Oracle GoldenGate 11.2.1.0.3 for Oracle on Linux x86-64 | 192.168.44.128 | master |
| 目标端 | kafka_2.11-1.1.0 | Oracle GoldenGate for Big Data 12.3.1.1.1 on Linux x86-64 | 192.168.44.129 | slave1 |
1、下载
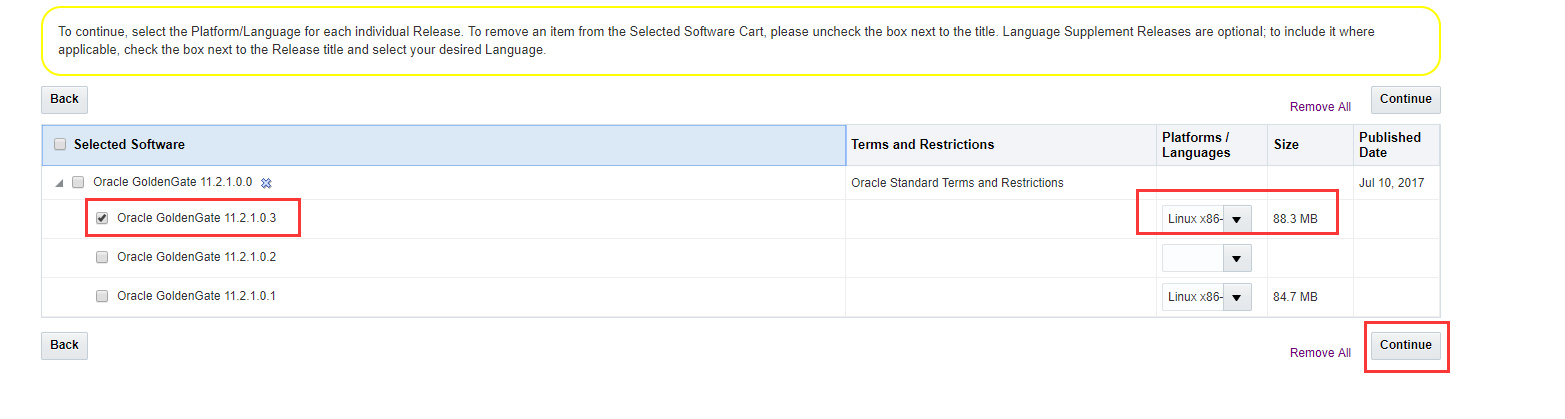
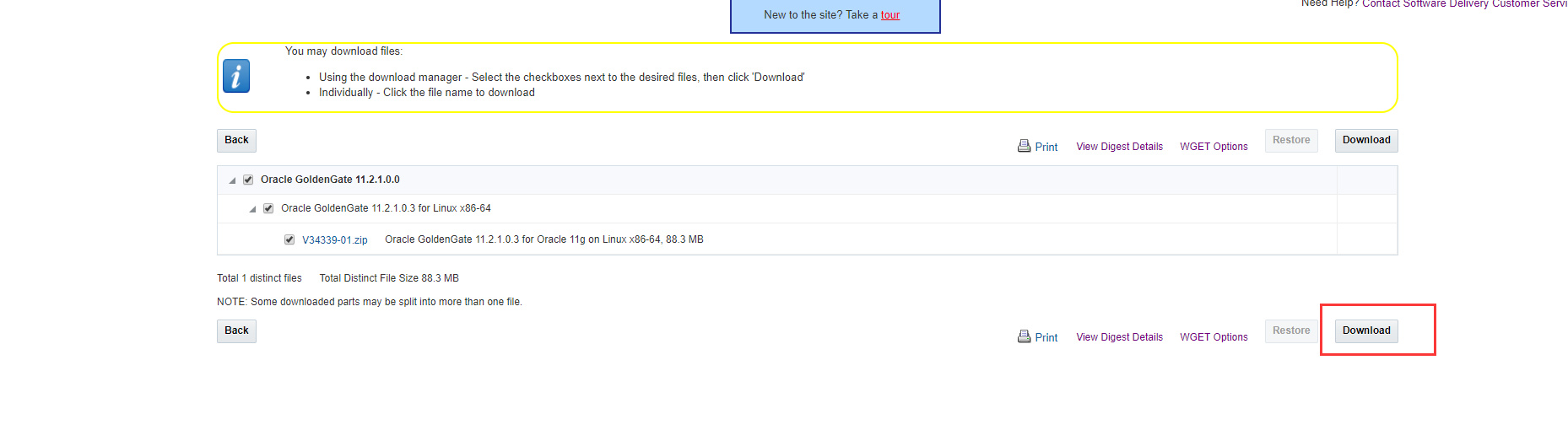
可在这里或旧版本查询下载
注意:源端和目标端的文件不一样,目标端需要下载Oracle GoldenGate for Big Data,源端需要下载Oracle GoldenGate for Oracle具体下载方法见最后的附录截图。
2、源端(Oracle)配置
注意:源端是安装了oracle的机器,oracle环境变量之前都配置好了
2.1 解压
先建立ogg目录1
2mkdir -p /opt/ogg
unzip V34339-01.zip
解压后得到一个tar包,再解压这个tar1
2tar xf fbo_ggs_Linux_x64_ora11g_64bit.tar -C /opt/ogg
chown -R oracle:oinstall /opt/ogg (使oracle用户有ogg的权限,后面有些需要在oracle用户下执行才能成功)
2.2 配置ogg环境变量
为了简单方便起见,我在/etc/profile里配置的,建议在生产中配置oracle的环境变量文件/home/oracle/.bash_profile里配置,为了怕出问题,我把OGG_HOME等环境变量在/etc/profile配置了一份,不知道这是否是必须的。1
vim /etc/profile
1 | export OGG_HOME=/opt/ogg |
使之生效1
source /etc/profile
测试一下ogg命令1
ggsci
如果命令成功即可进行下一步,不成功请检查前面的步骤。
2.3 oracle打开归档模式
1 | su - oracle |
执行下面的命令查看当前是否为归档模式1
archive log list
1 | SQL> archive log list |
若为Disabled,手动打开即可1
2
3
4
5
6conn / as sysdba (以DBA身份连接数据库)
shutdown immediate (立即关闭数据库)
startup mount (启动实例并加载数据库,但不打开)
alter database archivelog; (更改数据库为归档模式)
alter database open; (打开数据库)
alter system archive log start; (启用自动归档)
再执行一下1
archive log list
1 | Database log mode Archive Mode |
可以看到为Enabled,则成功打开归档模式。
2.4 Oracle打开日志相关
OGG基于辅助日志等进行实时传输,故需要打开相关日志确保可获取事务内容,通过下面的命令查看该状态1
select force_logging, supplemental_log_data_min from v$database;
1 | FORCE_ SUPPLEMENTAL_LOG |
若为NO,则需要通过命令修改1
2alter database force logging;
alter database add supplemental log data;
再查看一下为YES即可1
2
3
4
5SQL> select force_logging, supplemental_log_data_min from v$database;
FORCE_ SUPPLEMENTAL_LOG
------ ----------------
YES YES
2.5 oracle创建复制用户
首先root用户建立相关文件夹,并赋予权限1
