
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
记录总结自己第一次如何使用Flink SQL读写Hudi并同步Hive,以及遇到的问题及解决过程。
关于Flink SQL客户端如何使用可以参考:Flink SQL 客户端查询Hive配置及问题解决
版本
Flink 1.14.3
Hudi 0.12.0/0.12.1
本文采用Flink yarn-session模式,不会的可以参考之前的文章。
Hudi包
如果想同步Hive的话,就不能使用上面下载的包了,必须使用profileflink-bundle-shade-hive自己打包,这里参考官网:https://hudi.apache.org/cn/docs/syncing_metastore,打包命令
1 | ## Hive3 |
为了避免不必要的麻烦,最好自己修改一下对应的profile中的Hive版本,比如我们环境的Hive版本为HDP的3.1.0.3.1.0.0-78,我们将hive.version对应的值改为3.1.0.3.1.0.0-78再打包就可以了。
方式1、建在内存中、不同步Hive表
这种建表方式,元数据在内存中,退出SQL客户端后,需要重新建表(表数据文件还在)
建表
1 | CREATE TABLE test_hudi_flink1 ( |
PRIMARY KEY和hoodie.datasource.write.recordkey.field作用相同,联合主键时,可以单独放在最后 PRIMARY KEY (id1, id2) NOT ENFORCED
1 | CREATE TABLE test_hudi_flink1 ( |
Insert
1 | insert into test_hudi_flink1 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'); |
至于upadte和delete可以参考官网:https://hudi.apache.org/cn/docs/flink-quick-start-guide
查询
1 | select * from test_hudi_flink1; |
通过Flink查询出来的结果是没有Hudi的元数据字段的
方式2、建在Hive Catalog中、不同步Hive表
这种建表方式,会在对应的Hive中创建表,好处是,当我们退出SQL客户端后,再重新启动一个新的SQL客户端,我们可以直接使用Hive Catalog中的表,进行读写数据。
建表
1 | CREATE CATALOG hive_catalog WITH ( |
Insert
1 | insert into test_hudi_flink2 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'); |
查询
1 | select * from test_hudi_flink2; |
但是同样地也无法查询Hudi的元数据字段,而且在Hive表中查询此表是会有异常的,因为表结构是这样的:
1 | show create table test_hudi_flink2; |
1 | select * from test_hudi_flink2; |
方式3、建在内存中、同步Hive表
这样建表的好处是,可以利用同步到Hive中的表,通过Hive SQL和Spark SQL查询,也可以利用Spark进行insert、update等,但是Flink SQL客户端退出后,不能利用Hive中的表进行写数据,需要再重新建表
MOR表
建表
配置环境变量HIVE_CONF_DIR1
export HIVE_CONF_DIR=/usr/hdp/3.1.0.0-78/hive/conf
1 | CREATE TABLE test_hudi_flink3 ( |
HIVE_CONF_DIR和hive_sync.conf.dir作用是一样的,如果没有配置hive_sync.conf.dir的话就会取HIVE_CONF_DIR,如果都没有配置,同步会有异常,具体看后面的异常解决。
关于同步Hive的参数,官方文档上说hive_sync.metastore.uris是必须的,但是经过验证,不设置也可以,因为hive_sync.conf.dir下面有hive-site.xml读取里面的配置信息获取即可,Spark SQL同步Hive也是读取hive-site.xml的。其他的参数可以自己去了解
同步表
只有在写数据的时候才会触发同步Hive表
1 | insert into test_hudi_flink3 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'); |
