
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
记录Spark3.1.2+Kyuubi1.5.2从源码打包到部署配置过程,虽然之前总结过一篇Kyuubi配置的文章:Kyuubi 安装配置总结,但是这次和之前还是有不同的:
- 1、Kyuubi版本升级 当时最新版本1.4.0,现在要升级到最新版1.5.2,并且1.4.0打包的时候很快完成没有任何问题,1.5.2打包时比较慢,且遇到了比较棘手的问题,这里记录一下解决过程
- 2、当时没有配置Spark的权限,虽然之前总结了一篇利用Submarin集成Spark-Ranger,但是这次用的不是Submarin,用的是kyuubi自带的kyuubi-spark-authz插件,而且解决了当时没有解决的问题,正好更新一下,之所以不用submarin,是因为submarin在新版本已经被去掉了,不再维护,而kyuubi-spark-authz和submarin的作者是同一个人,且kyuubi一直在维护,即使有问题也可以在社区提问题解决,这样还少学习配置一个组件,减少了维护成本
配置
先讲完整的配置,再讲如何编译打包
Spark3.1.2
前提:我的环境上有一个ambari自带的Spark2.4.5,路径/usr/hdp/3.1.0.0-78/spark2/
解压Spark3.1.2的tgz包,将其放到路径 /opt/hdp(新建临时目录),并改名为spark3,然后拷贝之前spark2的配置到spark3的配置目录中,已经存在的模板,输入no不用覆盖1
cp /usr/hdp/3.1.0.0-78/spark2/conf/* /opt/hdp/spark3/conf/
如果是在windows上自己打的包,传到服务器Linux上可能存在编码不一致问题,执行一下命令:
1 | yum install -y dos2unix |
这里因为有一个Spark2版本了,所以不配置环境变量,直接使用全路径验证测试
验证
1、验证测试用例SparkPi1
/opt/hdp/spark3/bin/spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi --principal spark/indata-10-110-105-164.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab /opt/hdp/spark3/examples/jars/spark-examples_2.12-3.1.2.jar
正确输出1
Pi is roughly 3.1389356946784734
2、验证spark-shell,登录成功,可以成功的读取hive表中数据即可1
2/opt/hdp/spark3/bin/spark-shell --principal spark/indata-10-110-105-164.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab
spark.sql("select * from test").show
3、验证Spark Thrfit server1
2
3
4