2mkdir -p /u01/app/oracle/oggdata/orcl
chown -R oracle:oinstall /u01/app/oracle/oggdata/orcl
然后执行下面sql1
2
3
4
5
6
7
8
9
10
11SQL> create tablespace oggtbs datafile '/u01/app/oracle/oggdata/orcl/oggtbs01.dbf' size 1000M autoextend on;
Tablespace created.
SQL> create user ogg identified by ogg default tablespace oggtbs;
User created.
SQL> grant dba to ogg;
Grant succeeded.
2.6 OGG初始化
1 | ggsci |
1 | ggsci |
2.7 Oracle创建测试表
创建一个用户,在该用户下新建测试表,用户名、密码、表名均为 test_ogg。1
2
3
4create user test_ogg identified by test_ogg default tablespace users;
grant dba to test_ogg;
conn test_ogg/test_ogg;
create table test_ogg(id int ,name varchar(20),primary key(id));
3 目标端(kafka)配置
1 | mkdir -p /opt/ogg |
3.2 环境变量
1 | vim /etc/profile |
1 | export OGG_HOME=/opt/ogg |
1 | source /etc/profile |
同样测试一下ogg命令1
ggsci
3.3 初始化目录
1 | create subdirs |
4、OGG源端配置
4.1 配置OGG的全局变量
先切换到oracle用户下1
2
3su oracle
cd /opt/ogg
ggsci
1 | GGSCI (ambari.master.com) 1> dblogin userid ogg password ogg |
然后和用vim编辑一样添加1
oggschema ogg
4.2 配置管理器mgr
1 | GGSCI (ambari.master.com) 3> edit param mgr |
说明:PORT即mgr的默认监听端口;DYNAMICPORTLIST动态端口列表,当指定的mgr端口不可用时,会在这个端口列表中选择一个,最大指定范围为256个;AUTORESTART重启参数设置表示重启所有EXTRACT进程,最多5次,每次间隔3分钟;PURGEOLDEXTRACTS即TRAIL文件的定期清理
4.3 添加复制表
1 | GGSCI (ambari.master.com) 4> add trandata test_ogg.test_ogg |
4.4 配置extract进程
1 | GGSCI (ambari.master.com) 6> edit param extkafka |
说明:第一行指定extract进程名称;dynamicresolution动态解析;SETENV设置环境变量,这里分别设置了Oracle数据库以及字符集;userid ggs,password ggs即OGG连接Oracle数据库的帐号密码,这里使用2.5中特意创建的复制帐号;exttrail定义trail文件的保存位置以及文件名,注意这里文件名只能是2个字母,其余部分OGG会补齐;table即复制表的表名,支持*通配,必须以;结尾
添加extract进程:
1 | GGSCI (ambari.master.com) 16> add extract extkafka,tranlog,begin now |
(注:若报错1
ERROR: Could not create checkpoint file /opt/ogg/dirchk/EXTKAFKA.cpe (error 2, No such file or directory).
