
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
研究总结 Hudi extraMetadata ,记录研究过程。主要目的是通过 extraMetadata 保存 source 表的 commitTime (checkpoint), 来实现增量读Hudi表写Hudi表时,保存增量读状态的事务性,实现类似于流任务中的 exactly-once
背景需求
有个需求:增量读Hudi表关联其他Hudi表然后做一些复杂的业务处理逻辑,然后将结果表保存到目标Hudi表中
然后就有问题:如何保证保存目标Hudi表和保存 endCommiTime 是事务的。具体如下
1、Spark支持增量读Hudi表,需要传入起(始) commitTime。
2、上一批数据处理完成后应该保存上次增量读的的 endCommiTime,作为下一批增量读的的 beginCommitTime
3、可以选择将上一批的 endCommiTime 保存到 HDFS 或者数据库表中,但是不能保证事务。(并且还需要借助外部表或者存储目录,如果能通过Hudi本身解决,就比较完美了)
4、也就是可能存在保存目标Hudi表成功,但是保存 endCommiTime 失败的情况
这时就想到了 DeltaStreamer 中是通过设置 checkpoint 来实现的,具体是通过将 commitTime 的值保存到目标表 .commit 元数据文件中(extraMetadata->deltastreamer.checkpoint.key)。我们可以参考 DeltaStreamer 中的实现逻辑,来实现我们的需求。
版本
- Hudi 0.13.0
- Spark 3.2.3
DeltaStreamer
官方文档:https://hudi.apache.org/docs/0.13.0/hoodie_deltastreamer/
Checkpointing
HoodieDeltaStreamer使用检查点来跟踪已经读取的数据,因此无需重新处理所有数据即可恢复。当使用Kafka源时,检查点是Kafka偏移,当使用DFS源时,该检查点是最近读取的文件的“上次修改”时间戳。检查点保存在.houdie提交文件中,作为deltastreamer.checkpoint.key。
如果需要更改检查点以重新处理或重放数据,可以使用以下选项:
–checkpoint将在提交文件中设置deltastreamer.checkpoint.reset_key以覆盖当前检查点。
–源限制将设置要从源读取的最大数据量。对于DFS源,这是读取的最大字节数。对于kafka来说,这是要阅读的事件的最大数量。
先直接看一下 DeltaStreamer 的 checkpoint 长啥样:checkpoint 保存在 .commit文件中的 extraMetadata:deltastreamer.checkpoint.key 中。
对于DFSSource,checkpoint 保存的是最近读取的文件的“上次修改”时间戳。
对于HoodieIncrSource,checkpoint 保存的Hudi表的 commitTime.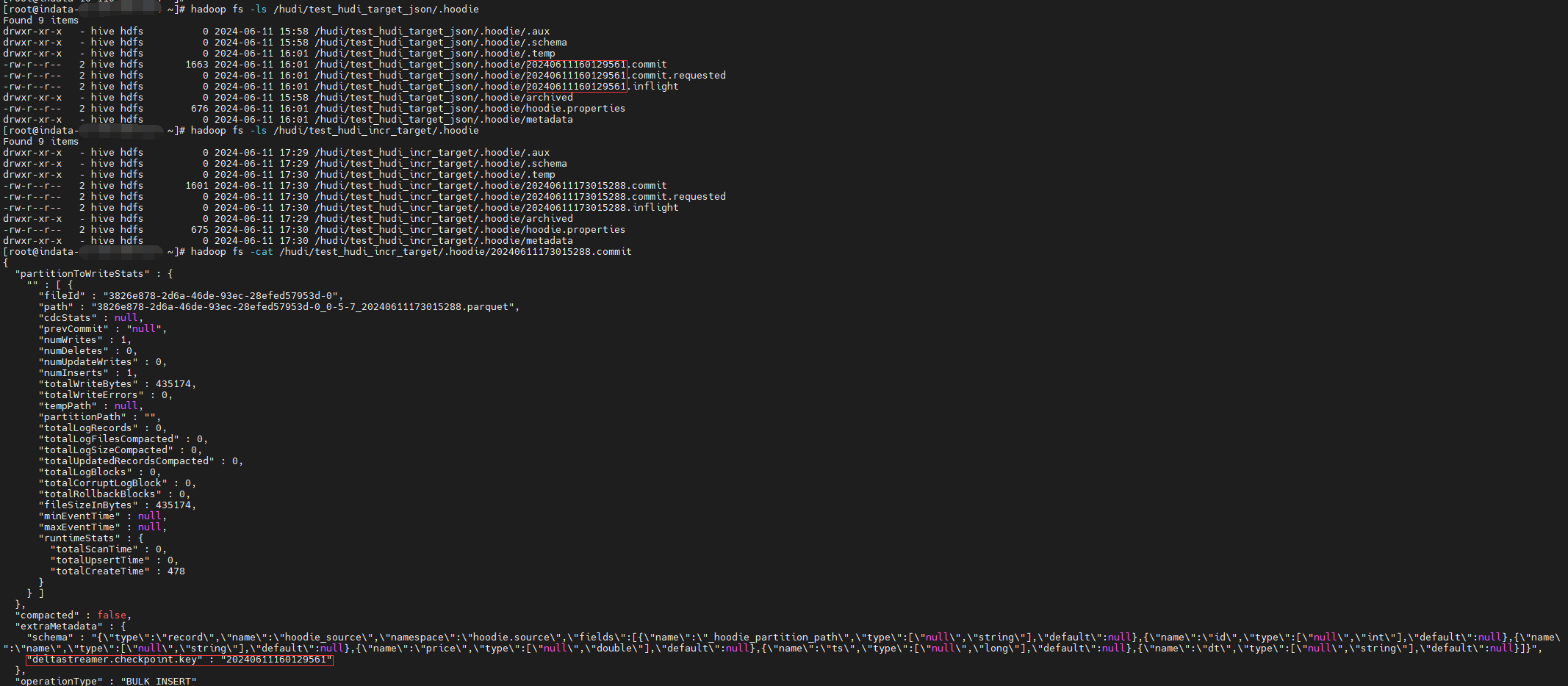
对于KafkaSource,checkpoint 保存的是 offset
示例
以下是 DFSSource 和 HoodieIncrSource 的示例,对于 DeltaStreamer 不熟悉的可以参考我之前写的文章
DFSSource
创建 source表并造数1
2
3
4
5
6
7
8
9
10
11create table test.test_source_json(
id int,
name string,
price double,
ts bigint,
dt string
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
insert into test.test_source_json values (1,'hudi', 10.0,100,'2024-06-11');
common.properties
1 | hoodie.datasource.write.hive_style_partitioning=true |
json_dfs_source.properties
1 | include=common.properties |
1 | spark-submit --conf "spark.sql.catalogImplementation=hive" \ |
HoodieIncrSource
hudi_incr_source.properties1
2
3
4
5
6
7
8
9
10
11include=common.properties
hoodie.datasource.write.recordkey.field=id
hoodie.datasource.write.partitionpath.field=
