
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
上篇文章提到 :索引的逻辑主要是根据 parquet 文件中保存的索引信息,判断记录是否存在,如果不存在,代表是新增数据,如果记录存在则代表是更新数据,需要找到并设置 currentLocation。对于布隆索引来说,这里的索引信息其实是布隆过滤器,本篇文章主要是先总结布隆过滤器是如何保存到 parquet 文件中的(主要是源码调用逻辑)。
我们新写一个表的时候,最开始是没有parquet文件的,所以顺序应该是先将布隆过滤器写到 parquet 文件中,下次写数据的时候,先读取 parquet 文件中的布隆过滤器来验证表中是否存在该记录,有助于实现高效的更新和删除操作。
索引
索引是一个关键的步骤,它验证表中是否存在记录,并有助于实现高效的更新和删除操作。请注意本文中涵盖的索引是为写入端准备的,这与读取端索引不同。
对于有的索引类型是不涉及将索引信息保存到文件中的,比如 简单索引(simple index),而对于Bloom索引(Bloom Index)则需要将布隆过滤器以及最大值最小值等信息写到 parquet 文件中的元数据中。
Bloom索引(Bloom Index)
Bloom Index 最大限度地减少了用于查找的键和文件的数量,同时保持了较低的读取成本。
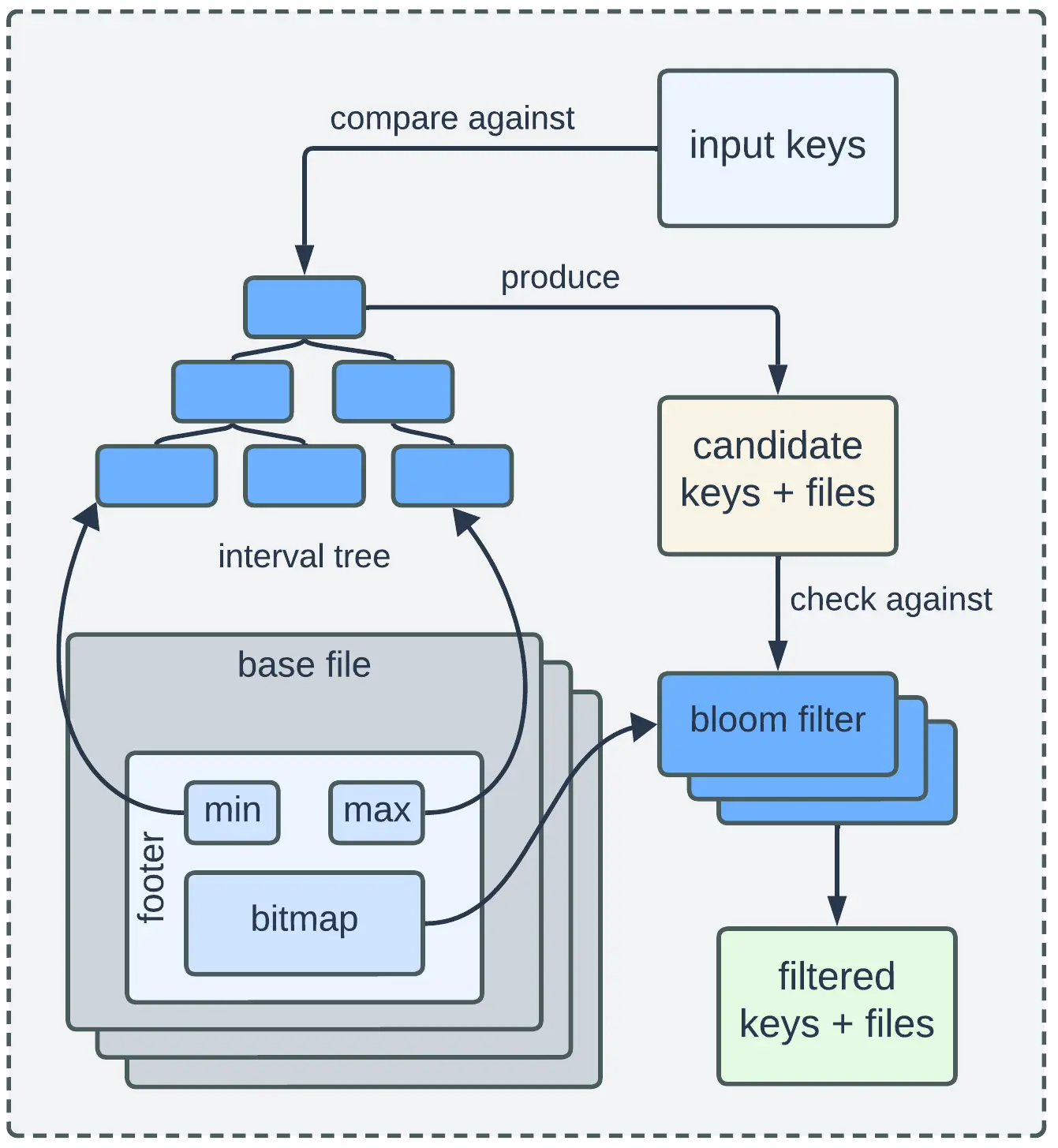
Bloom Index 采用 2 阶段过滤来减少用于查找的键和文件的数量。
- 第一阶段涉及将输入键与使用存储在基本文件页脚中的最小和最大记录键值构建的间隔树进行比较。超出这些范围的键代表新插入,而其余键则被视为下一阶段的候选键。
- 第二阶段根据反序列化的 Bloom 过滤器检查候选键,这有助于确定明确不存在的键和可能存在的键。然后使用筛选后的键和关联的基文件执行实际的文件查找,这些基文件随后返回用于标记的键和位置元组。
请注意,查找之前的过滤过程仅涉及读取文件页脚,因此读取成本较低。
源码分析
主要步骤包含布隆过滤器(BloomFilter)的创建、更新、和持久化。
fileWriter
HoodieCreateHandle 和 HoodieMergeHandle 中的 fileWriter 均为 HoodieParquetWriter 。
都是在构造函数中调用 HoodieFileWriterFactory.getFileWriter 创建
HoodieFileWriterFactory
1 | public static <T extends HoodieRecordPayload, R extends IndexedRecord, I, K, O> HoodieFileWriter<R> getFileWriter( |
populateMetaFields
启用时,填充所有元字段。禁用时,不会填充任何元字段,增量查询也不会起作用。这仅用于批处理的仅附加/不可变数据
简单说就是是否填充所有的元数据字段。
从上面的代码可以看到是否开启布隆过滤器和 populateMetaFields 的值一样。
1 | public static final ConfigProperty<String> POPULATE_META_FIELDS = ConfigProperty |
创建布隆过滤器
HoodieFileWriterFactory.createBloomFilter1
2
3
4
5private static BloomFilter createBloomFilter(HoodieWriteConfig config) {
return BloomFilterFactory.createBloomFilter(config.getBloomFilterNumEntries(), config.getBloomFilterFPP(),
config.getDynamicBloomFilterMaxNumEntries(),
config.getBloomFilterType());
}
几个参数:
- config.getBloomFilterNumEntries : BLOOM_FILTER_NUM_ENTRIES_VALUE hoodie.index.bloom.num_entries 默认值 6000
- config.getBloomFilterFPP :BLOOM_FILTER_FPP_VALUE hoodie.index.bloom.fpp 默认值 0.000000001
