
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
总结Flink通过DataStream API读写Hudi Demo示例,主要是自己备忘用。
- 最开始学习Flink时都是使用Flink SQL,所以对于Flink SQL读写Hudi比较熟悉。但是对于写代码实现并不熟悉,而有些需求是基于Flink代码实现的,所以需要学习总结一下。
- 仅为了实现用代码读写Hudi的需求,其实有两种方式,一种是在代码里通过Flink Table API,也就是代码中执行Flink SQL,这种方式其实和通过SQL实现差不多,另一种方式是通过DataStream API实现。(现实中包括网上教程使用最多的应该是Flink Table API)
- 本文主要是总结DataStream API方式
- DataStream API方式有一种好处是方便IDEA本地调试Hudi源码,便于学习,当然Table API也是可以进行本地调试源码的,但是因为我对Flink SQL源码不熟悉,调试起来比较费劲。Table API调试源码的难点在于我不知道从Flink SQL的源码到Hudi源码的入口在哪,因为这里牵扯到SQL解析的源码,可能比较麻烦(没有研究过)。比如我之前总结的Hudi Spark SQL源码相关的文章:Hudi Spark SQL源码学习总结-Create Table
代码
GitHub地址:https://github.com/dongkelun/hudi-demo/tree/master/hudi0.13_flink1.15
官网地址:https://hudi.apache.org/docs/flink-quick-start-guide/
1 | package com.dkl.hudi.flink; |
