
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
上面文章Hive增量查询Hudi表提到Hudi表有读优化视图和实时视图,其实当时并没有完全掌握,所以现在单独学习总结。Hudi官网文档中文称之为视图,其实英文为query types翻译过来为查询类型
Query types
Hudi 支持下面三种视图
Snapshot Queries 快照查询/实时视图 Queries see the latest snapshot of the table as of a given commit or compaction action. In case of merge on read table, it exposes near-real time data(few mins) by merging the base and delta files of the latest file slice on-the-fly. For copy on write table, it provides a drop-in replacement for existing parquet tables, while providing upsert/delete and other write side features. 在此视图上的查询可以查看给定提交或压缩操作时表的最新快照。对于读时合并表(MOR表) 该视图通过动态合并最新文件切片的基本文件(例如parquet)和增量文件(例如avro)来提供近实时数据集(几分钟的延迟)。对于写时复制表(COW表),它提供了现有parquet表的插入式替换,同时提供了插入/删除和其他写侧功能。
Incremental Queries 增量查询/增量视图,也就是上篇文章讲的增量查询 Queries only see new data written to the table, since a given commit/compaction. This effectively provides change streams to enable incremental data pipelines. 对该视图的查询只能看到从某个提交/压缩后写入数据集的新数据。该视图有效地提供了更改流,来支持增量数据管道。
Read Optimized Queries 读优化查询/读优化视图 : Queries see the latest snapshot of table as of a given commit/compaction action. Exposes only the base/columnar files in latest file slices and guarantees the same columnar query performance compared to a non-hudi columnar table. 在此视图上的查询将查看给定提交或压缩操作中数据集的最新快照。 该视图仅将最新文件切片中的基本/列文件暴露给查询,并保证与非Hudi列式数据集相比,具有相同的列式查询性能。
表类型
| Table Type | Supported Query types |
|---|---|
| Copy On Write | Snapshot Queries + Incremental Queries |
| Merge On Read | Snapshot Queries + Incremental Queries + Read Optimized Queries |
也就是读优化视图只有在MOR表中存在,这点在上篇文章中也提到过,这次会从源码层面分析两种表类型的区别以及如何实现的。
另外关于这一点官网中文文档写错了,大家注意别被误导,估计是因为旧版本,且中文文档没有人维护贡献,就没人贡献修改了~,稍后我有时间会尝试提个PR修复一下,错误截图:
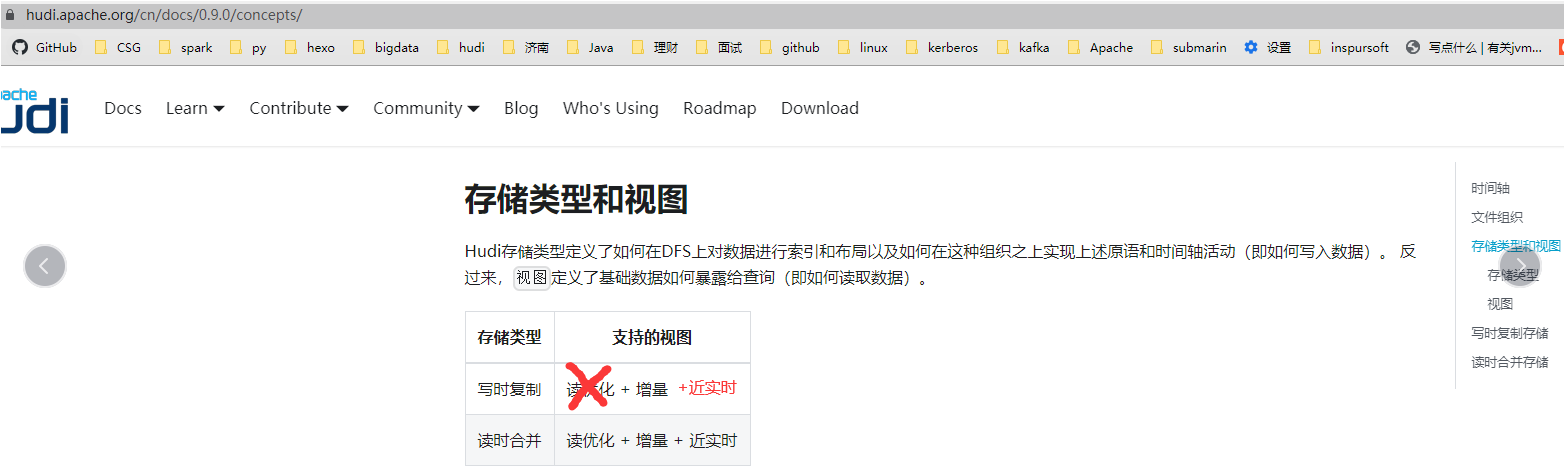
2022.06.30更新:已提交PR https://github.com/apache/hudi/pull/6008
源码
简单从源码层面分析同步Hive表时两种表类型的区别,Hudi同步Hive元数据的工具类为HiveSyncTool,如何利用HiveSyncTool同步元数据,先进行一个简单的示例,这里用Spark进行示例,因为Spark有获取hadoopConf的API,代码较少,方便示例,其实纯Java也是可以实现的
1 | val basePath = new Path(pathStr) |
这里利用tableMetaClient来获取表的主键和分区字段,因为同步元数据时Hudi表文件肯定已经存在了,当然如果知道表的主键和分区字段也可以自己指定,这里自动获取会更方便一些。
其实主要是获取配置文件,构造同步工具类HiveSyncTool,然后利用syncHoodieTable同步元数据,建Hive表
接下来看一下源码,首先new HiveSyncTool时,会根据表类型,当表类型为COW时,this.snapshotTableName = cfg.tableName,snapshotTableName 也就是实时视图等于表名,而读优化视图为空,当为MOR表示,实时视图为tableName_rt,而对于读优化视图,默认情况下为tableName_ro,
当配置skipROSuffix=true时,等于表名,这里可以发现当skipROSuffix=true时,MOR表的读优化视图为表名而COW表的实时视图为表名,感觉这里有点矛盾,可能是因为MOR表的读优化视图和COW表的实时视图查询均由HoodieParquetInputFormat实现,具体看后面的源码分析
1 | private static final Logger LOG = LogManager.getLogger(HiveSyncTool.class); |