然后我们可以看到在Hive库中生成了两张表test_hudi_flink3_ro、test_hudi_flink3_rt,这和我们使用Spark SQL同步的表是一样的,可以用Hive查询,也可以用Spark查询、写数据
MOR表一开始没有生成parquet文件,在Hive里查询为空(RO、RT都为空),我们可以在SparkSQL里再插入几条数据,就可以查询出数据来了1
2
3# ro、rt都支持Spark SQL insert
insert into test_hudi_flink3_ro values (3,'hudi',10,100,'2022-10-31'),(4,'hudi',10,100,'2022-10-31');
insert into test_hudi_flink3_rt values (5,'hudi',10,100,'2022-10-31'),(6,'hudi',10,100,'2022-10-31');
关于Flink SQL和Spark SQL配置一致性问题:
- hoodie.datasource.write.keygenerator.class 这里设置的为ComplexAvroKeyGenerator,也就是复合主键,原因是Fink SQL 默认值为SimpleKey,但是SparkSQL默认值SqlKeyGenerator,它是ComplexKeyGenerator,也就是默认值为复合主键,但是由于ComplexKeyGenerator在hudi-spark-client中,flink模块没有,所以flink中需要设置hudi-client-common中的ComplexAvroKeyGenerator即可保持一致性(如果keygenerator不一致会导致重复数据)
- hoodie.datasource.write.hive_style_partitioning flink sql默认值为false,但是SparkSQL为true,所以这里设置为true
- hive_sync.partition_extractor_class SparkSQL中默认值为MultiPartKeysValueExtractor,对于本例中的字符串类型的分区字段是支持的,但是Flink SQL中的默认值为SlashEncodedDayPartitionValueExtractor,它要求分区字段必须是日期格式的,所以这里设置为HiveStylePartitionValueExtractor即可解决
- hoodie.allow.operation.metadata.field Flink支持这个配置项,当为true时,Hudi元数据字段中会多一个_hoodie_operation,但是目前Spark还不支持,所以对于这种,对于Flink SQL同步的Hive表,不能再通过Spark SQL写数据,不过后面我会提PR支持
- 我们发现对于Flink的很多配置项key值或者默认值都和Spark或者Hudi Common中不一致,这一点如果需要Flink和Spark配合使用的话,就需要注意保持一致性
COW表
我们来看一下COW表会同步哪些表
建表
1 | CREATE TABLE test_hudi_flink4 ( |
同步表
写数据触发同步Hive表
1 | insert into test_hudi_flink4 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'); |
因为COW表只有RT表,所以不会通过_rt来区分,同步的表名和配置的表名一致。这点可以参考我之前总结的文章Hudi查询类型/视图总结
1 | +----------------------------------------------------+ |
方式4、建在Hive Catalog中、同步Hive表
这样建表的好处是,我们既可以利用Hive Catalog中的表通过Flink SQL写数据,也可以利用同步的Hive表通过Hive SQL查询、Spark SQL读写
MOR表
建表
配置环境变量HIVE_CONF_DIR1
export HIVE_CONF_DIR=/usr/hdp/3.1.0.0-78/hive/conf
1 | CREATE CATALOG hive_catalog WITH ( |
同步表
同样写几条数据触发同步Hive
1 | insert into test_hudi_flink5 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'); |
然后我们可以看到在Hive库中生成了三张表test_hudi_flink4、test_hudi_flink4_ro、test_hudi_flink4_rt,其中test_hudi_flink4是Flink格式的,和上面的方式2中的表结构一样,不能用Hive查询,但是可以在Flink中写数据、查询数据,对于test_hudi_flink4_ro、test_hudi_flink4_rt,我们就可以用Hive查询,也可以用Spark查询、写数据。
