
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
作为新手,学习总结一下 Ray 的集群安装配置及简单使用。
官网
- 英文:https://docs.ray.io/en/latest/index.html
- 中文:https://docs.rayai.org.cn/en/latest/index.html
介绍
Ray 是一个开源的分布式计算框架,旨在简化分布式应用的开发和部署。它提供了简单易用的 API,让开发者能够轻松地将单机应用扩展到分布式环境,适用于机器学习、深度学习、数据处理等多种场景。
Ray 的核心特点
- 简单的分布式编程模型:通过装饰器(@ray.remote)可以轻松将函数或类转换为分布式版本,无需深入了解分布式系统细节。
- 自动任务调度:Ray 拥有高效的任务调度器,能够自动在集群中分配任务,优化资源利用率。
- 支持状态 ful 计算:除了无状态的任务,Ray 还支持有状态的 Actor 模型,适合需要维护状态的场景(如训练模型、服务部署)。
- 丰富的生态系统:包含多个上层库,如用于超参数调优的 Ray Tune、用于强化学习的 Ray RLlib、用于分布式训练的 Ray Train 等。
- 灵活的部署方式:可在单机、集群、云环境(AWS、GCP、Azure 等)中部署,支持动态资源扩展。
Ray 的典型应用场景
- 分布式机器学习:使用 Ray Train 进行分布式模型训练,支持 TensorFlow、PyTorch 等框架。
- 超参数调优:通过 Ray Tune 高效地在大规模参数空间中搜索最优参数组合。
- 强化学习:Ray RLlib 提供了多种强化学习算法的分布式实现,如 PPO、DQN 等。
- 数据处理与 ETL:与 Pandas、NumPy 等库集成,实现分布式数据处理。
- 服务部署:通过 Ray Serve 部署机器学习模型,支持动态扩缩容和 A/B 测试。
Ray 支持的编程语言
Ray 主要支持以下编程语言:
- Python:Ray 原生对 Python 支持最为完善和深入 。它提供了简洁易用的 Python API,能方便地将 Python 单机代码扩展到分布式环境,可用于机器学习(如与 TensorFlow、PyTorch 集成)、数据处理等场景,像用装饰器 @ray.remote 就能轻松定义分布式任务 。
- Java:提供了 Java 相关的集成,能让 Java 开发者利用 Ray 构建分布式应用,拓展在 Java 技术栈下的分布式计算能力 ,比如在一些大数据与 Java 结合的项目中可尝试运用。
- C++:也支持 C++ 语言进行开发,可用于对性能要求较高、需要接近底层系统操作的分布式计算场景,不过相比 Python,其使用场景和社区资源相对少一些 。
集群部署
在多个节点上部署 Ray 集群可以充分利用分布式资源,支持大规模规模的并行计算任务。Ray 提供了灵活的部署方式,可通过命令行工具、配置文件或云服务实现多节点部署。本文先简单学习总结手动部署方式(命令行)
核心概念
- Head 节点:集群的主节点,负责资源管理、任务调度和节点通信。
- Worker 节点:从节点,运行实际任务,通过 Head 节点加入集群。
- Redis 服务:Head 节点内置的 Redis,用于存储集群元数据和对象。
部署前提
所有节点需满足*:
安装相同版本的 Ray(pip install ray)
1
2
3conda create -n ray python=3.8
conda activate ray
pip install ray网络互通(推荐同一局域网,或配置端口开放)
- 节点间可通过 SSH 无密码登录(方便自动化部署)
- 时间同步(避免分布式任务时序问题)
端口要求(Head 节点需开放):
- 6379:Redis 服务(默认)
- 10001:GCS 服务
- 8265:Web UI 监控(可选)
步骤 1:启动 Head 节点
在选定的 Head 节点执行:
1 | # 启动 Head 节点,指定节点 IP(或 hostname)和端口 |
- –head:标记为 Head 节点
- –node-ip-address:Head 节点的 IP(必须是其他节点可访问的地址)
- –dashboard-host=0.0.0.0:允许外部访问 Web 监控界面(默认地址:http://
:8265) - –dashboard-port=8265:可选,指定端口(默认 8265)
执行成功后,会输出类似以下内容(保存此信息,用于 Worker 节点加入):
1 | ray start --head --node-ip-address=192.168.1.1 --port=6379 --dashboard-host=0.0.0.0 |
反馈信息解释:
- 使用统计收集提示:提示当前启用了使用统计收集功能,这是 Ray 的默认行为。如果想禁用,可以在启动命令中添加 –disable-usage-stats,或者在启动前运行 ray disable-usage-stats。提供的链接可查看更多相关说明。
- 本地节点 IP:显示当前 head 节点的 IP 地址为 192.168.1.1,这是在启动命令中通过 –node-ip-address 指定的。
- Ray 运行时启动成功:Ray runtime started 表明 head 节点已成功启动,集群的核心服务(如调度器、GCS 等)已开始运行。
- 后续操作指南:
- 添加其他节点:若要将其他机器加入集群,在目标机器上运行 ray start –address=’192.168.1.1:6379’(地址对应 head 节点的 IP 和端口)。
- 连接到集群:在 Python 代码中通过 import ray; ray.init(_node_ip_address=’192.168.1.1’) 连接到该集群。
- 终止集群:执行 ray stop 可停止当前节点的 Ray 运行时(若在 head 节点执行,会终止整个集群)。
- 查看集群状态:使用 ray status 命令可查看集群节点、资源等状态信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20ray status