执行下面的命令再重新添加即可。1
create subdirs
)
添加trail文件的定义与extract进程绑定:
1 | GGSCI (ambari.master.com) 17> add exttrail /opt/ogg/dirdat/to,extract extkafka |
4.5 配置pump进程
pump进程本质上来说也是一个extract,只不过他的作用仅仅是把trail文件传递到目标端,配置过程和extract进程类似,只是逻辑上称之为pump进程1
2
3
4
5
6
7
8GGSCI (ambari.master.com) 18> edit param pukafka
extract pukafka
passthru
dynamicresolution
userid ogg,password ogg
rmthost 192.168.44.129 mgrport 7809
rmttrail /opt/ogg/dirdat/to
table test_ogg.test_ogg;
说明:第一行指定extract进程名称;passthru即禁止OGG与Oracle交互,我们这里使用pump逻辑传输,故禁止即可;dynamicresolution动态解析;userid ogg,password ogg即OGG连接Oracle数据库的帐号密码rmthost和mgrhost即目标端(kafka)OGG的mgr服务的地址以及监听端口;rmttrail即目标端trail文件存储位置以及名称。
分别将本地trail文件和目标端的trail文件绑定到extract进程:1
2
3
4GGSCI (ambari.master.com) 1> add extract pukafka,exttrailsource /opt/ogg/dirdat/to
EXTRACT added.
GGSCI (ambari.master.com) 2> add rmttrail /opt/ogg/dirdat/to,extract pukafka
RMTTRAIL added.
4.6 配置define文件
Oracle与MySQL,Hadoop集群(HDFS,Hive,kafka等)等之间数据传输可以定义为异构数据类型的传输,故需要定义表之间的关系映射,在OGG命令行执行:1
2
3
4GGSCI (ambari.master.com) 3> edit param test_ogg
defsfile /opt/ogg/dirdef/test_ogg.test_ogg
userid ogg,password ogg
table test_ogg.test_ogg;
在OGG主目录下执行(oracle用户):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37./defgen paramfile dirprm/test_ogg.prm
***********************************************************************
Oracle GoldenGate Table Definition Generator for Oracle
Version 11.2.1.0.3 14400833 OGGCORE_11.2.1.0.3_PLATFORMS_120823.1258
Linux, x64, 64bit (optimized), Oracle 11g on Aug 23 2012 16:58:29
Copyright (C) 1995, 2012, Oracle and/or its affiliates. All rights reserved.
Starting at 2018-05-23 05:03:04
***********************************************************************
Operating System Version:
Linux
Version #1 SMP Wed Apr 12 15:04:24 UTC 2017, Release 3.10.0-514.16.1.el7.x86_64
Node: ambari.master.com
Machine: x86_64
soft limit hard limit
Address Space Size : unlimited unlimited
Heap Size : unlimited unlimited
File Size : unlimited unlimited
CPU Time : unlimited unlimited
Process id: 13126
***********************************************************************
** Running with the following parameters **
***********************************************************************
defsfile /opt/ogg/dirdef/test_ogg.test_ogg
userid ogg,password ***
table test_ogg.test_ogg;
Retrieving definition for TEST_OGG.TEST_OGG
Definitions generated for 1 table in /opt/ogg/dirdef/test_ogg.test_ogg
