
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
记录博主第一次使用Flink SQL查询Hive的配置以及问题解决过程
博主目前还没有用过Flink,没有写过Flink代码,完全是一个小白。之所以使用Flink,是因为博主目前需要测试使用dolphinscheduler的一些功能,其中包括Flink数据源,这里Flink数据源我们使用的是Kyuubi Flink Engine,且学会、了解了Flink之后对于学习Hudi、Kyuubi也是有帮助的。
版本
flink-1.14.3,这里使用kyuubi1.5.2自带的Flink
环境
HDP环境,Hadoop、Hive等已经安装配置好
配置
HADOOP_CLASSPATH
1 | export HADOOP_CLASSPATH=`hadoop classpath` |
可以添加在比如/ect/profile里,这样等于修改全局的环境,如果想只对Flink生效,可以添加在bin/config.sh文件里
一开始我对
hadoop classpath理解错了,以为是自己手动修改成实际的路径,但是hadoop对应的jar包的路径有很多,后来发现它的意思是执行命令hadoop classpath将返回值赋给HADOOP_CLASSPATH
1 | hadoop classpath |
jar包
flink-connector-hive 下载地址:https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.14.3/,对应flink-connector-hive_2.12-1.14.3.jarhive-exec: 从$HIVE_HOME/lib拷贝即可: hive-exec-3.1.0.3.1.0.0-78.jarlibfb303: 从$HIVE_HOME/lib拷贝即可:libfb303-0.9.3.jar
将这几个包放到 $FLINK_HOME/lib
提交模式
Flink具有多种提交方式,比如:常用的local模式,stantalone模式,yarn模式,k8s等。sql client 默认为stantalone模式,我们可以根据自己的需求选择对应的模式
stantalone
这是默认的模式,什么配置参数都不用修改,不过stantalone模式,需要先使用bin/start-cluster.sh命令启动stantalone集群
停止stantalone集群:bin/stop-cluster.sh
yarn-per-job
修改flink-conf.yaml
添加:1
execution.target: yarn-per-job
yarn-session
启动yarn-session
1 | bin/yarn-session.sh -nm flink-sql -d |
相关参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21bin/yarn-session.sh -h
Usage:
Optional
-at,--applicationType <arg> Set a custom application type for the application on YARN
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution mode.
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
停止yarn-session
1 | In order to stop Flink gracefully, use the following command: |
配置flink-conf.yaml
成功启动yarn-session后,可以在yarn ui界面看到 (点击Tracking UI中的 ApplicationMaster,可以进入到flink的管理界面)
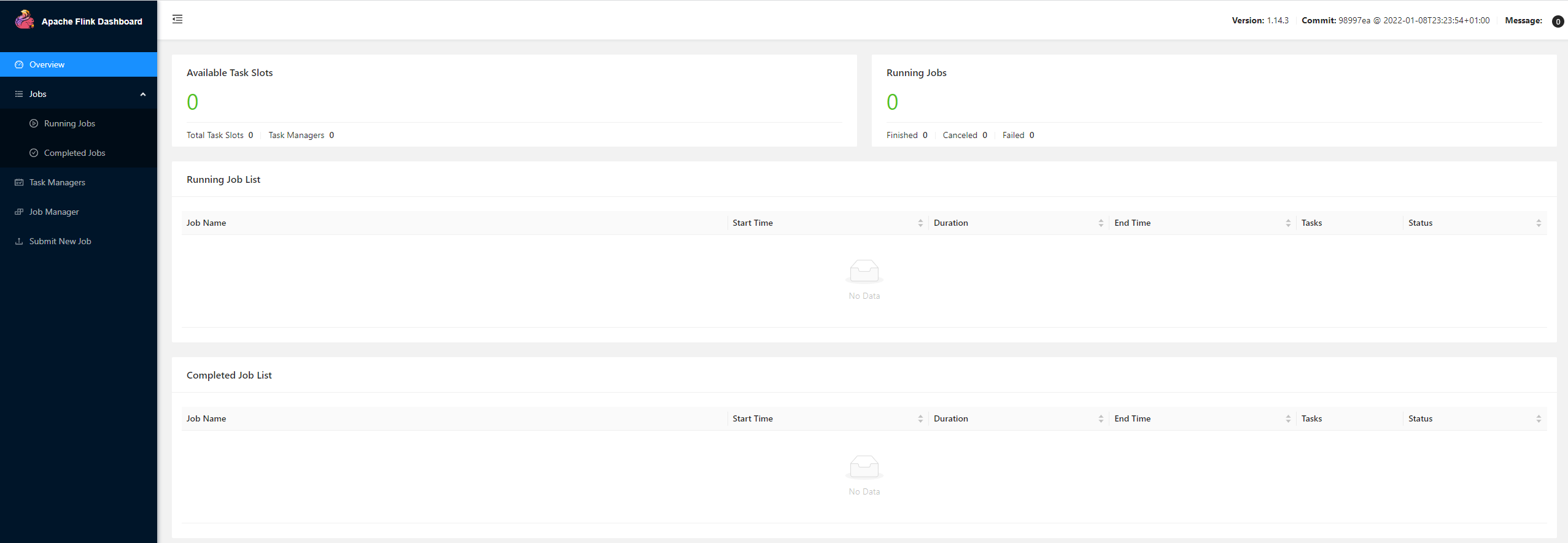
除了要修改execution.target为yarn-session外,还要添加yarn.application.id,值为yarn对应的id1
2execution.target: yarn-session
yarn.application.id: application_1661394335976_0013
启动 sql 客户端
1 | bin/sql-client.sh |
创建 hive catalog
1 | CREATE CATALOG hive_catalog WITH ( |
1 | Flink SQL> show catalogs; |
切换 catalog
1 | use catalog hive_catalog; |
