
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
上一篇文章Hudi Spark源码学习总结-spark.read.format(“hudi”).load分析了load方法直接查询Hudi表路径的源码逻辑,那么Spark SQL select 表名的方式和load最终走的逻辑是一样的吗?本文带着这个疑问来分析一下select查询Hudi表的源码逻辑
版本
Spark 2.4.4
Hudi master 0.12.0-SNAPSHOT 最新代码
(可以借助Spark3 planChangeLog 打印日志信息查看哪些规则生效,Spark3和Spark2生效的规则大致是一样的)
示例代码
先Create Table,再Insert几条数据
1 | spark.sql(s"select id, name, price, ts, dt from $tableName").show() |
打印执行计划
同样的我们也可以先打印一下计划,方便我们分析
1 | == Parsed Logical Plan == |
根据打印信息我们看到,parsing阶段返回的是Project(UnresolvedRelation),analysis阶段将子节点UnresolvedRelation转变为了SubqueryAlias(Relation),最后的planning和load一样返回flleScan,Location 也为HoodieFileIndex,我们只需要将这些关键点搞明白就可以了
spark.sql
1 | def sql(sqlText: String): DataFrame = { |
前面的文章讲过了,parsePlan对应的为parsing阶段,根据打印信息我们知道parsePlan的返回值为1
2'Project ['id, 'name, 'price, 'ts, 'dt]
+- 'UnresolvedRelation `h0`
让我们来看一下它是如何返回的
parsing
singleStatement
根据文章Hudi Spark SQL源码学习总结-Create Table的逻辑,可知select对应Spark源码里的SqlBase.g4(即Hudi g4文件中没有重写select),那么parsePlan方法最终走到AbstractSqlParser.parsePlan
1 | override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser => |
因为select 对应的嵌套逻辑比较复杂,我们可以利用IDEA里的ANTLR插件测试一下singleStatement对应的规则,我们只需要输入对应的sql,就可以得到它的parse tree
安装插件
Test Rule singleStatement
将鼠标放到singleStatement处,右键点击 Test Rule singleStatement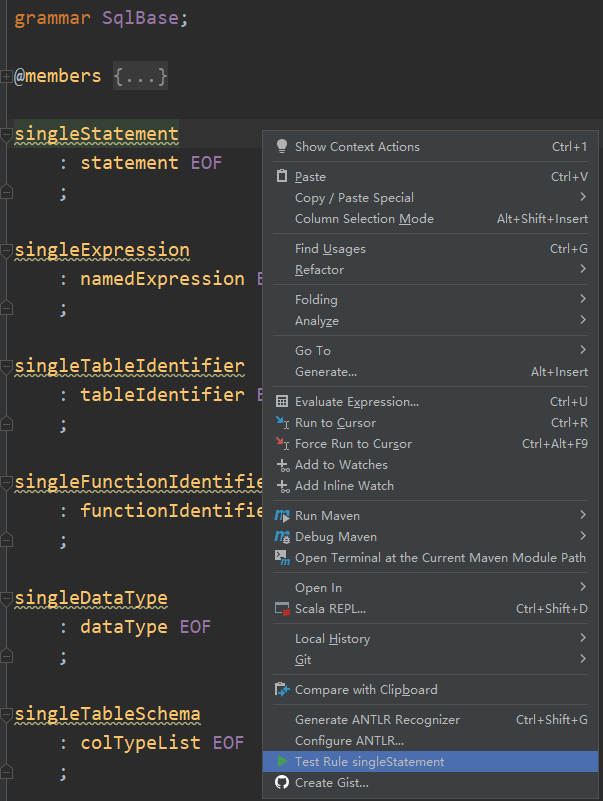
输入sql
输入sqlSELECT ID, NAME, PRICE, TS, DT FROM H0,这里需要大写才能识别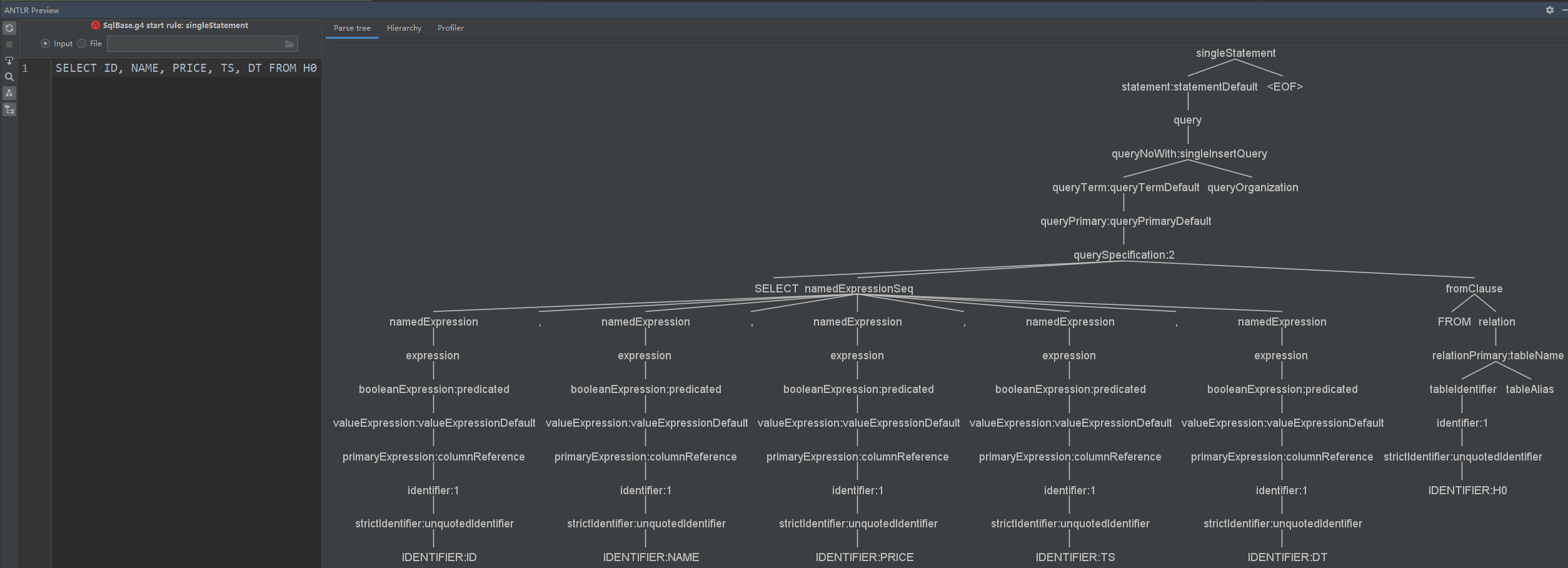
根据得到的parseTree,我们就知道g4文件中对应的大概逻辑了
1 | singleStatement |
但是逻辑还是比较复杂,我可以在IDEA了调试一下,看看ctx.statement的值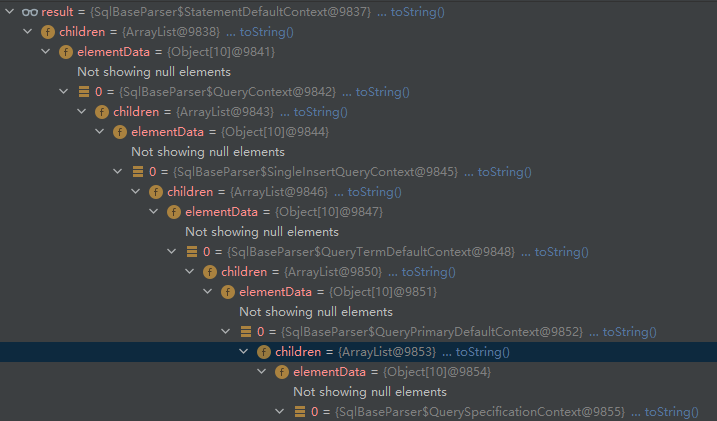
主要代码
对应的主要代码为:
StatementDefaultContext
1 | public <T> T accept(ParseTreeVisitor<? extends T> visitor) { |
QueryContext1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQuery(this);
else return visitor.visitChildren(this);
}