======== Autoscaler status: 2025-09-25 11:14:20.889039 ========
Node status
---------------------------------------------------------------
Active:
1 node_98189e1d2d53037ae6b641e61a712f12f5b2b46e4de82da396ae30b9
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/128.0 CPU
0B/309.32GiB memory
0B/136.56GiB object_store_memory
Demands:
(no resource demands)
步骤 2:启动 Worker 节点
在所有 Worker 节点执行 Head 节点输出的连接命令:
1 | ray start --address='<HEAD_IP>:6379' --node-ip-address=<WORKER_IP> |
- –address:Head 节点的地址和端口
- –node-ip-address:当前 Worker 节点的 IP(可选,自动检测失败时指定)
1 | ray start --address='192.168.1.1:6379' |
输出如下:1
2
3
4
5
6
7
8
9
10ray start --address='192.168.1.1:6379'
Local node IP: 192.168.1.2
[2025-09-25 11:14:57,484 I 2267456 2267456] global_state_accessor.cc:432: This node has an IP address of 192.168.1.2, but we cannot find a local Raylet with the same address. This can happen when you connect to the Ray cluster with a different IP address or when connecting to a container.
--------------------
Ray runtime started.
--------------------
To terminate the Ray runtime, run
ray stop
上面的告警只有在第一次加入的时候才有,后面再重启就不会有了。
再查看集群状态:
1 | ray status |
步骤 3:验证集群状态
当所有 Worker 节点都启动后,在任意节点执行以下命令再次检查集群状态:
1 | ray status |
输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21======== Autoscaler status: 2025-09-25 16:30:26.209674 ========
Node status
---------------------------------------------------------------
Active:
1 node_a21d1db73c937f4f0003a4adefd29b0d1d2be64d5baa6be3995ccad3
1 node_98189e1d2d53037ae6b641e61a712f12f5b2b46e4de82da396ae30b9
1 node_ec50cec200d48e5db850bfdd0b709f9576c8d873221ffe9871590ed0
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/384.0 CPU
0B/962.39GiB memory
0B/416.44GiB object_store_memory
Demands:
(no resource demands)
测试连接 Ray 集群
测试代码
test_ray_cluster.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import ray
import time
import socket
# 关键:通过 Head 节点的 IP + 6379 端口连接集群
ray.init(address="192.168.1.1:6379")
# 定义分布式任务,返回执行任务的节点 IP(验证任务是否跨节点执行)
def test_task(x):
time.sleep(1) # 模拟耗时操作
# 获取当前执行任务的节点 IP
node_ip = socket.gethostbyname(socket.gethostname())
return f"任务 {x} 在节点 {node_ip} 上执行", x * 2
# 提交 200 个任务(数量建议超过单个节点的 CPU 数,迫使任务分配到多个节点)
start_time = time.time()
results = ray.get([test_task.remote(i) for i in range(200)])
end_time = time.time()
# 打印结果
for msg, result in results:
print(msg, f"结果: {result}")
print(f"\n总耗时: {end_time - start_time:.2f} 秒")
ray.shutdown()
执行与结果
1 | python test_ray_cluster.py |
结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
172025-09-25 17:30:35,888 INFO worker.py:1567 -- Connecting to existing Ray cluster at address: 192.168.1.1:6379...