将生成的/opt/ogg/dirdef/test_ogg.test_ogg发送的目标端ogg目录下的dirdef里:1
scp -r /opt/ogg/dirdef/test_ogg.test_ogg root@slave1:/opt/ogg/dirdef/
5、OGG目标端配置
5.1 开启kafka服务
1 | cd /opt/kafka_2.11-1.1.0/ |
5.2 配置管理器mgr
1 | GGSCI (ambari.slave1.com) 1> edit param mgr |
5.3 配置checkpoint
checkpoint即复制可追溯的一个偏移量记录,在全局配置里添加checkpoint表即可。1
2edit param ./GLOBALS
CHECKPOINTTABLE test_ogg.checkpoint
5.4 配置replicate进程
1 | GGSCI (ambari.slave1.com) 4> edit param rekafka |
说明:REPLICATE rekafka定义rep进程名称;sourcedefs即在4.6中在源服务器上做的表映射文件;TARGETDB LIBFILE即定义kafka一些适配性的库文件以及配置文件,配置文件位于OGG主目录下的dirprm/kafka.props;REPORTCOUNT即复制任务的报告生成频率;GROUPTRANSOPS为以事务传输时,事务合并的单位,减少IO操作;MAP即源端与目标端的映射关系
5.5 配置kafka.props
1 | cd /opt/ogg/dirprm/ |
1 | gg.handlerlist=kafkahandler //handler类型 |
1 | vim custom_kafka_producer.properties |
1 | bootstrap.servers=192.168.44.129:9092 //kafkabroker的地址 |
其中需要将后面的注释去掉,ogg不识别注释,如果不去掉会报错
5.6 添加trail文件到replicate进程
1 | GGSCI (ambari.slave1.com) 2> add replicat rekafka exttrail /opt/ogg/dirdat/to,checkpointtable test_ogg.checkpoint |
6、测试
6.1 启动所有进程
在源端和目标端的OGG命令行下使用start [进程名]的形式启动所有进程。
启动顺序按照源mgr——目标mgr——源extract——源pump——目标replicate来完成。
全部需要在ogg目录下执行ggsci目录进入ogg命令行。
源端依次是1
2
3start mgr
start extkafka
start pukafka
目标端1
2start mgr
start rekafka
可以通过info all 或者info [进程名] 查看状态,所有的进程都为RUNNING才算成功
源端1
2
3
4
5
6
7GGSCI (ambari.master.com) 5> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT RUNNING EXTKAFKA 04:50:21 00:00:03
EXTRACT RUNNING PUKAFKA 00:00:00 00:00:03
目标端1
2
3
4
5
6GGSCI (ambari.slave1.com) 3> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT RUNNING REKAFKA 00:00:00 00:00:01
6.2 异常解决
如果有不是RUNNING可通过查看日志的方法检查解决问题,具体通过下面两种方法1
vim ggser.log
或者ogg命令行,以rekafka进程为例
1 | GGSCI (ambari.slave1.com) 2> view report rekafka |
列举其中我遇到的一个问题:
异常信息1
2
3SEVERE: Unable to set property on handler 'kafkahandler' (oracle.goldengate.handler.kafka.KafkaHandler). Failed to set property: TopicName:="test_ogg" (class: oracle.goldengate.handler.kafka.KafkaHandler).
oracle.goldengate.util.ConfigException: Failed to set property: TopicName:="test_ogg" (class: oracle.goldengate.handler.kafka.KafkaHandler).
at ......
具体原因是网上的教程是旧版的,设置topicName的属性为:1
gg.handler.kafkahandler.topicName=test_ogg
新版的这样设置1
gg.handler.kafkahandler.topicMappingTemplate=test_ogg
大家可根据自己的版本进行设置,附上stackoverflow原答案1
2
3
4
5
6
7
8I tried to move data from Oracle Database to Kafka using Golden gate adapter Version 12.3.0.1.0
In new version there is no topicname