override def visitQuery(ctx: QueryContext): LogicalPlan = withOrigin(ctx) {
val query = plan(ctx.queryNoWith)
// Apply CTEs
query.optional(ctx.ctes) {
val ctes = ctx.ctes.namedQuery.asScala.map { nCtx =>
val namedQuery = visitNamedQuery(nCtx)
(namedQuery.alias, namedQuery)
}
// Check for duplicate names.
checkDuplicateKeys(ctes, ctx)
With(query, ctes)
}
}
plan1
2
3
4protected def plan(tree: ParserRuleContext): LogicalPlan = typedVisit(tree)
protected def typedVisit[T](ctx: ParseTree): T = {
ctx.accept(this).asInstanceOf[T]
}
SingleInsertQueryContext1
2
3
4
5
6
7
8
9
10
11
12public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitSingleInsertQuery(this);
else return visitor.visitChildren(this);
}
override def visitSingleInsertQuery(
ctx: SingleInsertQueryContext): LogicalPlan = withOrigin(ctx) {
plan(ctx.queryTerm).
// Add organization statements.
optionalMap(ctx.queryOrganization)(withQueryResultClauses).
// Add insert.
optionalMap(ctx.insertInto())(withInsertInto)
}
QueryTermDefaultContext1
2
3
4public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQueryTermDefault(this);
else return visitor.visitChildren(this);
}
QueryPrimaryDefaultContext1
2
3
4public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQueryPrimaryDefault(this);
else return visitor.visitChildren(this);
}
QuerySpecificationContext1
2
3
4public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQuerySpecification(this);
else return visitor.visitChildren(this);
}
1 | override def visitQuerySpecification( |
1 | override def visitQuerySpecification( |
visitFromClause1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 * Create a logical plan for a given 'FROM' clause. Note that we support multiple (comma
* separated) relations here, these get converted into a single plan by condition-less inner join.