2025-09-25 17:30:35,895 INFO worker.py:1752 -- Connected to Ray cluster.
任务 0 在节点 192.168.1.2 上执行 结果: 0
任务 1 在节点 192.168.1.2 上执行 结果: 2
……
任务 190 在节点 192.168.1.3 上执行 结果: 380
任务 191 在节点 192.168.1.3 上执行 结果: 382
任务 192 在节点 192.168.1.1 上执行 结果: 384
任务 193 在节点 192.168.1.1 上执行 结果: 386
任务 194 在节点 192.168.1.1 上执行 结果: 388
任务 195 在节点 192.168.1.1 上执行 结果: 390
任务 196 在节点 192.168.1.1 上执行 结果: 392
任务 197 在节点 192.168.1.1 上执行 结果: 394
任务 198 在节点 192.168.1.1 上执行 结果: 396
任务 199 在节点 192.168.1.1 上执行 结果: 398
总耗时: 3.67 秒
问题解决
没有 Dashboard 端口和 GCS 服务 端口
- 10001:GCS 服务
- 8265:Web UI 监控(可选)
解决
通过官网安装文档:https://docs.rayai.org.cn/en/latest/ray-overview/installation.html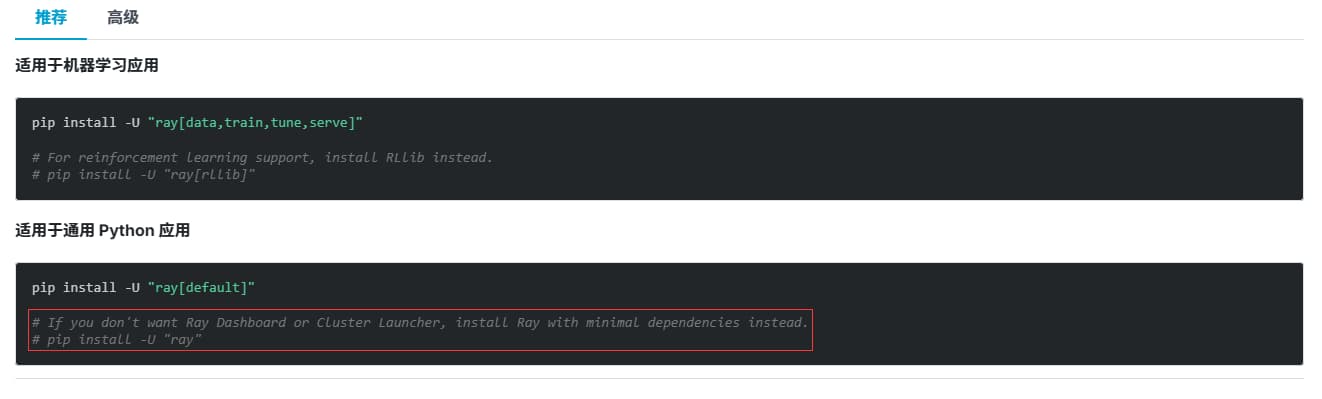
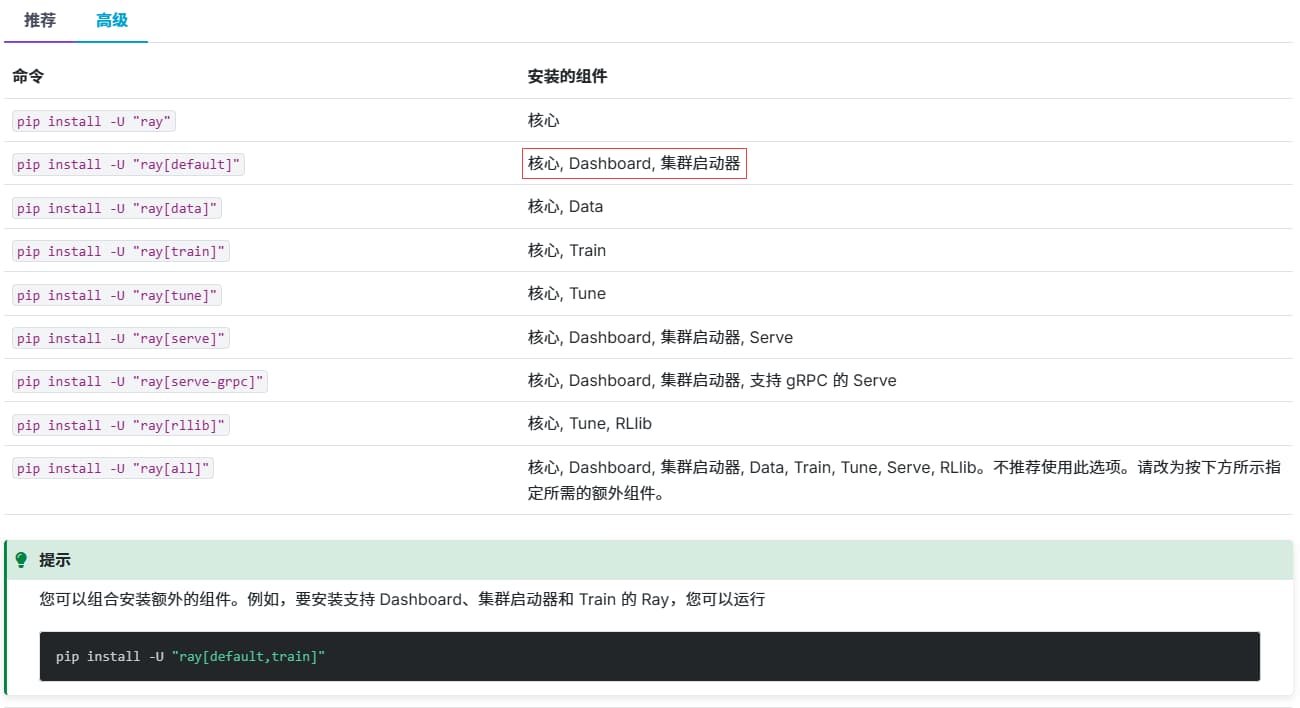
可以发现: 默认的 pip install ray 只会安装最小依赖的核心组件并不包含 Dashboard 和 集群启动器 ,我们只需要装一下 ray[default] ,然后重启集群即可。
1 | pip install ray[default] |
然后通过启动输出信息就会发现变化,多出了 dashboard 的信息:
1 | Usage stats collection is enabled. To disable this, add `--disable-usage-stats` to the command that starts the cluster, or run the following command: `ray disable-usage-stats` before starting the cluster. See https://docs.ray.io/en/master/cluster/usage-stats.html for more details. |