查询Hive表
1 | Flink SQL> show tables; |
1 | select * from test_hive_table; |

如果是yarn-session模式,我们可以在flink的管理界面看到对应的job信息: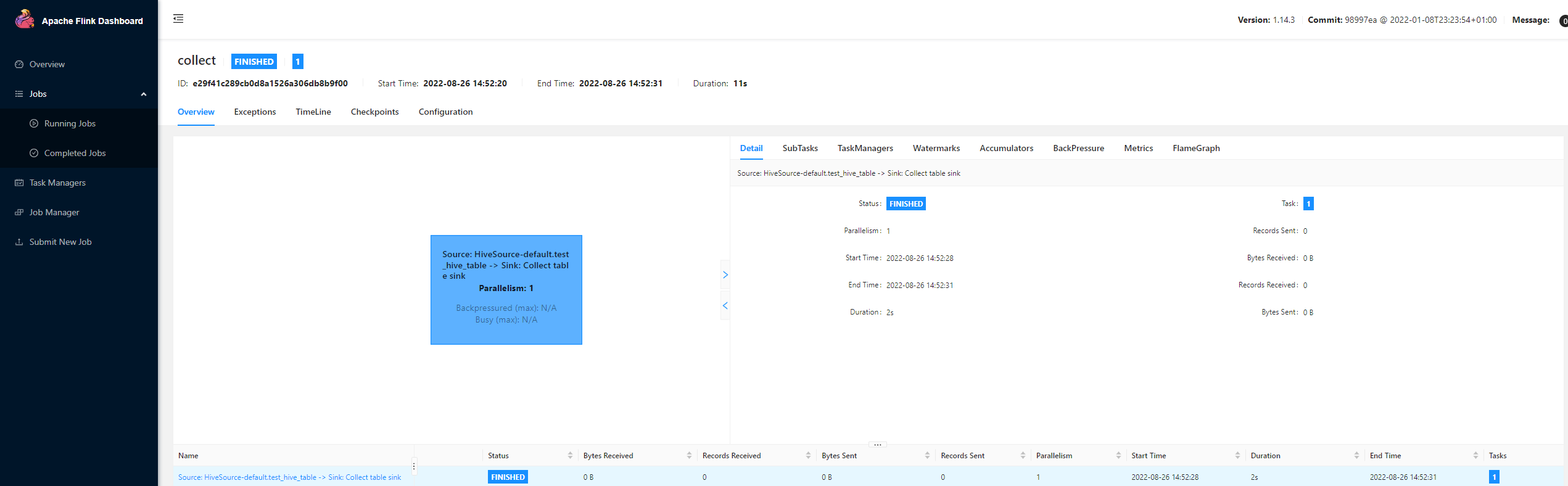
创建Hive表
1 | set table.sql-dialect = hive; #使用hive方言 |
insert
1 | insert into test_hive_table_flink values(1,'flink'); |
1 | select * from test_hive_table_flink; |
hive 查看表结构
1 | show create table test_hive_table_flink; |
drop 表
1 | drop table test_hive_table_flink; |
问题解决
记录问题解决过程
缺hadoop相关包
创建Hive catalog时1
2[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream
解决方法:1
export HADOOP_CLASSPATH=`hadoop classpath`
缺Hive相关包
1 | [ERROR] Could not execute SQL statement. Reason: |
解决方法:hive-exec: 从$HIVE_HOME/lib拷贝即可: hive-exec-3.1.0.3.1.0.0-78.jar
1 | [ERROR] Could not execute SQL statement. Reason: |
这个异常,在sql客户度看不到详细的信息,不知道缺哪个包
解决方法,查看日志:log/flink-root-sql-client-*.log,找到对应异常
1 | Caused by: org.apache.flink.table.catalog.exceptions.CatalogException: Failed to create Hive Metastore client |
根据 com/facebook/fb303/FacebookService$Iface 查找对应的jar包:
libfb303: 从$HIVE_HOME/lib拷贝即可:libfb303-0.9.3.jar,参考:https://blog.csdn.net/skdtr/article/details/123513628
yarn-session没有配置applicationId
1 | [ERROR] Could not execute SQL statement. Reason: |
根据异常信息无法判断原因,查找yanr-session相关资料,发现缺少配置:
1 | yarn.application.id: application_1661394335976_0013 |
yarn-session缺少MapReduce jar包
1 | [ERROR] Could not execute SQL statement. Reason: |
具体表现为yarn-session能够启动成功,但是在执行sql时报上面的错误,所以一开始并不会想到之和yarn-session服务有关,因为在其他模式通过设置了HADOOP_CLASSPATH之后是可以正常执行查询sql的,最后才想到是不是和yarn-session服务有关
解决方法:
将 hadoop-mapreduce-client-core-3.1.1.3.1.0.0-78.jar 拷贝到 flink/lib目录下,并重启yarn-session,这里注意重启yarn-session后需要同步更新yarn.application.id的值,然后验证sql果然没有问题了
缺antlr-runtime包
具体是使用hive 方言建表时:
1 | Exception in thread "main" org.apache.flink.table.client.SqlClientException: Unexpected exception. This is a bug. Please consider filing an issue. |
解决方法:
将$HIVE_HOME/lib下的antlr-runtime-3.5.2.jar拷贝至flink/lib


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Flink SQL 客户端查询Hive配置及问题解决
本文链接:https://dongkelun.com/2022/08/26/flinkSqlClientQueryHive/
欢迎关注我的公众号