*/
override def visitFromClause(ctx: FromClauseContext): LogicalPlan = withOrigin(ctx) {
val from = ctx.relation.asScala.foldLeft(null: LogicalPlan) { (left, relation) =>
// relation为RelationContext
// relation.relationPrimary为TableNameContext
val right = plan(relation.relationPrimary)
val join = right.optionalMap(left)(Join(_, _, Inner, None))
withJoinRelations(join, relation)
}
if (ctx.pivotClause() != null) {
if (!ctx.lateralView.isEmpty) {
throw new ParseException("LATERAL cannot be used together with PIVOT in FROM clause", ctx)
}
withPivot(ctx.pivotClause, from)
} else {
ctx.lateralView.asScala.foldLeft(from)(withGenerate)
}
}
TableNameContext1
2
3
4
5
6
7
8
9
10
11
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitTableName(this);
else return visitor.visitChildren(this);
}
override def visitTableName(ctx: TableNameContext): LogicalPlan = withOrigin(ctx) {
val tableId = visitTableIdentifier(ctx.tableIdentifier)
val table = mayApplyAliasPlan(ctx.tableAlias, UnresolvedRelation(tableId))
table.optionalMap(ctx.sample)(withSample)
}
最终是通过withQuerySpecification的createProject方法返回的Project(namedExpressions, withFilter),其中的withFilter是通过visitFromClause返回的UnresolvedRelation(tableId),所以在parsing阶段返回1
2'Project ['id, 'name, 'price, 'ts, 'dt]
+- 'UnresolvedRelation `h0`
analysis
ResolveRelations
它的子节点为UnresolvedRelation,会匹配到第二个,调用resolveRelation
1 | def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp { |
resolveRelation
因为我们没有指定database,所以isRunningDirectlyOnFiles返回false,匹配到第一个
1 | def resolveRelation(plan: LogicalPlan): LogicalPlan = plan match { |
lookupTableFromCatalog
1 | private def lookupTableFromCatalog( |
lookupRelation
返回SubqueryAlias(table, db, UnresolvedCatalogRelation(metadata))
1 | def lookupRelation(name: TableIdentifier): LogicalPlan = { |
FindDataSourceTable
上面讲了在ResolveRelations返回UnresolvedCatalogRelation,所以匹配到第三个,调用readDataSourceTable
1 | override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators { |
readDataSourceTable
1 | private def readDataSourceTable(table: CatalogTable): LogicalPlan = { |
dataSource.resolveRelation
这里的providingClass我们在前面的几篇文章中讲过了,它是Spark2DefaultDatasource,这里会模式匹配到第一个
1 | def resolveRelation(checkFilesExist: Boolean = true): BaseRelation = { |
Spark2DefaultDatasource.createRelation
后面的就和我们之前讲的load方法一样了,返回值为HadoopFsRelation(HoodieFileIndex,),所以readDataSourceTable返回LogicalRelation(HadoopFsRelation(HoodieFileIndex,))
1 | override def createRelation(sqlContext: SQLContext, |
optimization 和 planning
optimization 和 planning是在show方法中触发的(只适用于查询),因为前面返回的和load方法返回值一样(有一点不同的是多了一层Project,不过后面会遍历子节点),所以后面的逻辑也和load一样了,大致逻辑 show->showString->getRows->->select Project包装->take->limit->GlobalLimit->withAction->planner.plan->SpecialLimits->CollectLimitExec->FileSourceStrategy->ProjectExec(projectList,FileSourceScanExec(HadoopFsRelation)))->CollapseCodegenStages->WholeStageCodegenExec->collectFromPlan->executeCollect->executeTake->getByteArrayRdd->doExecute->inputRDDs->FileSourceScanExec.inputRDD->createNonBucketedReadRDD->selectedPartitions->HoodieFileIndex.listFiles
总结
通过上面的分析,我们发现Spark查询Hudi表不管是通过load的方式还是通过sql select的方法最终走的逻辑都是一样的。都是先查找source=hudi的DataSource,Spark2对应的为Spark2DefaultDatasource,然后通过Spark2DefaultDatasource的createRelation创建relation,如果使用HadoopFsRelation,则最终调用HoodieFileIndex.listFiles实现hudi自己的查询逻辑,如果使用BaseFileOnlyRelation,则最终调用HoodieBaseRelation.buildScan实现查询Hudi的逻辑,不同点只是入口不同,load是在load函数中查找DataSource,然后在loadV1Source方法中resolveRelation继而createRelation,而sql select的入口则是先通过parsing返回UnresolvedRelation,再在analysis阶段通过规则ResolveRelations和FindDataSourceTable实现创建relation的
相关阅读
- Hudi Spark SQL源码学习总结-Create Table
- Hudi Spark SQL源码学习总结-CTAS
- Hudi Spark源码学习总结-df.write.format(“hudi”).save
- Hudi Spark源码学习总结-spark.read.format(“hudi”).load
- Hudi Spark源码学习总结-spark.read.format(“hudi”).load(2)


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Hudi Spark SQL源码学习总结-select(查询)
本文链接:https://dongkelun.com/2022/08/15/hudiSparkSqlSourceCodeLearning-select/
欢迎关注我的公众号