查看对应的端口是否启动:1
2
3
4netstat -nlp | grep 8265
tcp 0 0 0.0.0.0:8265 0.0.0.0:* LISTEN 4160112/python
netstat -nlp | grep 10001
tcp6 0 0 :::10001 :::* LISTEN 4160111/python
这样在集群内部再次运行上面的测试代码时,输出信息也会多出 dashboard 的信息:1
22025-09-25 18:24:57,608 INFO worker.py:1567 -- Connecting to existing Ray cluster at address: 192.168.1.1:6379...
2025-09-25 18:24:57,613 INFO worker.py:1743 -- Connected to Ray cluster. View the dashboard at http://192.168.1.1:8265
Dashboard 页面:
上面的测试代码在集群外部无法运行
信息如下:1
22025-09-25 18:11:07,547 INFO worker.py:1567 -- Connecting to existing Ray cluster at address: 192.168.1.1:6379...
2025-09-25 18:11:08,553 INFO node.py:1010 -- Can't find a `node_ip_address.json` file from /tmp/ray/session_2025-09-25_18-06-25_767300_4159945. Have you started Ray instsance using `ray start` or `ray.init`?
解决
修改 Ray 集群地址,通过 10001 端口连接即可:1
ray.init(address="ray://192.168.1.1:10001")


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Ray 集群安装配置
本文链接:https://dongkelun.com/2025/09/26/python/rayClusterConf/
欢迎关注我的公众号