- 因为本地连接服务器上的hive比较麻烦,所以本地运行的话,需要把同步hive关掉,如果在服务器上运行,把同步hive的配置项打开就可以了
- 这里的代码和官方文档是差不多的,主要是官方文档没有提供如何构造写Hudi的数据集
DataStream<RowData>,这里给出简单的示例
pom
我在GitHub上提交pom的引用的依赖比较多,是因为在Idea本地调试和在服务器上运行需要的依赖不太一样,本地运行需要的依赖比较多,而且还有很多依赖冲突。如果只需要在服务器上运行,则只需要下面三个依赖:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.15-bundle</artifactId>
<version>${hudi.version}</version>
</dependency>
</dependencies>
github上的依赖既可以在本地进行调试,也可以打包直接在服务器上运行。因为打包时没有将依赖打到包里面,这需要在服务器上面的flink lib下提前配置好相应的jar包。
服务器运行
1 | bin/flink run -c com.dkl.hudi.flink.HudiDemo /opt/dkl/hudi0.13_flink1.15-1.0.jar flink_hudi_dmeo |

本地运行调试
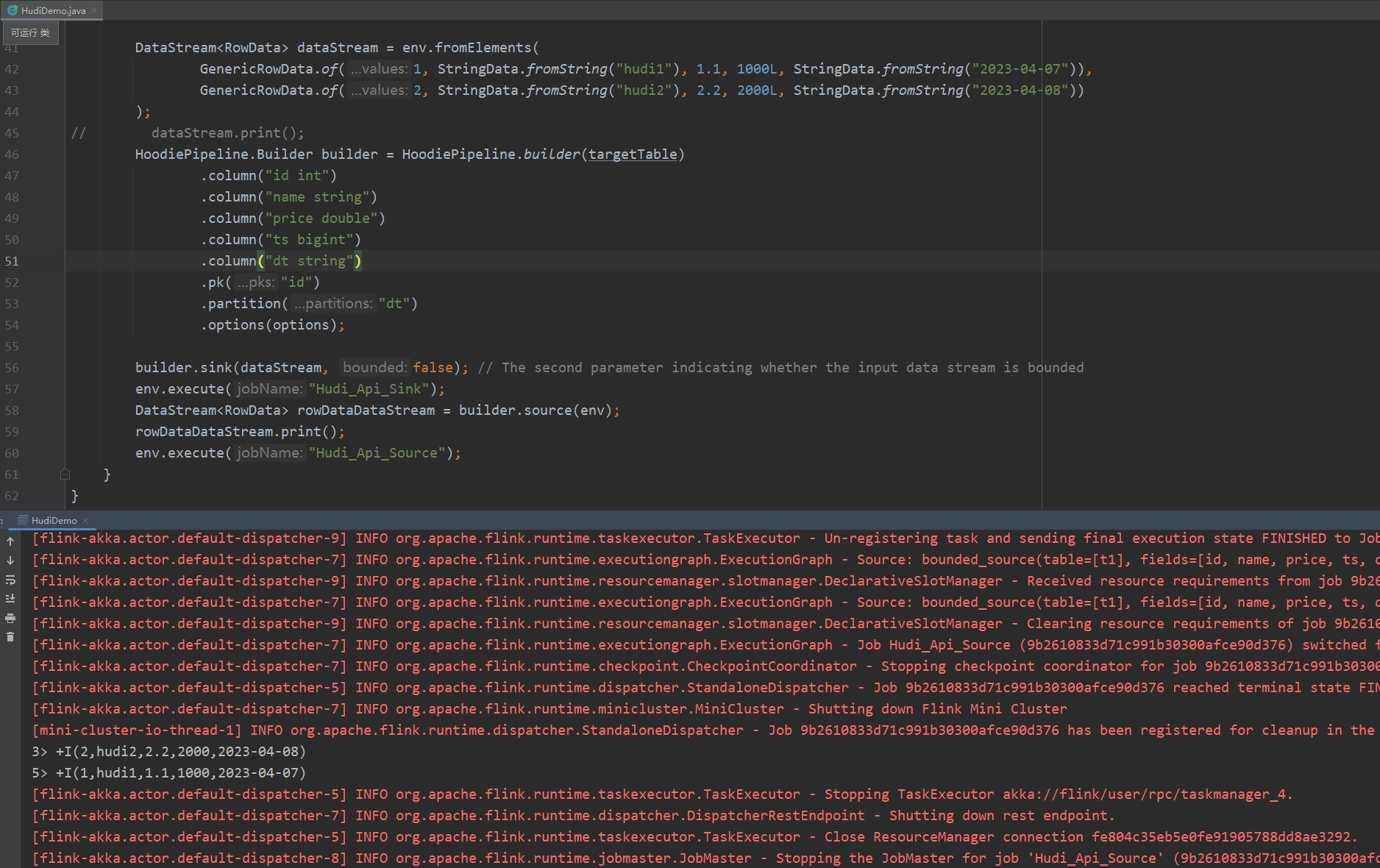
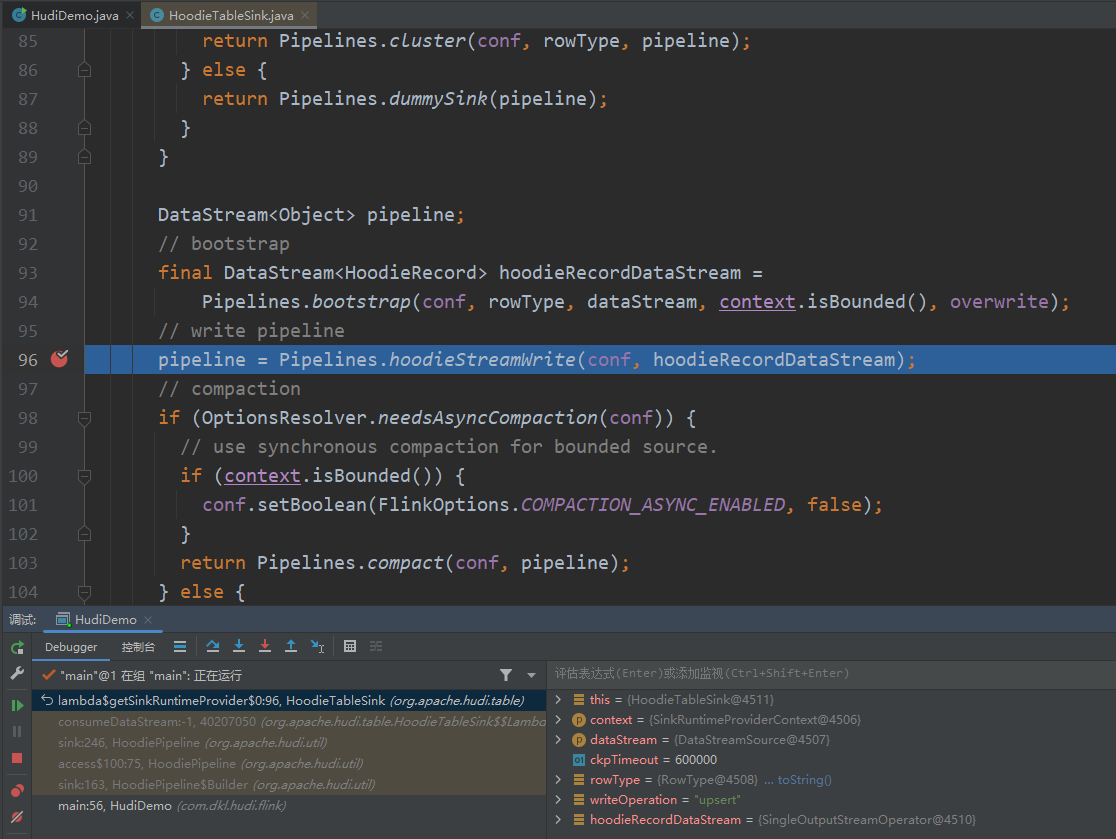


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Flink Hudi DataStream API代码示例
本文链接:https://dongkelun.com/2023/05/22/flinkHudiCode/
欢迎关注我的公众号