

前言
本文总结了Spark架构原理,其中主要包括五个组件:Driver、Master、Worker、Executor和Task,简要概括了每个组件是干啥的,并总结提交spark程序之后,这五个组件运行的详细步骤。
1、流程图
为了直观,就把流程图放在最前面了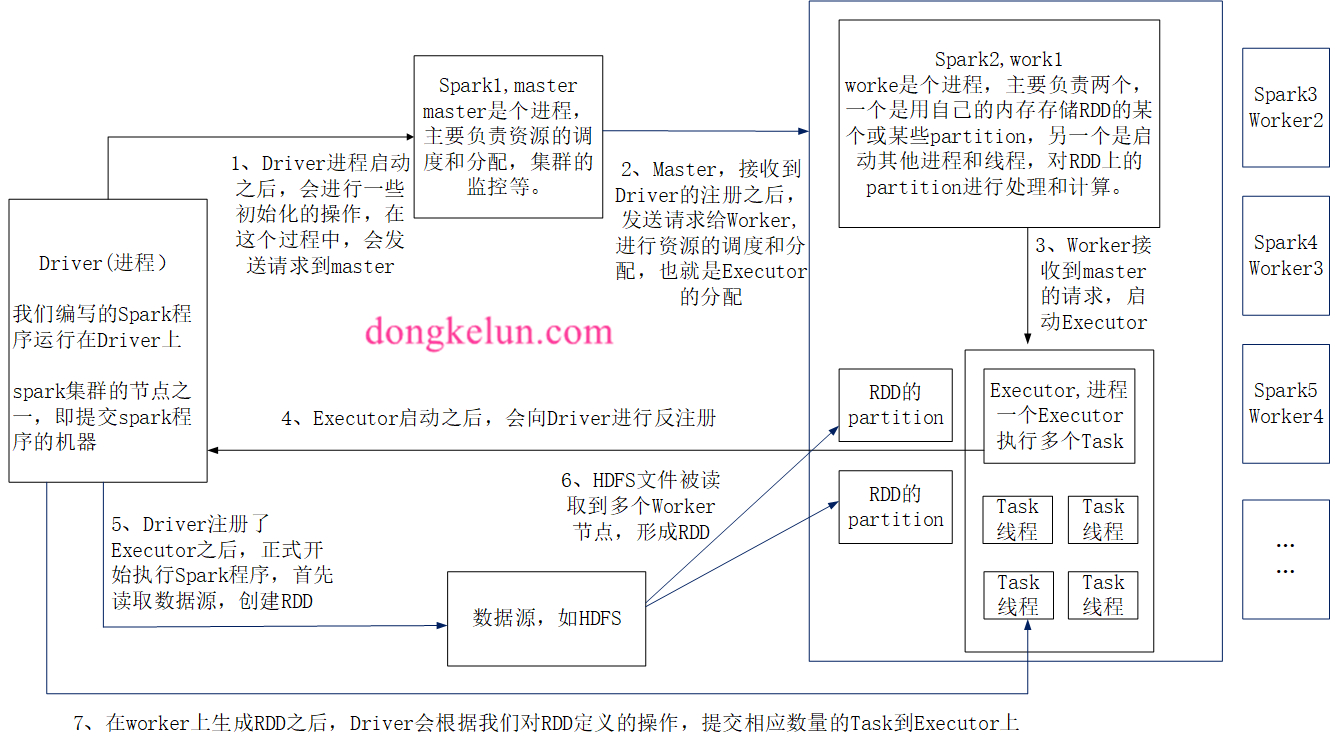
more >>
Spark 中一个很重要的能力是将数据持久化(或称为缓存),在多个操作间都可以访问这些持久化的数据。当持久化一个 RDD 时,每个节点的其它分区都可以使用 RDD 在内存中进行计算,在该数据上的其他 action 操作将直接使用内存中的数据。这样会让以后的 action 操作计算速度加快(通常运行速度会加速 10 倍)。缓存是迭代算法和快速的交互式使用的重要工具。
RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。
在 shuffle 操作中(例如 reduceByKey),即便是用户没有调用 persist 方法,Spark 也会自动缓存部分中间数据。这么做的目的是,在 shuffle 的过程中某个节点运行失败时,不需要重新计算所有的输入数据。如果用户想多次使用某个 RDD,强烈推荐在该 RDD 上调用 persist 方法。
每个持久化的 RDD 可以使用不同的存储级别进行缓存,例如,持久化到磁盘、已序列化的 Java 对象形式持久化到内存(可以节省空间)、跨节点间复制、以 off-heap 的方式存储在 Tachyon。这些存储级别通过传递一个 StorageLevel 对象给 persist() 方法进行设置。
详细的存储级别介绍如下:
注意,在 Python 中,缓存的对象总是使用 Pickle 进行序列化,所以在 Python 中不关心你选择的是哪一种序列化级别。python 中的存储级别包括 MEMORY_ONLY,MEMORY_ONLY_2,MEMORY_AND_DISK,MEMORY_AND_DISK_2,DISK_ONLY 和 DISK_ONLY_2 。
more >>
本文主要记录我自己对日期格式数据的一些常用操作,主要目的是备忘,方便随时查阅。本文没有将代码封装为函数,如果有需要的可以自行封装,注意每一部分的代码会依赖前面代码里的变量。
代码可以直接在spark-shell里运行(在scala里有的包没有)
1 | import java.text.SimpleDateFormat |
1 | Fri Jun 01 00:00:00 CST 2018 |
将上面的日期转成其他格式的字符串
1 | println(new SimpleDateFormat("yyyyMMdd").format(date)) |
1 | 20180601 |
本文讲如何用spark读取gz类型的压缩文件,以及如何解决我遇到的各种问题。
下面这一部分摘自Spark快速大数据分析:
在大数据工作中,我们经常需要对数据进行压缩以节省存储空间和网络传输开销。对于大多数Hadoop输出格式来说,我们可以指定一种压缩编解码器来压缩数据。
选择一个输出压缩编解码器可能会对这些数据以后的用户产生巨大影响。对于像Spark 这样的分布式系统,我们通常会尝试从多个不同机器上一起读入数据。要实现这种情况,每个工作节点都必须能够找到一条新记录的开端。有些压缩格式会使这变得不可能,而必须要单个节点来读入所有数据,这就很容易产生性能瓶颈。可以很容易地从多个节点上并行读取的格式被称为“可分割”的格式。下表列出了可用的压缩选项。
| 格式 | 可分割 | 平均压缩速度 | 文本文件压缩效率 | Hadoop压缩编解码器 | 纯Java实现 | 原生 | 备注 |