hoodie.deltastreamer.source.hoodieincr.path=/hudi/test_hudi_target_json
hoodie.deltastreamer.source.hoodieincr.missing.checkpoint.strategy=READ_UPTO_LATEST_COMMIT
#hoodie.deltastreamer.source.hoodieincr.num_instants=1
hoodie.datasource.hive_sync.table=test_hudi_incr_target
hoodie.datasource.hive_sync.database=hudi
1 | spark-submit --conf "spark.sql.catalogImplementation=hive" \ |
参考 DeltaStreamer
从上面的示例中,我们看到 DeltaStreamer 的 HoodieIncrSource 可以实现将 commitTime 保存到 .commit 文件中的 extraMetadata:deltastreamer.checkpoint.key 中。因为写Hudi表是事务的,这样就将写Hudi表和保存增量读状态绑定到一个事务中了。我们下次增量读的时候就可以去读目标表 .commit 文件中保存的源表的commitTime,作为增量读的beginTime,从而实现我们的需求。
但是目前还不知道 extraMetadata 是怎么保存的,所以我们需要先参考一下 DeltaStreamer 的源码,以下是部分源码:
HoodieDeltaStreamer.main -> HoodieDeltaStreamer.sync -> DeltaSync.syncOnce -> DeltaSync.syncOnce 和 DeltaSync.writeToSink
(其中 DeltaSync.syncOnce 会通过 readFromSource 获取具体的数据和checkpoint,比如 source 为 HoodieIncrSource 时,最终会调用 HoodieIncrSource.fetchNextBatch)
DeltaSync.writeToSink
1 | private Pair<Option<String>, JavaRDD<WriteStatus>> writeToSink(JavaRDD<HoodieRecord> records, String checkpointStr, |
这里writeClient 为SparkRDDWriteClient,从 writeToSink 可以看出整体逻辑:
1、startCommit()。对应生成 .requested
2、调用 writeClient 的 insert、upsert、bulkInsert等方法。对应生成 .inflight。
3、将 checkpointStr 作为 CHECKPOINT_KEY 的值放到 checkpointCommitMetadata中,通过 writeClient.commit 方法将 checkpointCommitMetadata 作为 extraMetadata 写到 .commit 文件中。对应生成 .commit
解释一下2:默认情况下 writeClient.insert 会先生成 .inflight,然后写数据,最后生成 .commit。
writeClient.insert 最终会调用 commitOnAutoCommit,因为默认情况下 config.shouldAutoCommit 是true,所以会调用 autoCommit(extraMetadata, result) 生成.commit。但是在 DeltaSync 中构造 writeClient 将 AutoCommit 配置成了false,所以 步骤 2不会生成.commit,这样就可以在步骤3中手动调用 writeClient.commit 将 checkpointCommitMetadata 作为 extraMetadata 写到 .commit 文件中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43 protected void commitOnAutoCommit(HoodieWriteMetadata result) {
// validate commit action before committing result
runPrecommitValidators(result);
if (config.shouldAutoCommit()) {
LOG.info("Auto commit enabled: Committing " + instantTime);
autoCommit(extraMetadata, result);
} else {
LOG.info("Auto commit disabled for " + instantTime);
}
}