COW表
但是对于COW表来说因为同步的表名没有_rt也就是和Hive Catalog表名一样,这样就有问题,所以我们需要区分出Hive Catalog表和同步的表名,一种方式是修改hive_sync.table,另一种方式是Hive Catalog表和同步表保存在不同的Hive Database中,比如下面的示例
1 | CREATE CATALOG hive_catalog WITH ( |
这样Catalog表保存在flink_hudi库中,同步的表保存在hudi库中
1 | insert into test_hudi_flink6 values (1,'hudi',10,100,'2022-10-31'),(2,'hudi',10,100,'2022-10-31'); |
异常解决
记录异常信息及解决方法,由于没有及时整理,顺序可能有点乱
不同步Hive
最开始使用的在maven里下载的包,在Hive里查询发现没有同步表,后来在官网https://hudi.apache.org/cn/docs/syncing_metastore,发现要使用profileflink-bundle-shade-hive自己打包
1 | mvn clean package -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive3 -Dflink1.14 -Dscala-2.12 |
但是用自己的打的包依旧不成功,在Flink SQL客户端没有异常,就很费解,后来发现在Flink yarn-session对应的web界面的Job Manager菜单里能看到具体的日志信息,比如写Hudi的Starting Javalin,这样就好办了,根据具体的异常信息对应解决即可。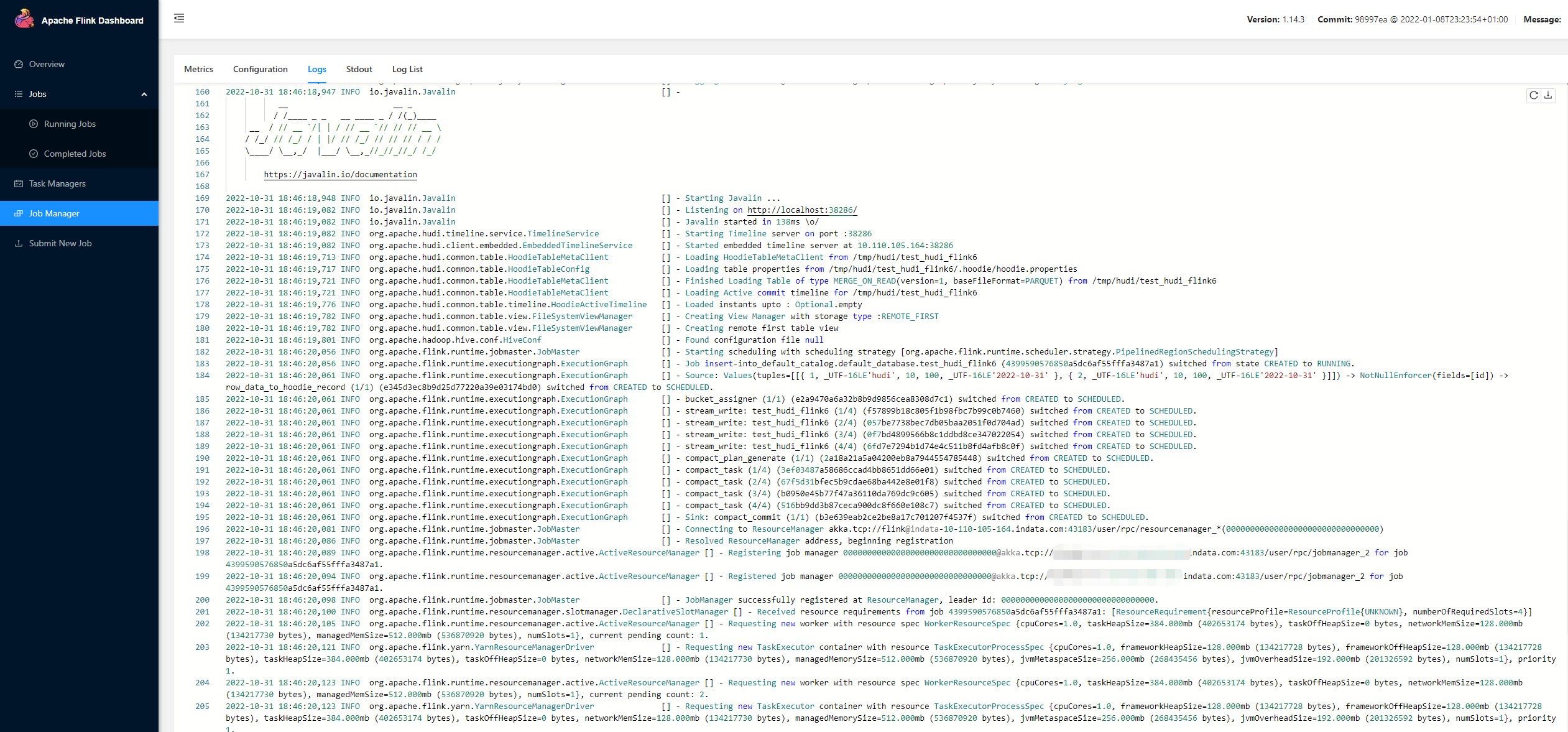
异常1
1 |
|
解决方法:配置环境变量HIVE_CONF_DIR或者配置参数hive_sync.conf.dir,这个问题困扰了我一整天,因为关于这个配置网上没有资料,我是在源码中找到的答案:
1 | public static org.apache.hadoop.conf.Configuration getHiveConf(Configuration conf) { |
异常2
1 | java.lang.NoSuchMethodError: org.apache.parquet.schema.Types$PrimitiveBuilder.as(Lorg/apache/parquet/schema/LogicalTypeAnnotation;)Lorg/apache/parquet/schema/Types$Builder; |
原因是jar包冲突,根据异常信息可知hudi包的org.apache.parquet.schema.Types这个类可能和flink环境下面的其他jar包冲突,经排查,发现hive-exec.jar里也有一样的类名,将该jar包删除,验证问题解决。(在之前的文章中有写到因为缺某些类,才会将hive-exec.jar放到flink下面,现在验证不缺这个类了,如果还有的话,可以找其他没有冲突的包替代)
异常3
1 | Caused by: org.apache.flink.util.FlinkRuntimeException: Failed to start the operator coordinators |
这个异常就是使用在maven下载的包同步hive产生的异常,但是无法在Flink yarn-session对应的web界面看日志,因为yarn-session对应的任务会跑挂掉,我们可以通过下面的命令查看日志信息1
yarn logs -applicationId application_1666247158647_0121
异常4
1 |
|
这个原因是因为yarn-session所用的hudi包和sql-client所用的hudi包版本不一致,改为一致即可
其他异常
比如缺相关依赖包异常,去环境上Hive路径下拷贝对应的jar包到Flink路径下即可
总结
本文记录了自己使用Flink SQL读写Hudi表并同步Hive的一些配置,并且做了Flink SQL和Spark SQL的一致性配置。其实关于Flink SQL读写Hudi还有一个HoodieHiveCatalog也可以使用,有时间等我研究明白了,再分享给大家。
相关阅读


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Flink SQL操作Hudi并同步Hive使用总结
本文链接:https://dongkelun.com/2022/10/31/hudiFlinkSql/
欢迎关注我的公众号