|---|---|---|---|---|---|---|---|
| gzip | 否 | 快 | 高 | org.apache.hadoop.io.compress.GzipCodec | 是 | 是 | |
| lzo | 是(取决于所使用的库) | 非常快 | 中等 | com.hadoop.compression.lzo.LzoCodec | 是 | 是 | 需要在每个节点上安装LZO |
| bzip2 | 是 | 慢 | 非常高 | org.apache.hadoop.io.compress.Bzip2Codec | 是 | 是 | 为可分割版本使用纯Java |
| zlib | 否 | 慢 | 中等 | org.apache.hadoop.io.compress.DefaultCodec | 是 | 是 | Hadoop 的默认压缩编解码器 |
| Snappy | 否 | 非常快 | 低 | org.apache.hadoop.io.compress.SnappyCodec | 否 | 是 | Snappy 有纯Java的移植版,但是在Spark/Hadoop中不能用 |
尽管Spark 的textFile() 方法可以处理压缩过的输入,但即使输入数据被以可分割读取的方式压缩,Spark 也不会打开splittable。因此,如果你要读取单个压缩过的输入,最好不要考虑使用Spark 的封装,而是使用newAPIHadoopFile 或者hadoopFile,并指定正确的压缩编解码器。
关于上面一段话的个人测试:选取一个大文件txt,大小为1.5G,写spark程序读取hdfs上的该文件然后写入hive,经测试在多个分区的情况下,txt执行时间最短,因为在多个机器并行执行,而gz文件是不可分割的,即使指定分区数目,但依然是一个分区,一个task,即在一个机器上执行,bzip2格式的文件虽然是可分割的,即可以按照指定的分区分为不同的task在多个机器上执行,但是执行时间长,比gz时间还长,经过四次改变bzip2的分区,发现最快的时间和gz时间是一样的,如果指定一个分区的话,比gz要慢很多,我想这样就可以更好的理解:”尽管Spark 的textFile() 方法可以处理压缩过的输入,但即使输入数据被以可分割读取的方式压缩,Spark 也不会打开splittable”这句话了。
我碰到的问题是这样的,我需要读取压缩文件里的数据存到hive表里,压缩文件解压之后是一个txt,这个txt里前几行的数据是垃圾数据,而这个txt文件太大,txt是直接打不开的,所以不能手动打开删除前几行数据,而这个文件是业务人员从别人那拿到的所以也不能改,本文就是讲如何解决这个问题。
首先造几条数据,以理解我的需求
data.txt1
2
3
4
5
6
7
8
id name addr time
------------ ------------------- --------------- --------------------
1 zhangsan shanghai 2018-05-25
2 zhangsan shanghai 2018-05-25
3 zhangsan shanghai 2018-05-25
4 zhangsan shanghai 2018-05-25
5 zhangsan shanghai 2018-05-25
其中前三行是我不想要的数据,第一行为空,第二行为字段名,第三行应该是为了美观单独加了一行。
more >>
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