public static final ConfigProperty<String> AUTO_COMMIT_ENABLE = ConfigProperty
.key("hoodie.auto.commit")
.defaultValue("true")
.withDocumentation("Controls whether a write operation should auto commit. This can be turned off to perform inspection"
+ " of the uncommitted write before deciding to commit.");
private HoodieWriteConfig getHoodieClientConfig(Schema schema) {
final boolean combineBeforeUpsert = true;
// 这里将 autoCommit 配置为 false。
final boolean autoCommit = false;
// NOTE: Provided that we're injecting combined properties
// (from {@code props}, including CLI overrides), there's no
// need to explicitly set up some configuration aspects that
// are based on these (for ex Clustering configuration)
HoodieWriteConfig.Builder builder =
HoodieWriteConfig.newBuilder()
.withPath(cfg.targetBasePath)
.combineInput(cfg.filterDupes, combineBeforeUpsert)
.withCompactionConfig(
HoodieCompactionConfig.newBuilder()
.withInlineCompaction(cfg.isInlineCompactionEnabled())
.build()
)
.withPayloadConfig(
HoodiePayloadConfig.newBuilder()
.withPayloadClass(cfg.payloadClassName)
.withPayloadOrderingField(cfg.sourceOrderingField)
.build())
.forTable(cfg.targetTableName)
.withAutoCommit(autoCommit)
.withProps(props);
从上面的分析中,我们知道了 extraMetadata 是通过 writeClient.commit 方法写到.commit 文件中的,并不是通过参数配置实现的。这属于Hudi源码中比较底层的代码,如果是 Hudi Java Client 可以参考这样实现,但是 Spark Client 是封装好的,这样实现并不通用。最好是研究一下有没有通过参数配置实现的这种比较简单的方案,如果实在没有再考虑自己参考 DeltaStreamer 的逻辑实现,封装一个公用的实现方法,或者修改源码,所以接下来先看一下 Spark Client 的 源码:HoodieSparkSqlWriter
HoodieSparkSqlWriter
HoodieSparkSqlWriter.write
1 | def write(sqlContext: SQLContext, |
和 DeltaStreamer 相同的逻辑,分三步:
1、client.startCommitWithTime 。对应生成 .requested
2、DataSourceUtils.doWriteOperation , 其中 这里的client 是通过 DataSourceUtils.createHoodieClient 创建的,也设置了 autoCommit 为 false。对应生成 .inflight。
3、commitAndPerformPostOperations 。对应生成 .commit
接下来看一下 commitAndPerformPostOperations 有没有可以通过配置参数来设置 extraMetadata的实现方法。
1 | private def commitAndPerformPostOperations(spark: SparkSession, |
这里惊喜的发现有一个有可能实现我们需求的参数:COMMIT_METADATA_KEYPREFIX.key
COMMIT_METADATA_KEYPREFIX
1 | val COMMIT_METADATA_KEYPREFIX: ConfigProperty[String] = ConfigProperty |
以该前缀开头的选项键会自动添加到commit/detacommit元数据中。这对于以与hudi时间线一致的方式存储检查点信息非常有用.