- config.getDynamicBloomFilterMaxNumEntries :BLOOM_INDEX_FILTER_DYNAMIC_MAX_ENTRIES hoodie.bloom.index.filter.dynamic.max.entries 默认值 100000
- config.getBloomFilterType() : BLOOM_FILTER_TYPE hoodie.bloom.index.filter.type 默认值 BloomFilterTypeCode.DYNAMIC_V0.name
BloomFilterFactory.createBloomFilter
1 | public static BloomFilter createBloomFilter(int numEntries, double errorRate, int maxNumberOfEntries, |
默认值 BloomFilterTypeCode.DYNAMIC_V0.name ,返回 HoodieDynamicBoundedBloomFilter
writeSupport
HoodieParquetWriter 中的 writeSupport 为 HoodieAvroWriteSupport1
HoodieAvroWriteSupport writeSupport = new HoodieAvroWriteSupport(new AvroSchemaConverter(hoodieTable.getHadoopConf()).convert(schema), schema, filter);
更新布隆过滤器
通过 HoodieAvroWriteSupport.add 更新布隆过滤器,将 recordKey 添加到 BloomFilter 中,调用链:
- Insert : HoodieCreateHandle.write -> HoodieParquetWriter.writeAvro/writeAvroWithMetadata -> HoodieAvroWriteSupport.add
- Upsert : HoodieMergeHandle.write -> HoodieParquetWriter.writeAvro/writeAvroWithMetadata-> HoodieAvroWriteSupport.add
1 | public void add(String recordKey) { |
这里主要调用 HoodieDynamicBoundedBloomFilter.add 继而调用 InternalDynamicBloomFilter.add 最终将 recordKey 添加到 org.apache.hadoop.util.bloom.BloomFilter 中,然后更新最大值和最小值。
写布隆过滤器
Insert 和 Update 最终都通过调用 HoodieParquetWriter.close 实现将布隆过滤写到 Parquet Metadata :
1 | writer.model.name : avro |
调用链:
Insert : BoundedInMemoryQueueConsumer.consume -> BoundedInMemoryQueueConsumer.finish -> CopyOnWriteInsertHandler.finish -> CopyOnWriteInsertHandler.closeOpenHandles -> HoodieCreateHandle.close -> HoodieParquetWriter.close
-> org.apache.parquet.hadoop.ParquetWriter.close -> org.apache.parquet.hadoop.InternalParquetRecordWriter.close -> org.apache.parquet.hadoop.ParquetFileWriter.end -> ParquetFileWriter.serializeFooterUpsert : BaseJavaCommitActionExecutor.handleUpdate -> handleUpdateInternal -> JavaMergeHelper.runMerge -> HoodieMergeHandle.close -> HoodieParquetWriter.close