5/opt/hdp/spark3/bin/spark-submit --master yarn --deploy-mode client --executor-memory 2G --num-executors 3 --executor-cores 2 --driver-memory 3G --driver-cores 2 --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name spark3-thrift-server --hiveconf hive.server2.thrift.http.port=20003 --principal spark/indata-10-110-105-164.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab
/opt/hdp/spark3/bin/beeline -u "jdbc:hive2://10.110.105.164:20003/default;principal=HTTP/indata-10-110-105-164.indata.com@INDATA.COM?hive.server2.transport.mode=http;hive.server2.thrift.http.path=cliservice"
select * from test
简单的验证成功后,就可以认为我们编译安装的Spark3没有问题
kyuubi-spark-authz
kyuubi-spark-authz,在最新发布的1.5.2版本并没有,我们需要拉取master分支(1.6.0-SNAPSHOT)的代码,自己打包,这里ranger版本为1.2.0
1 | mvn clean package -pl :kyuubi-spark-authz_2.12 -Dspark.version=3.1.2 -Dranger.version=1.2.0 -DskipTests |
打包完成后,需要将 /incubator-kyuubi/extensions/spark/kyuubi-spark-authz/target/scala-2.12/jars/* 和 /incubator-kyuubi/extensions/spark/kyuubi-spark-authz/target/kyuubi-spark-authz_2.12-1.6.0-SNAPSHOT.jar两个路径下的包拷贝到我们上面安装的spark3/jars目中,具体为/opt/hdp/spark3/jars/
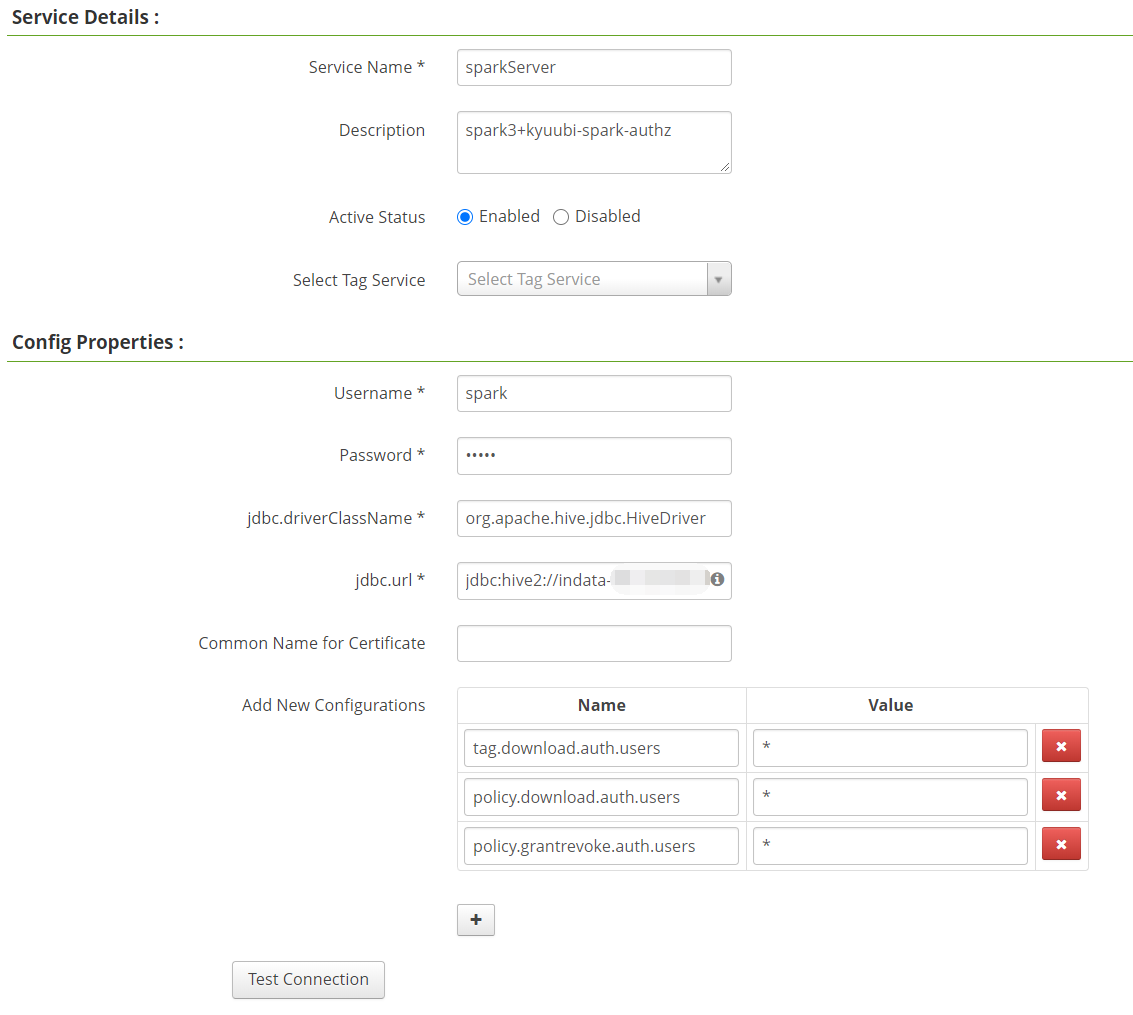
配置ranger策略
和之前的文章利用Submarin集成Spark-Ranger一样,添加sparkServer策略,用户名密码随便填写,需要注意的是下面三个key对应的value值需要填写*
1 | tag.download.auth.users |
之前讲的是必须填spark,这样就造成了为啥spark用户没有问题,而其他用户有问题,然后保留两个all-database,table,column,一个对应spark用户,只有hudi库权限,一个hive用户,只有default库权限

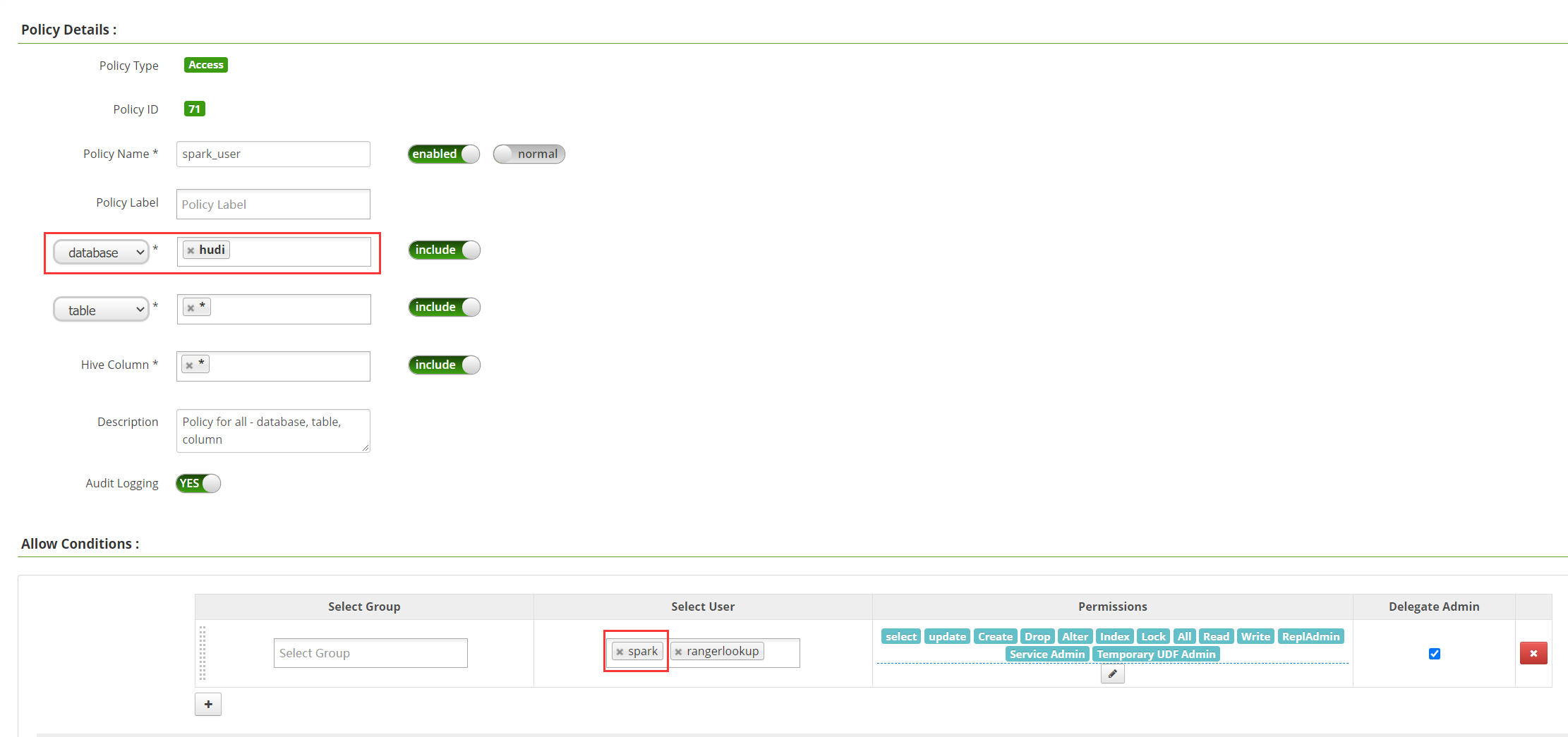
配置spark
根据官网文档,在$SPARK_HOME/conf创建下面两个配置文件
ranger-spark-security.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28<configuration>
<property>
<name>ranger.plugin.spark.policy.rest.url</name>
<value>http://yourIp:16080</value>
</property>
<property>
<name>ranger.plugin.spark.service.name</name>