根据文档注释发现该参数确实有可能能实现我们的需求,但是该参数该怎么用呢?网上并没有找到相关的文档,简单尝试一下,发现也并不生效。最终参考源码中的测试用例实现:
1 |
|
写示例
根据测试用例中的用法,简单尝试一下,看是否生效1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18create table hudi.test_hudi_table (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts',
hoodie.datasource.write.commitmeta.key.prefix='commit_extra_meta_',
commit_extra_meta_a='valA',
commit_extra_meta_b='valB'
);
insert into hudi.test_hudi_table values (1,'hudi',10,100,'2024-06-11');
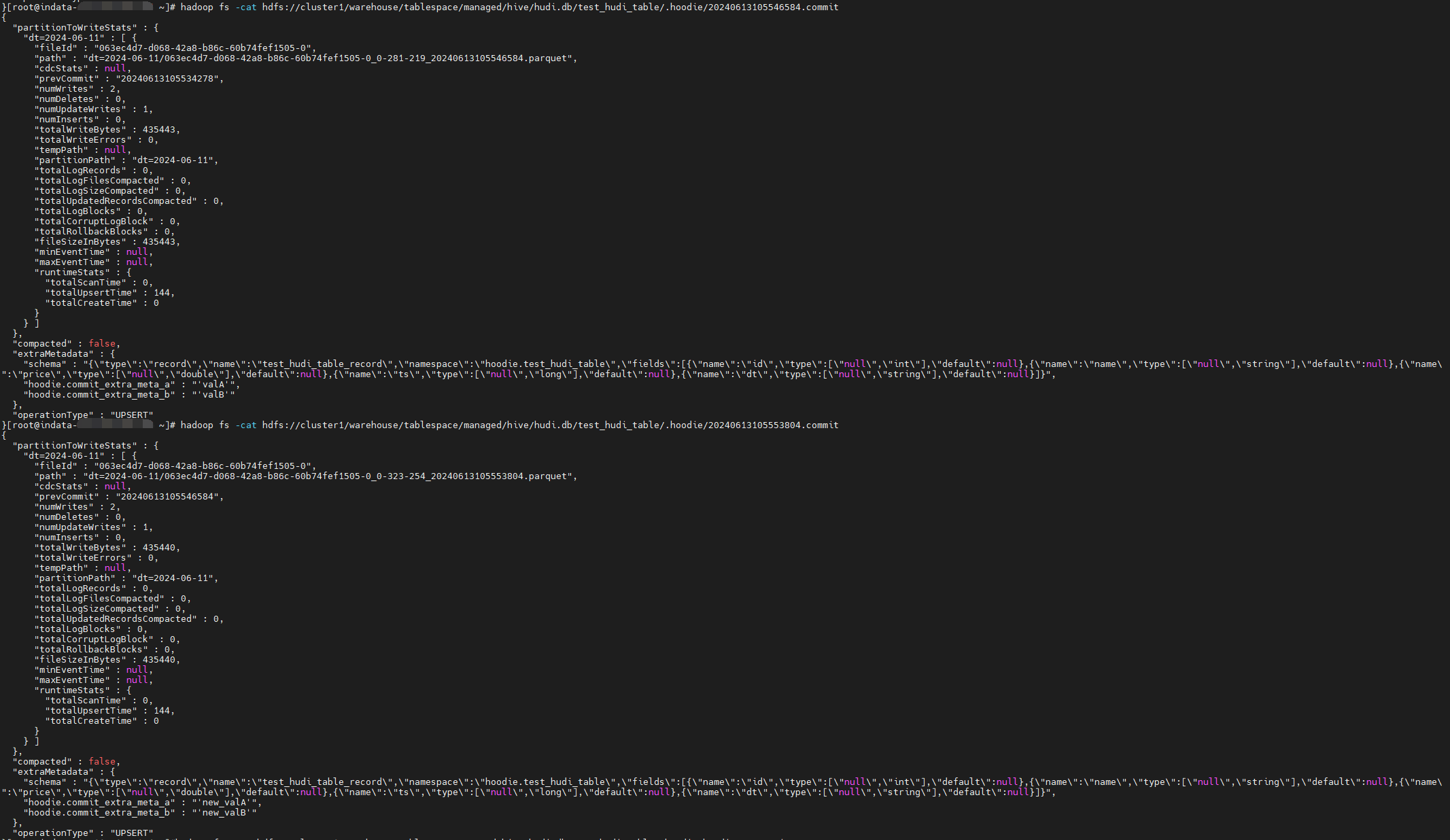