The following resolves the topic name using the short table name
gg.handler.kafkahandler.topicMappingTemplate=test
In previous version we have gg.handler.kafkahandler.topicName=test
6.3 测试同步更新效果
现在源端执行sql语句1
2
3
4
5
6
7conn test_ogg/test_ogg
insert into test_ogg values(1,'test');
commit;
update test_ogg set name='zhangsan' where id=1;
commit;
delete test_ogg where id=1;
commit;
查看源端trail文件状态1
2ls -l /opt/ogg/dirdat/to*
-rw-rw-rw- 1 oracle oinstall 1464 May 23 10:31 /opt/ogg/dirdat/to000000
查看目标端trail文件状态1
2ls -l /opt/ogg/dirdat/to*
-rw-r----- 1 root root 1504 May 23 10:31 /opt/ogg/dirdat/to000000
查看kafka是否自动建立对应的主题1
bin/kafka-topics.sh --list --zookeeper localhost:2181
在列表中显示有test_ogg则表示没问题
通过消费者看是否有同步消息1
2
3
4bin/kafka-console-consumer.sh --bootstrap-server 192.168.44.129:9092 --topic test_ogg --from-beginning
{"table":"TEST_OGG.TEST_OGG","op_type":"I","op_ts":"2018-05-23 10:31:28.000078","current_ts":"2018-05-23T10:36:48.525000","pos":"00000000000000001093","after":{"ID":1,"NAME":"test"}}
{"table":"TEST_OGG.TEST_OGG","op_type":"U","op_ts":"2018-05-23 10:31:36.000073","current_ts":"2018-05-23T10:36:48.874000","pos":"00000000000000001233","before":{},"after":{"ID":1,"NAME":"zhangsan"}}
{"table":"TEST_OGG.TEST_OGG","op_type":"D","op_ts":"2018-05-23 10:31:43.000107","current_ts":"2018-05-23T10:36:48.875000","pos":"00000000000000001376","before":{"ID":1}}
显然,Oracle的数据已准实时同步到Kafka,格式为json,其中op_type代表操作类型,这个可配置,我没有配置则按默认的来,默认为1
2
3gg.handler.kafkahandler.format.insertOpKey = I
gg.handler.kafkahandler.format.updateOpKey = U
gg.handler.kafkahandler.format.deleteOpKey = D
before代表操作之前的数据,after代表操作后的数据,现在已经可以从kafka获取到同步的json数据了,后面可以用SparkStreaming和Storm等解析然后存到hadoop等大数据平台里
6.4 SparkStreaming测试消费同步消息
具体代码可参考Spark Streaming连接Kafka入门教程
下面附上消费成功的结果图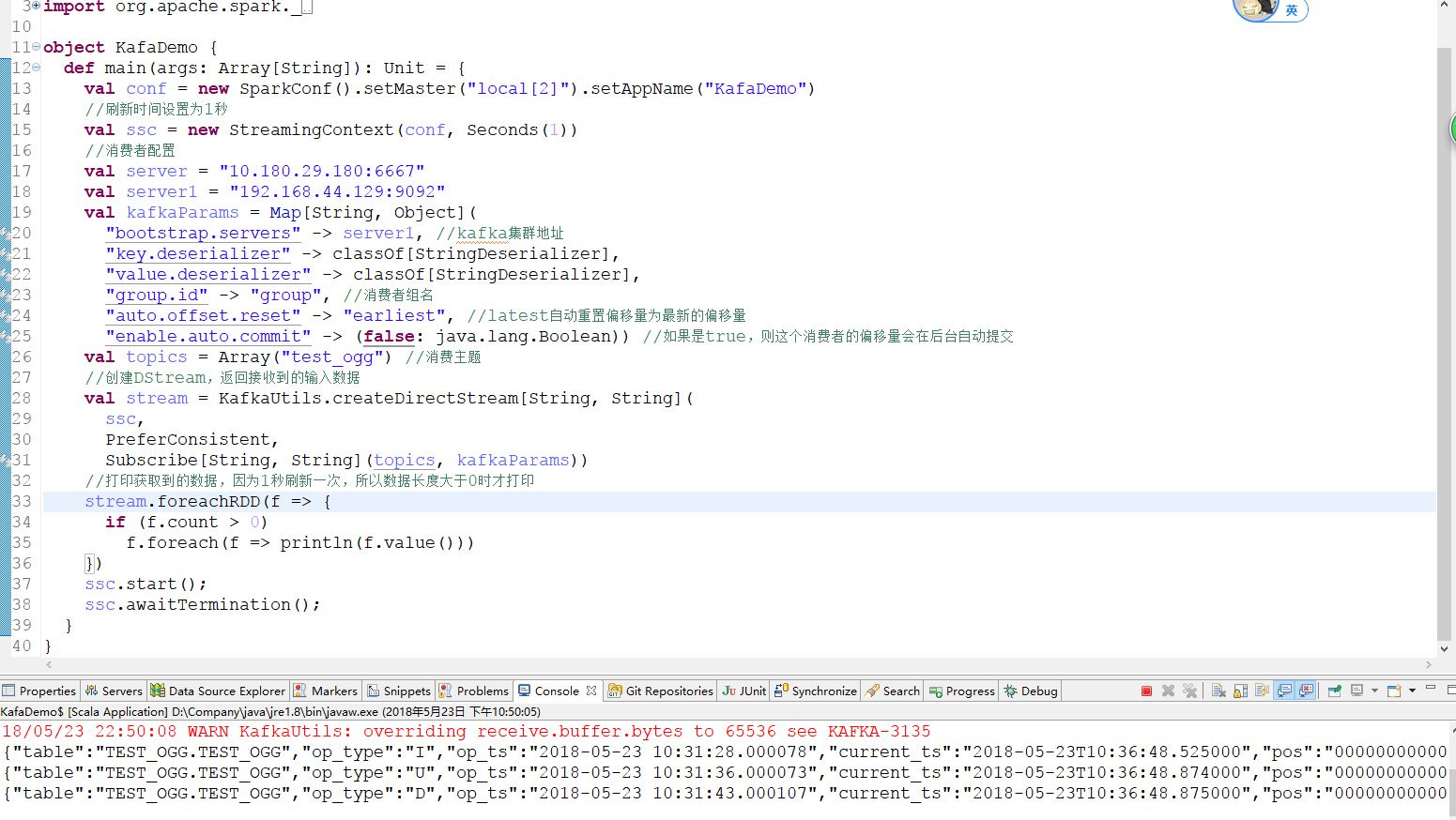
7、更新:后续遇到的问题
在后面的使用过程中发现上面同步到kafka的json数据中少一些我们想要的一些,下面讲一下我是如何解决的
首先建表:1
2
3
4
5
6
7
8
9CREATE TABLE "TCLOUD"."T_OGG2"
( "ID" NUMBER(*,0),
"TEXT_NAME" VARCHAR2(20),
"AGE" NUMBER(*,0),
"ADD" VARCHAR2(100),
"IDD" VARCHAR2(100),
CONSTRAINT "T_OGG2_PK" PRIMARY KEY ("ID", "IDD")
)
为什么不用之前建的表,主要是之前的字段太少,不容易看出问题,现在主要是增加几个字段,然后id,idd是联合主键。
看一下按照之前的配置,同步到kafka的数据(截取部分数据)1
2
3
4
5{"table":"TCLOUD.T_OGG2","op_type":"I","op_ts":"2018-05-31 11:46:09.512672","current_ts":"2018-05-31T11:46:15.292000","pos":"00000000000000001903","after":{"ID":4,"TEXT_NAME":null,"AGE":0,"ADD":null,"IDD":"8"}}
