

前言
因后续要学习研究hbase,那就先从搭建hbase开始吧。先搭建一个单机版的,方便自己学习使用。
安装配置hadoop
参考我的另一篇文章:centos7 hadoop 单机模式安装配置
注:这里的JDK为1.8,版本支持如图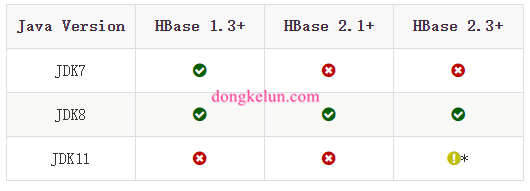
因后续要学习研究hbase,那就先从搭建hbase开始吧。先搭建一个单机版的,方便自己学习使用。
参考我的另一篇文章:centos7 hadoop 单机模式安装配置
注:这里的JDK为1.8,版本支持如图
总结如何使用Spark DataFrame isin 方法
查询DataFrame某列在某些值里面的内容,等于SQL IN ,如 where year in(‘2017’,’2018’)
isin 方法只能传集合类型,不能直接传DataFame或Column
more >>
总结记录Python 连接 MYSQL
1 | from sqlalchemy import create_engine |
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true