<value>sparkServer</value>
</property>
<property>
<name>ranger.plugin.spark.policy.cache.dir</name>
<value>/etc/ranger/sparkServer/policycache</value>
</property>
<property>
<name>ranger.plugin.spark.policy.pollIntervalMs</name>
<value>30000</value>
</property>
<property>
<name>ranger.plugin.spark.policy.source.impl</name>
<value>org.apache.ranger.admin.client.RangerAdminRESTClient</value>
</property>
</configuration>
ranger-spark-audit.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43<configuration>
<property>
<name>xasecure.audit.is.enabled</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db</name>
<value>false</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.driver</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.url</name>
<value>jdbc:mysql://yourIp:3306/ranger</value>
</property>
<property>
<name>xasecure.audit.destination.db.password</name>
<value>ranger</value>
</property>
<property>
<name>xasecure.audit.destination.db.user</name>
<value>ranger</value>
</property>
<property>
<name>xasecure.audit.jaas.Client.option.keyTab</name>
<value>/etc/security/keytabs/hive.service.keytab</value>
</property>
<property>
<name>xasecure.audit.jaas.Client.option.principal</name>
<value>hive/_HOST@INDATA.COM</value>
</property>
</configuration>
至于具体的ip、端口、用户名、密码信息可以在之前已经配置好的hive-ranger插件配置文件里查看,也可以在ambari界面搜索
需要注意的是16080端口对应的地址可能填ip有问题,需要填写ip对应的域名hostname,具体取决于自己的环境配置
验证
验证spark用户
1 | /opt/hdp/spark3/bin/spark-sql --master yarn --deploy-mode client --conf 'spark.sql.extensions=org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension' --principal spark/indata-10-110-105-164.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab |
没有default权限:1
2
3use default;
Permission denied: user [spark] does not have [_any] privilege on [default]
hudi库可以正常读取1
2use hudi;
show tables;

验证hive用户
切换hive认证用户1
/opt/hdp/spark3/bin/spark-sql --master yarn --deploy-mode client --conf 'spark.sql.extensions=org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension' --principal hive/indata-10-110-105-164.indata.com@INDATA.COM --keytab /etc/security/keytabs/hive.service.keytab
default库可以正常读取:1
2use default;
show tables;
没有Hudi库权限1
2
3use hudi;
Permission denied: user [hive] does not have [_any] privilege on [hudi]

支持hudi
首先将对应版本的Hudi包,拷贝到/opt/hdp/spark3/jars/,这里用的版本为:hudi-spark3.1.2-bundle_2.12-0.10.1.jar
1 | /opt/hdp/spark3/bin/spark-sql --master yarn --deploy-mode client --conf 'spark.sql.extensions=org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension,org.apache.spark.sql.hudi.HoodieSparkSessionExtension' --principal spark/indata-10-110-105-164.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab |
1 | use hudi; |
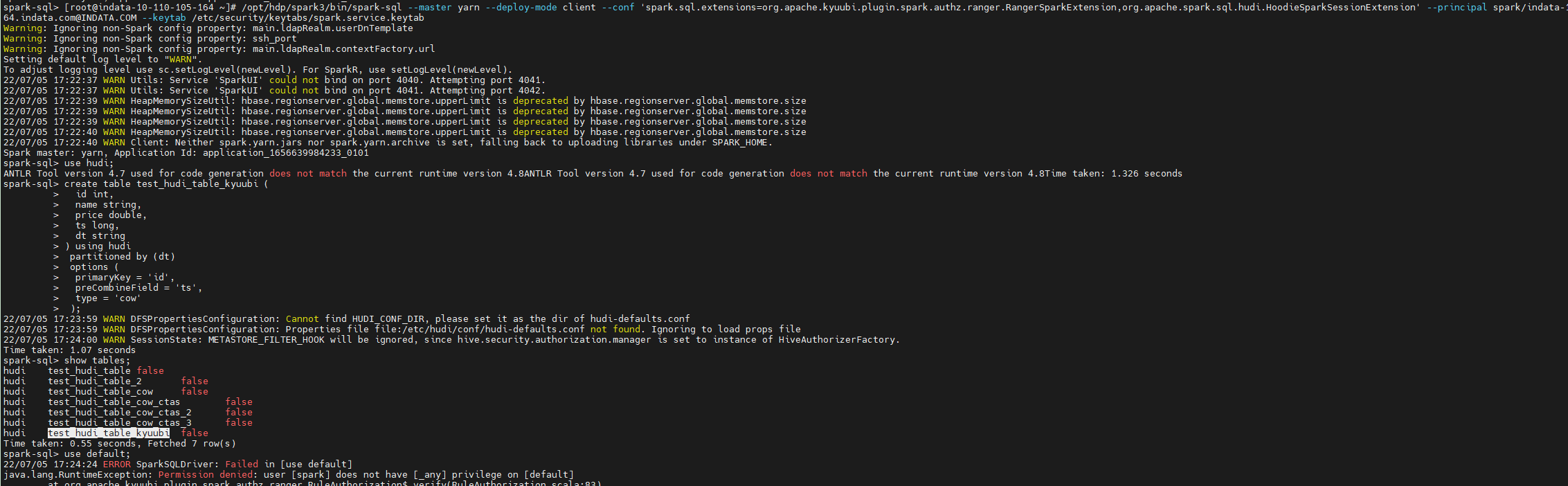
kyuubi1.5.2
目前最新版为1.5.2,但是默认spark版本为spark3.2.1,和我们的spark3.1.2大版本不一样,为了避免潜在问题,我们选择自己打包,打包流程在后面的部分,打包完成后,将其上传到服务器并解压到/opt/hdp/kyuubi-1.5.2/
配置kyuubi
dos2unix kyuubi-1.5.2/bin/*
kyuubi-env.sh
和之前的文章一样的配置1
2
3
4export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
export SPARK_HOME=/opt/hdp/spark3
export HADOOP_CONF_DIR=/usr/hdp/3.1.0.0-78/hadoop/etc/hadoop