结果发现成功添加了 extraMetadata ,其中 schema 是默认自带的,commit_extra_meta_b 和 commit_extra_meta_a 是新添加的。
1 | "extraMetadata" : { |

但是这种方式,在建表语句里写死了值,不能灵活设置。我们的需求是要灵活设置,因为每次insert 对应的 beginCommitTime 都会变化, 我们尝试验证一下能不能灵活配置。
SQL SET
1 | create table hudi.test_hudi_table ( |
经验证,不生效。原因是Hudi Spark SQL 源码里过滤掉了不是以 hoodie. 开头的配置项。也就是要求配置项必须以 hoodie. 开头才生效,这样我们设置的 commit_extra_meta_a 和 commit_extra_meta_b 就不会生效。
相关源码:
InsertIntoHoodieTableCommand.run -> ProvidesHoodieConfig.buildHoodieInsertConfig
1 | def run(sparkSession: SparkSession, |
所以我们可以将 prefix 改为以 hoodie. 开头:
1 | set hoodie.datasource.write.commitmeta.key.prefix=hoodie.commit_extra_meta_; |
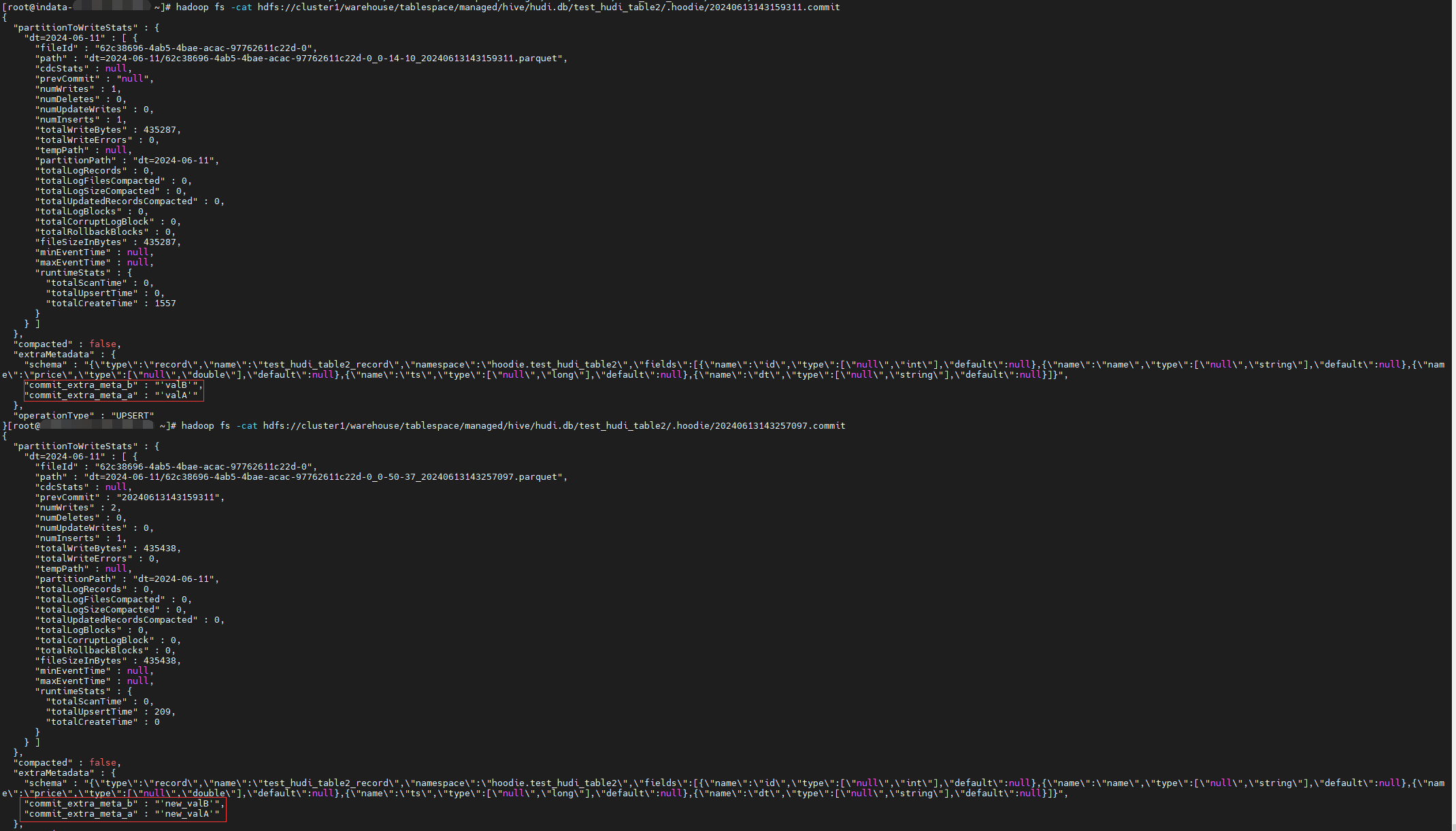
经验证,生效:
但是这样限制并不合理,比如 DeltaStreamer 的 key 为 deltastreamer.checkpoint.key ,就不是以 hoodie. 开头,假如我们有这样的需求,不想被限制住,就可以通过修改源码来解决。
源码:https://github.com/dongkelun/hudi/commit/f8c3d547928af0d3287de42e3d0148970f21472c
jar包:https://download.csdn.net/download/dkl12/89429544
注意:set prefix 时不要加引号:1
2## 加引号是有问题的
set hoodie.datasource.write.commitmeta.key.prefix='hoodie.commit_extra_meta_';