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 11:49:10.514549","current_ts":"2018-05-31T11:49:16.450000","pos":"00000000000000002227","before":{},"after":{"ID":4,"TEXT_NAME":"lisi","IDD":"7"}}
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 11:49:48.514869","current_ts":"2018-05-31T11:49:54.481000","pos":"00000000000000002373","before":{"ID":4,"IDD":"7"},"after":{"ID":1,"IDD":"7"}}
{"table":"TCLOUD.T_OGG2","op_type":"D","op_ts":"2018-05-31 11:52:38.516877","current_ts":"2018-05-31T11:52:45.633000","pos":"00000000000000003161","before":{"ID":1,"IDD":"7"}}
现在只有insert的数据是全的,update更新非主键字段before是没有数据的,更新主键before只有主键的数据,delete只有before的主键字段,也就是update和delete的信息是不全的,且没有主键信息(程序里是不能判断哪一个是主键的),这样对于程序自动解析同步数据是不利的(不同的需求可能不一样),具体自己可以分析,就不啰嗦了,这里主要解决,有需要before和after全部信息和主键信息的需求。
7.1 添加before
在源端extract里添加下面几行1
2
3
4GGSCI (ambari.master.com) 33> edit param extkafka
GETUPDATEBEFORES
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
重启 extkafka1
2stop extkafka
start extkafka
然后测试1
2
3{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 14:48:55.630340","current_ts":"2018-05-31T14:49:01.709000","pos":"00000000000000003770","before":{"ID":1,"AGE":20,"IDD":"1"},"after":{"ID":1,"AGE":1,"IDD":"1"}}
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 14:48:55.630340","current_ts":"2018-05-31T14:49:01.714000","pos":"00000000000000004009","before":{"ID":1,"AGE":20,"IDD":"2"},"after":{"ID":1,"AGE":1,"IDD":"2"}}
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 14:48:55.630340","current_ts":"2018-05-31T14:49:01.715000","pos":"00000000000000004248","before":{"ID":1,"AGE":20,"IDD":"8"},"after":{"ID":1,"AGE":1,"IDD":"8"}}
发现update之后before里有数据即可,但是现在before和after的数据都不全(只有部分字段)
网上有的说只添加GETUPDATES即可,但我测试了没有成功,关于每个配置项什么含义可以参考https://blog.csdn.net/linucle/article/details/13505939(有些配置的含义里面也没有给出)
参考:http://www.itpub.net/thread-2083473-1-1.html
7.2 添加主键
在kafka.props添加
1 | gg.handler.kafkahandler.format.includePrimaryKeys=true |
重启 rekafka1
2stop rekafka
start rekafka
测试:1
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 14:58:57.637035","current_ts":"2018-05-31T14:59:03.401000","pos":"00000000000000004510","primary_keys":["ID","IDD"],"before":{"ID":1,"AGE":1,"IDD":"1"},"after":{"ID":1,"AGE":20,"IDD":"1"}}
发现有primary_keys,不错~
参考:http://blog.51cto.com/lyzbg/2088409
7.3 补全全部字段
如果字段补全应该是Oracle没有开启全列补充日志1
2
3
4
5SQL> select supplemental_log_data_all from v$database;
SUPPLE
------
NO
通过以下命令开启1
2
3
4
5
6
7
8
9
10
11SQL> alter database add supplemental log data(all) columns;
Database altered.