export KYUUBI_JAVA_OPTS="-Xmx10g -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=4096 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseCondCardMark -XX:MaxDirectMemorySize=1024m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -Xloggc:./logs/kyuubi-server-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=5M -XX:NewRatio=3 -XX:MetaspaceSize=512m"
kyuubi-defaults.conf
和之前1.4.0版本不同的是加了一个配置kyuubi.ha.zookeeper.publish.configs true,不配置的话beeline连接HA的时候有问题,另外还改了端口号和zookeeper的namespace,因为一个环境上有多个版本的kyuubi,避免冲突
1 | kyuubi.frontend.bind.host indata-10-110-105-164.indata.com |
验证
启动kyuubi
1 | bin/kyuubi start |
连接HA
1 | /opt/hdp/spark3/bin/beeline |
集成kyuubi-spark-authz
上面讲了用原生的spark-sql集成kyuubi-spark-authz,那么通过kyuubi怎么集成呢?有两种方法,一种是在jdbc连接串里,通过spark.sql.extensions扩展org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension
!connect jdbc:hive2://indata-10-110-105-162.indata.com,indata-10-110-105-163.indata.com,indata-10-110-105-164.indata.com/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi1.5.2;hive.server2.proxy.user=spark#spark.sql.extensions=org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension
另一种是通过配置spark的默认值,既然我们要用ranger来控制权限,那么所有的连接应该都要控制,所以通过修改spark默认值来统一配置比较合理
1 | vi /opt/hdp/spark3/conf/spark-defaults.conf |
需要将之前启动的提交到yarn的spark程序kill掉,然后重新连接验证
同时支持hudi
和原生spark-sql类似,通过逗号分隔扩展多个,但是不能一个通过配置文件配置,一个通过jdbc参数配置,经验证,如果在配置文件里配置了RangerSparkExtension,而通过jdbc参数配置了HoodieSparkSessionExtension,那么jdbc参数配置的会覆盖掉配置文件配置的,所以只能配置一个,建议在配置文件里同时扩展两个
1 | spark-defaults.conf |
如果有和默认配置不一样的需求的话,可以在jdbc参数里修改配置覆盖掉默认配置,但是在项目上给用户用的话,这个参数不应该暴露给用户使用,而是应该规定死的
优化Spark启动时间