原因:调试代码发现,解析时没有将引号删掉,导致过滤失效。’hoodie.commit_extrameta‘ 不等于 hoodie.commit_extrameta 。这样代码 val metaMap = parameters.filter(kv => kv._1.startsWith(parameters(COMMIT_METADATA_KEYPREFIX.key))) 返回空。
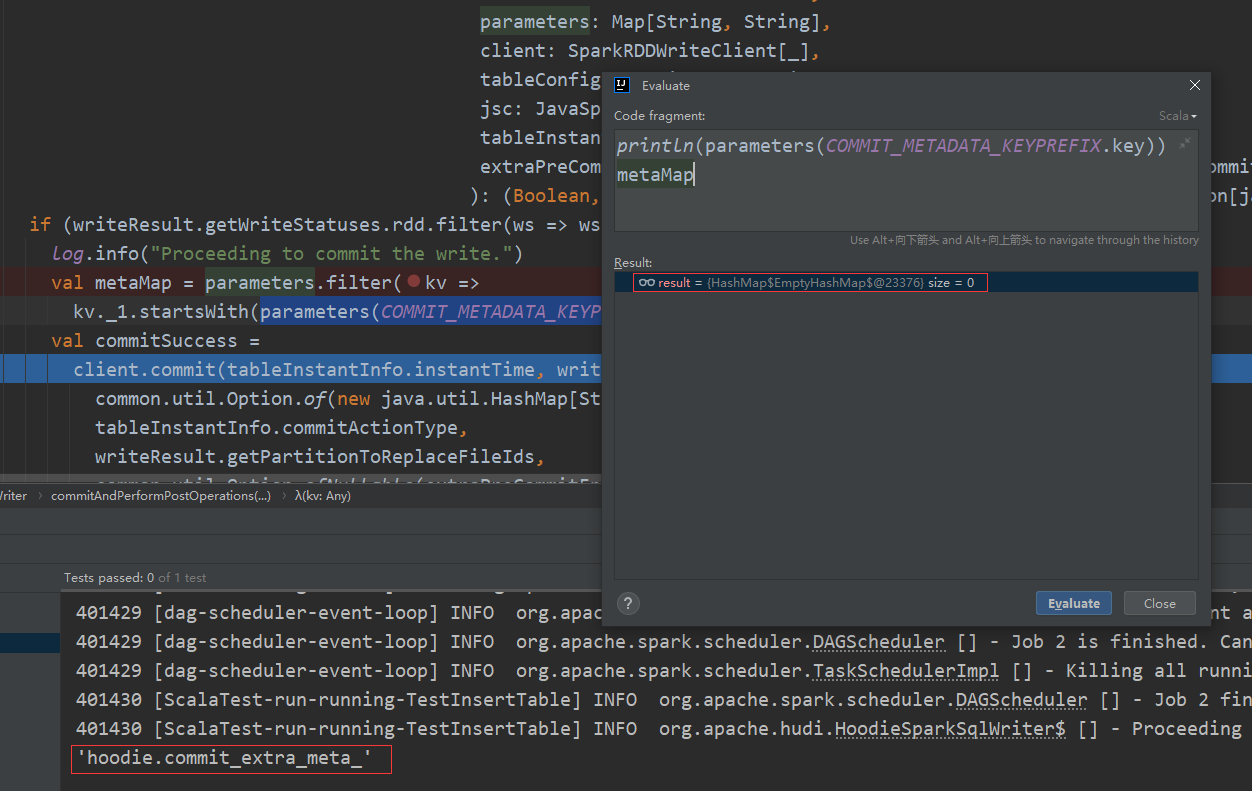
代码
根据我对Hudi源码的理解:因为代码和SQL的入口不一样, 代码可能并没有 hoodie. 开头的限制。接下来验证一下代码有没有 hoodie. 开头的限制,会不会生效。(先将包还原)
1 | import org.apache.hudi.DataSourceWriteOptions._ |
验证结果:确实没有限制,所以对于没有必须使用SQL的需求,可以不用修改源码,直接写代码就可以搞定。比如我本次的需求,因为业务逻辑复杂,只能写代码实现,这样即使不修改源码,也可以实现我的需求了。