-> org.apache.parquet.hadoop.ParquetWriter.close -> org.apache.parquet.hadoop.InternalParquetRecordWriter.close -> org.apache.parquet.hadoop.ParquetFileWriter.end -> ParquetFileWriter.serializeFooter
HoodieParquetWriter.close1
2
3
4
5
6
7
8
9
10public void close() throws IOException {
try {
writer.close();
} catch (InterruptedException e) {
throw new IOException(e);
} finally {
// release after the writer closes in case it is used for a last flush
codecFactory.release();
}
}
InternalParquetRecordWriter.close
1 | public void close() throws IOException, InterruptedException { |
HoodieAvroWriteSupport.finalizeWrite
1 |
|
writeSupport.getName -> HoodieAvroWriteSupport.getName -> AvroWriteSupport.getName
1 |
|
ParquetFileWriter.end1
2
3
4
5
6
7
8public void end(Map<String, String> extraMetaData) throws IOException {
state = state.end();
LOG.debug("{}: end", out.getPos());
// 将 extraMetaData 赋给 FileMetaData.keyValueMetaData
this.footer = new ParquetMetadata(new FileMetaData(schema, extraMetaData, Version.FULL_VERSION), blocks);
serializeFooter(footer, out);
out.close();
}
ParquetFileWriter.serializeFooter1
2
3
4
5
6
7
8
9
10private static void serializeFooter(ParquetMetadata footer, PositionOutputStream out) throws IOException {
long footerIndex = out.getPos();
// 将 footer 转换为 org.apache.parquet.format.FileMetaData
org.apache.parquet.format.FileMetaData parquetMetadata = metadataConverter.toParquetMetadata(CURRENT_VERSION, footer);
// 调用 writeFileMetaData 将 parquetMetadata 写到 parquet 元数据中
writeFileMetaData(parquetMetadata, out);
LOG.debug("{}: footer length = {}" , out.getPos(), (out.getPos() - footerIndex));
BytesUtils.writeIntLittleEndian(out, (int) (out.getPos() - footerIndex));
out.write(MAGIC);
}


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Hudi 索引总结 - Parquet布隆过滤器写入过程
本文链接:https://dongkelun.com/2024/07/10/hudi/hudiIndex-wirte/
欢迎关注我的公众号