通过连接Kyuubi第一次启动Spark程序时,会比较慢,我们可以通过配置spark.yarn.archive或者spark.yarn.jars(二选一),来优化启动时间
创建archive(spark.yarn.archive)
1 | jar cv0f spark-libs.jar -C $SPARK_HOME/jars/ . |
上传jar包到hdfs
spark.yarn.archive:1
hdfs dfs -put ./spark-libs.jar /hdp/apps/3.1.0.0-78/spark3/
spark.yarn.jars:1
hdfs dfs -put $SPARK_HOME/jars /hdp/apps/3.1.0.0-78/spark3/
配置 spark-defaults.conf
添加参数:1
2spark.yarn.archive hdfs://cluster1/hdp/apps/3.1.0.0-78/spark3/spark-libs.jar
#spark.yarn.jars hdfs://cluster1/hdp/apps/3.1.0.0-78/spark3/jars/*.jar
动态资源申请
spark-defaults.conf1
2
3
4
5spark.dynamicAllocation.enabled true
spark.dynamicAllocation.initialExecutors 0
spark.dynamicAllocation.maxExecutors 10
spark.dynamicAllocation.minExecutors 0
spark.shuffle.service.enabled true
HA
同样的配置在另外一台机器配置好Spark3.12+Kyuubi1.5.2+kyuubi-spark-authz,其实将这台机器的文件夹拷贝过去,然后改一下ip,然后启动kyuubi即可,最后和之前的文章一样用beeline验证一下HA的效果,是否可以通过一个连接地址随机分到两个kyuubi的地址,也可以在zookeeper上查看是否zooKeeperNamespace kyuubi1.5.2是否有两个ip地址注册成功。
编译打包Spark3.1.2
git clone Spark源码,切换到3.1.2 tag
1 | ## 编译打包 |
打出来的包为spark-3.1.2-bin-3.1.1.tgz,因为我们的环境的hadoop的版本为3.1.1,所以这里指定了hadoop的版本,其他的都是自己常用,比如yarn等,不过spark支持很多比如Python/R等,如果所有的都加上打包,那么会比较麻烦,也比较慢,但是不同的项目会有不同的需求,所以我们直接用官网提供的spark-3.1.2-bin-hadoop3.2.tgz也可以,版本差别不大,下载地址https://archive.apache.org/dist/spark
编译打包 Kyuubi 1.5.2
切到 tag:v1.5.2-incubating,pom spark-3.1 spark的版本为spark3.1.3,我们将其改为spark3.1.2
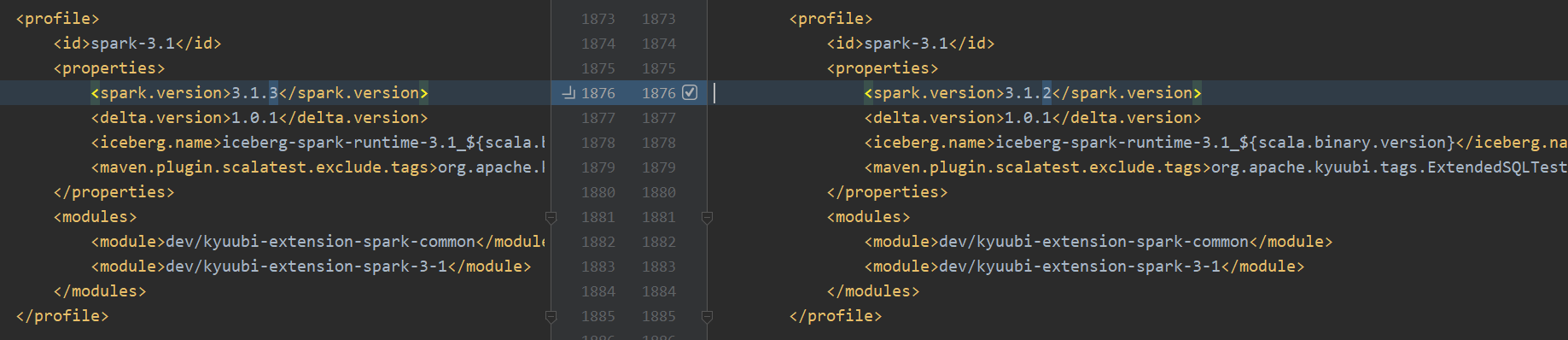
打分布式tgz安装包
根据官网文档命令:
1 | ./build/dist --tgz -Pspark-3.1 |
但是在打第二个projectKyuubi Project Common时有异常,异常为:
1 | [ERROR] ## Exception when compiling 78 sources to D:\workspace\learning\incubator-kyuubi\kyuubi-common\target\scala-2.12\classes |