SQL> select supplemental_log_data_all from v$database;
SUPPLE
------
YES
SQL>
测试一下1
2
3{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 15:27:45.655518","current_ts":"2018-05-31T15:27:52.891000","pos":"00000000000000006070","primary_keys":["ID","IDD"],"before":{"ID":1,"TEXT_NAME":null,"AGE":1,"ADD":null,"IDD":"1"},"after":{"ID":1,"TEXT_NAME":null,"AGE":20,"ADD":null,"IDD":"1"}}
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 15:27:45.655518","current_ts":"2018-05-31T15:27:52.893000","pos":"00000000000000006341","primary_keys":["ID","IDD"],"before":{"ID":1,"TEXT_NAME":null,"AGE":1,"ADD":null,"IDD":"2"},"after":{"ID":1,"TEXT_NAME":null,"AGE":20,"ADD":null,"IDD":"2"}}
{"table":"TCLOUD.T_OGG2","op_type":"U","op_ts":"2018-05-31 15:27:45.655518","current_ts":"2018-05-31T15:27:52.895000","pos":"00000000000000006612","primary_keys":["ID","IDD"],"before":{"ID":1,"TEXT_NAME":null,"AGE":1,"ADD":null,"IDD":"8"},"after":{"ID":1,"TEXT_NAME":null,"AGE":20,"ADD":null,"IDD":"8"}}
到现在json信息里的内容已经很全了,基本满足了我想要的,附图: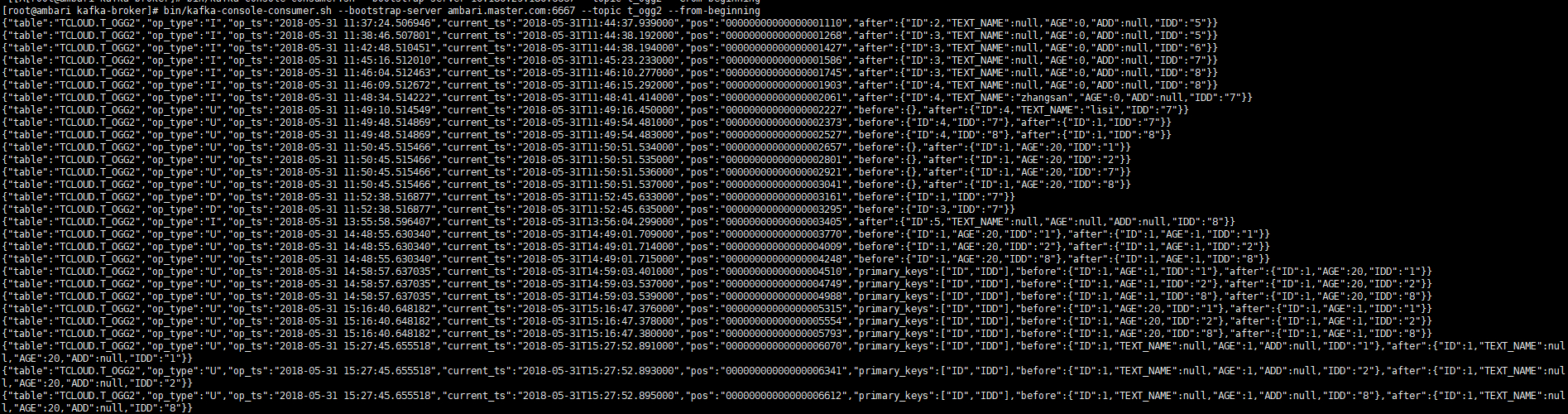
启发我发现和Oracle全列补充日志没有开启有关的博客:https://blog.csdn.net/huoshuyinhua/article/details/79013387
开启命令参考:https://blog.csdn.net/aaron8219/article/details/16825963
注:博客上讲到,开启全列补充日志会导致磁盘快速增长,LGWR进程繁忙,不建议使用。大家可根据自己的情况使用。
8、关于通配
如果想通配整个库的话,只需要把上面的配置所有表名的改为,如test_ogg.test_ogg改为 test_ogg.,但是kafka的topic不能通配,所以需要把所有的表的数据放在一个topic即可,后面再用程序解析表名即可。
9、附录
目标端在这里,下载下来后文件名123111_ggs_Adapters_Linux_x64.zip
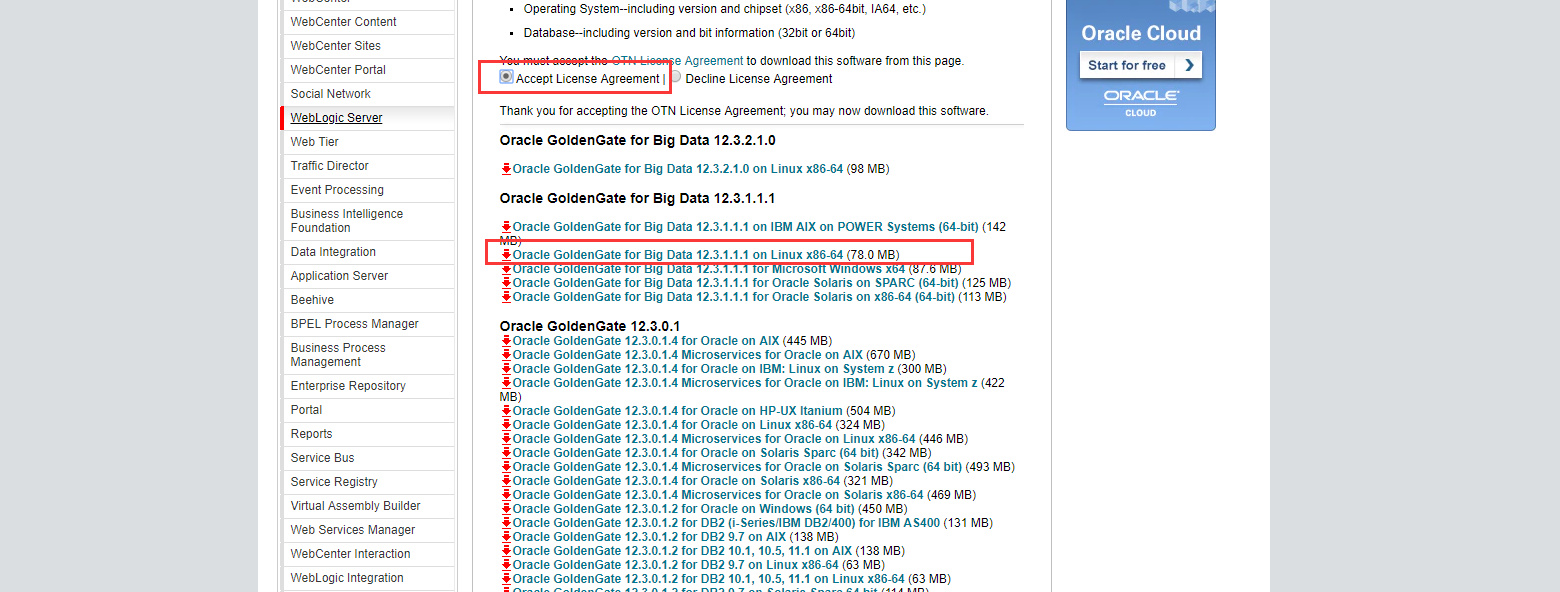
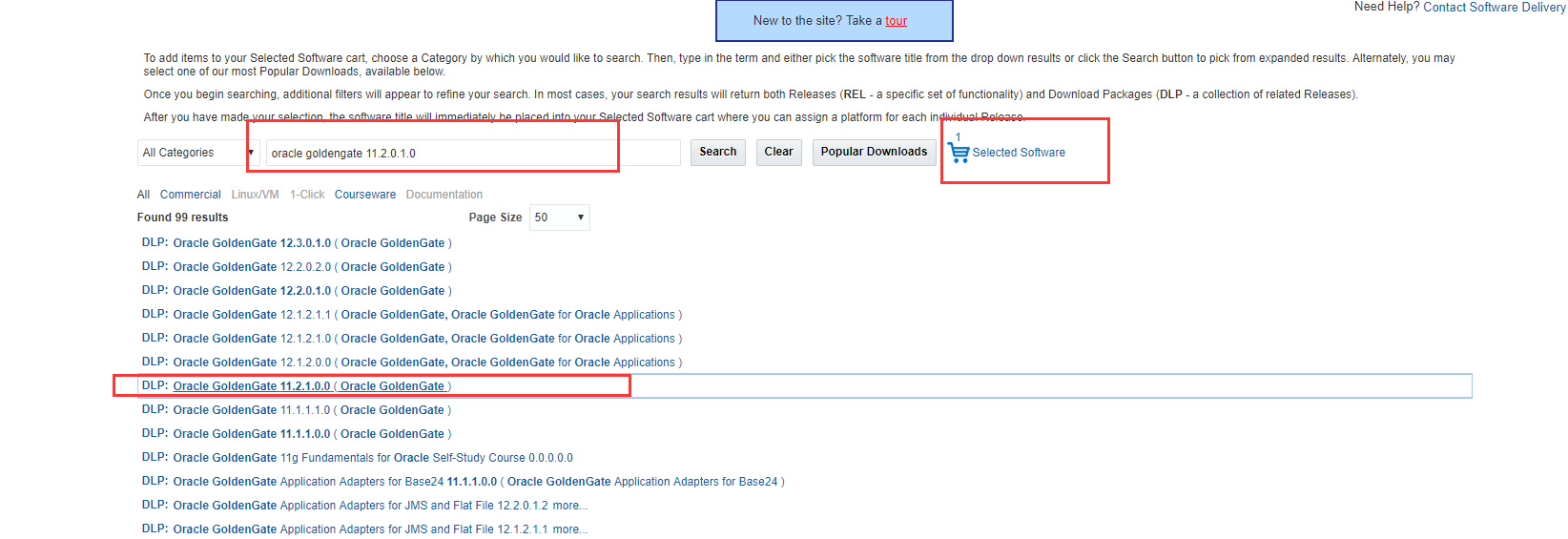
源端在旧版本查询下载,下载后文件名为V34339-01.zip
参考资料


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:利用ogg实现oracle到kafka的增量数据实时同步
本文链接:https://dongkelun.com/2018/05/23/oggOracle2Kafka/
欢迎关注我的公众号