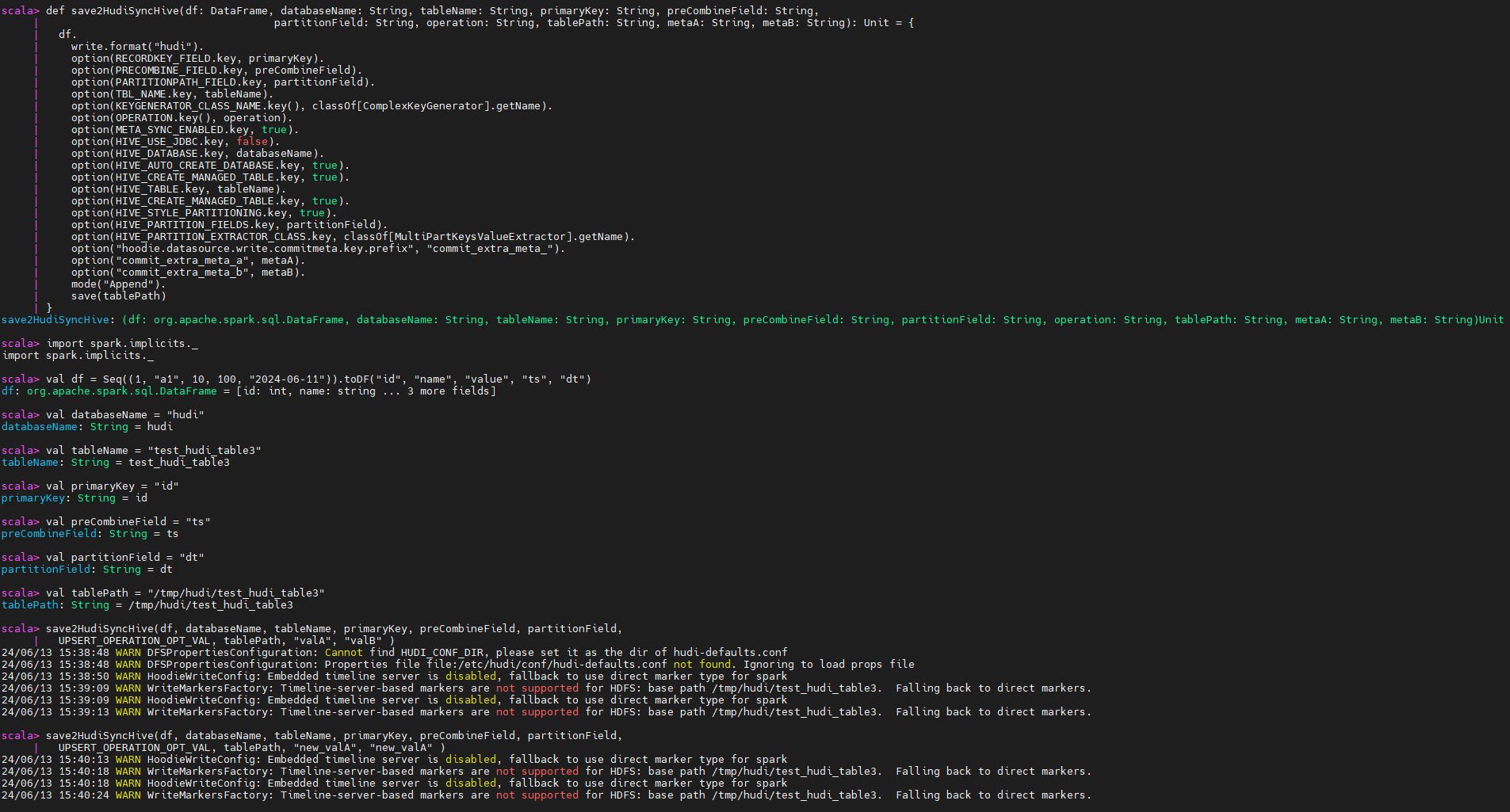
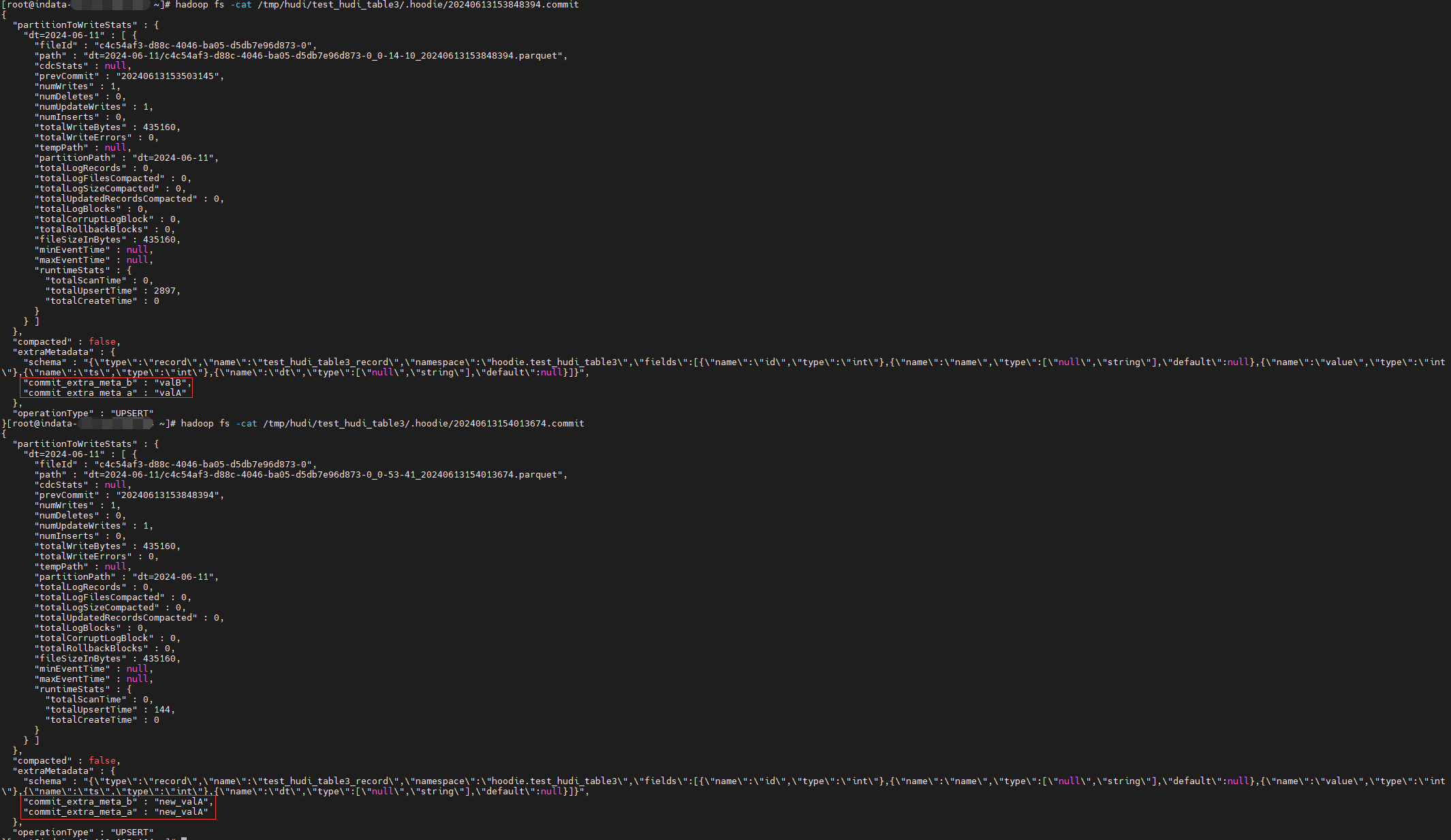
读
前面我们已经成功的写入了 extraMetadata,该怎么获取它的值来使用呢?可以使用 SQL 也可以使用代码获取。本文仅展示简单的使用 show_commit_extra_metadata 来获取 extraMetadata 的值,关于代码实现获取 extraMetadata 以及实现本文开头提及的需求,会在后面的文章单独总结。
1 | spark-sql> call show_commit_extra_metadata(table => 'hudi.test_hudi_table2', metadata_key => 'commit_extra_meta_a'); |



本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文链接:https://dongkelun.com/2024/06/13/hudi/hudiExtraMetadata/
欢迎关注我的公众号