

镜像
1 | docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/akaiot/oracle_11g:latest |
创建并启动容器
1 | mkdir -p /home/oracle/app/oracle11g/oradata |
1 | docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/akaiot/oracle_11g:latest |
1 | mkdir -p /home/oracle/app/oracle11g/oradata |
1 | https://docker.aityp.com/image/docker.io/truevoly/oracle-12c:latest |
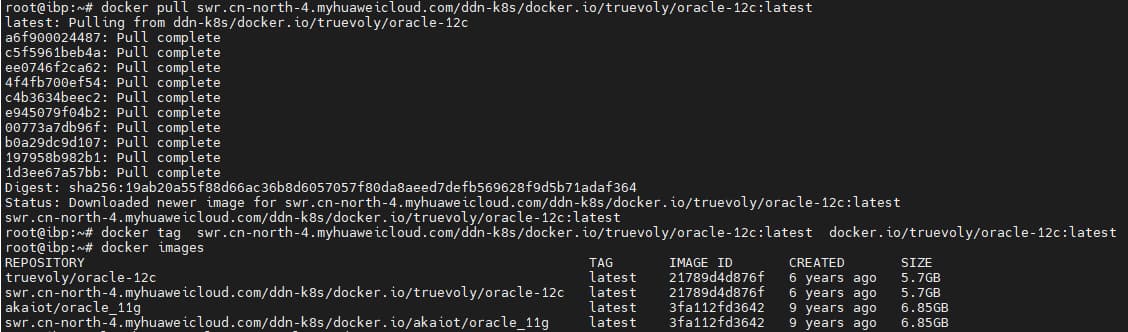
1 | mkdir -p /home/oracle/app/oracle12c/oradata |
https://www.dinky.org.cn/docs/1.1/deploy_guide/normal_deploy
https://github.com/DataLinkDC/dinky/releases/download/v1.1.0/dinky-release-1.15-1.1.0.tar.gz
https://github.com/DataLinkDC/dinky/releases/download/v1.2.3/dinky-release-1.15-1.2.3.tar.gz
more >>
记录 Flink jdbc、mysql-cdc 连接 mysql8 碰到的小问题
之前主要用 MySQL5 ,下面是 MySQL5 的 sql ,具体见 Flink MySQL CDC 使用总结
more >>总结 Flink HA
https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/deployment/ha/overview/
由官方文档可知:
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true