用mvn命令打包一样的错误:1
mvn clean package -Pspark-3.1 -DskipTests
异常解决过程
网上查找资料,根据文章:https://blog.csdn.net/jxlxxxmz/article/details/99624261的第三个方法,添加参数scala:compile
1 | mvn clean scala:compile package -Pspark-3.1 -DskipTests |
mvn 命令打包是可行的,但是在打tgz包的命令中./build/dist添加这个参数是不行的,那么试着先用mvn命令打完包,把依赖下载下来再打tgz包,看看行不行。开头提到1.5.2版本和之前的1.4.0版本打包不太一样,比较慢,原因是因为在打包过程中默认下载spark和flink,会下载到\incubator-kyuubi\externals\kyuubi-download\target目录中,并且默认从Apache官网https://archive.apache.org/dist下载,所以比较漫长,经过漫长的等待,终于下载完成,结果在倒数第二个project报了异常:
1 | [ERROR] [Error] D:\workspace\learning\incubator-kyuubi\dev\kyuubi-extension-spark-common\src\main\scala\org\apache\kyuubi\sql\zorder\ZorderSqlAstBuilderBase.scala:46: not found: type ZorderSqlExtensionsBaseVisitor |
通过搜索源码,确实没有这些类,不过对应的模块的antlr4目录中有一个ZorderSqlExtensions.g4文件,根据经验,应该是这个文件没有成功编译,不了解antlr技术的可以自己网上查询资料了解,那么猜测可能是因为加了scala:compile的原因导致的,于是再去掉这个参数,用最初的命令试一下:1
mvn clean package -Pspark-3.1 -DskipTests
果然打包成功,然后再尝试用./build/dist --tgz -Pspark-3.1命令打tgz包,结果还是和开始一样的错误,这就很尴尬了,于是查看 ./build/dist脚本源码,发现支持--mvn参数,经过多次尝试,最终用下面这个命令打包成功!1
./build/dist --tgz --mvn /d/program/company/apache-maven-3.6.3/bin/mvn -Pspark-3.1 -DskipTests
也就是指定自己本地的maven的路径加上maven的参数即可,另外我在kyuubi群里提问这个问题,pmc告诉我用wsl可以解决,查了一下是适用于Linux的Windows子系统的意思,因为我没用过wsl,毕竟已经打包成功了也就没有再尝试
dist命令还支持 参数--flink-provided和 --spark-provided,加上这个参数就不会将spark和flink打到包里了,这样也就不会下载spark和flink导致打包很慢了,但是在最新的1.6.0-SNAPSHOT版本还要下载hive,也比较慢,没有研究怎么解决~1
./build/dist --tgz --flink-provided --spark-provided --mvn /d/program/company/apache-maven-3.6.3/bin/mvn -Pspark-3.1 -DskipTests
最终打出的包名也不一样为apache-kyuubi-1.5.2-incubating-bin.tgz,而开始打出来的包名为apache-kyuubi-1.5.2-incubating-bin-spark-3.1.tgz大小分别为221M和763M,官方提供的tgz包也不包含spark和flink的安装包
默认打包spark和flink的路径为kyuubi-1.5.2/externals/flink-1.14.3和kyuubi-1.5.2/externals/spark-3.1.2-bin-hadoop3.2,如果不在kyuubi-env.sh里配置SPARK_HOME、FLINK_HOME的话,默认就是这个路径,具体的逻辑可以kyuubi-1.5.2/bin/load-kyuubi-env.sh查看,既然提到flink,顺便说一下,kyuubi是支持flink的,在我们连接kyuubi时默认连接Spark SQL 引擎,若要连接Flink SQL,可以在连接串最后加上参数?kyuubi.engine.type=FLINK_SQL;,就会连接Flink SQL了,当然这里用的默认的Flink路径,可以自己配一下FLINK_HOME,另外应该还可以在kyuubi-defaults.conf 添加kyuubi.engine.type FLINK_SQL修改默认的engine type
打包成功
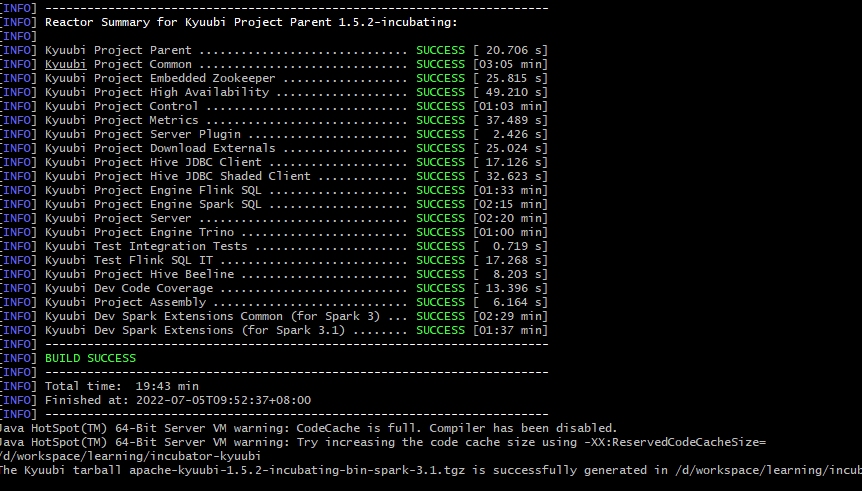
更新
2022年8月4日更新:Spark3.1.2虽然支持用逗号分隔以同时支持多个sql扩展规则,但是要注意顺序问题
我们开始是这样配置的1
spark.sql.extensions=org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension,org.apache.spark.sql.hudi.HoodieSparkSessionExtension
这样可以同时支持RangerSparkExtension和HoodieSparkSessionExtension,在控制权限的同时,也可以成功创建Hudi表并可以成功插入Hudi数据,但是在用update和delete时会有问题
update:
1 | java.lang.UnsupportedOperationException: UPDATE TABLE is not supported temporarily |
delete:
1 | Error in query: DELETE is only supported with v2 tables |
应该还存在其他问题,就不一一列举了
解决方案:改变规则顺序,先扩展Hudi,再扩展Ranger,这样就可以在正确控制权限的同时,不影响Hudi Spark SQL的使用
1 | spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension,org.apache.kyuubi.plugin.spark.authz.ranger.RangerSparkExtension |


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Spark3.12+Kyuubi1.5.2+kyuubi-spark-authz源码编译打包+部署配置HA
本文链接:https://dongkelun.com/2022/07/06/sparkKyuubiPackConf/
欢迎关注我的公众号