接下来再看一下,上篇文章中提到的两个视图的实现类HoodieParquetInputFormat和HoodieParquetRealtimeInputFormat
1 |
|
可以看到,两个表的区别为:1、COW只同步1个表的元数据:实时视图,MOR表同步两个表的元数据,读优化视图和实时视图 2、除了表名外,参数也不一样,这也就决定了查询时用哪个实现类来实现
由于这篇文章不是主要讲解同步Hive元数据的源码,所以这里只贴主要实现部分,以后会单独总结一篇同步Hive元数据源码的文章。
1 | protected void syncHoodieTable(String tableName, boolean useRealtimeInputFormat, |
可以看到对于存储类型为PARQUET时,当useRealtimeInputFormat为true时,那么inputFormat的实现类为HoodieParquetRealtimeInputFormat,当为false时,实现类为HoodieParquetInputFormat,至于另外一个参数readAsOptimized,是否为读优化,这个参数是Spark SQL读取时用来判断该表为实时视图还是读优化视图,相关源码
1 | // 同步元数据建表时添加参数:`hoodie.query.as.ro.table=true/false` |
体现在建表语句里则为:
1 | WITH SERDEPROPERTIES ( | |
inputFormat的语句:1
2STORED AS INPUTFORMAT |
| 'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
完整的建表语句在后面的示例中
示例
DF
这里利用Apache Hudi 入门学习总结中写Hudi并同步到Hive表的程序来验证
COW表
由于之前的文章中已经有COW表的建表语句了,这里直接copy过来
1 | +----------------------------------------------------+ |
可以看到'hoodie.query.as.ro.table'='false',对于COW表的视图为实时视图,inputFormat为org.apache.hudi.hadoop.HoodieParquetInputFormat
MOR表
我们将之前的save2HudiSyncHiveWithPrimaryKey方法中加个表类型的参数option(TABLE_TYPE.key(), MOR_TABLE_TYPE_OPT_VAL),将表名库名修改一下:
1 | val databaseName = "test" |
同步Hive表成功后,show tables,发现建了两张表test_hudi_table_df_mor_ro和test_hudi_table_df_mor_rt,通过上面的源码分析部分,我们知道_ro为读优化表,_rt为实时表,我们再看一下建表语句:
1 | +----------------------------------------------------+ |
可以看到_ro和_rt有两个区别,一个是hoodie.query.as.ro.table,另外一个是INPUTFORMAT,对于Hive查询来说,只有INPUTFORMAT有用,hoodie.query.as.ro.table是Spark查询时用来判断是否为读优化表的,因为MOR表只有一次写入,所以只有parquet文件,没有增量文件.log,所以两个表查询出来的结构是一样的,后面用Spark SQL示例两者的区别
Spark SQL
Hudi Spark SQL建表,不了解的可以参考:Hudi Spark SQL总结,之所以再提一下Spark SQL建表,是因为我发现他和DF写数据再同步建表有些许差别
COW表
1 | create table test_hudi_table_cow ( |
建表完成后,在Hive里查看Hive表的建表语句
1 | show create table test_hudi_table_cow; |
我们发现,Spark SQL建的表中没有hoodie.query.as.ro.table,我看了一下源码发现(上面有提到),Spark查询时1
2
3val queryType = parameters.get(ConfigUtils.IS_QUERY_AS_RO_TABLE)
.map(is => if (is.toBoolean) QUERY_TYPE_READ_OPTIMIZED_OPT_VAL else QUERY_TYPE_SNAPSHOT_OPT_VAL)
.getOrElse(parameters.getOrElse(QUERY_TYPE.key, QUERY_TYPE.defaultValue()))QUERY_TYPE的默认值为QUERY_TYPE_SNAPSHOT_OPT_VAL,也就是快照查询,COW只有快照查询也就是默认值没有问题,QUERY_TYPE有三种类型:QUERY_TYPE_SNAPSHOT_OPT_VAL, QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, QUERY_TYPE_INCREMENTAL_OPT_VAL,分别对应实时查询,读优化查询,增量查询,至于怎么利用Spark实现这些查询,这里不涉及
MOR表
1 | create table test_hudi_table_mor ( |
我们用Spark创建MOR表后,show tables看一下发现只有test_hudi_table_mor表,没有对应的_rt、_ro表,其实SparkSQL建表的时候还没用到Hive同步工具类HiveSyncTool,SparkSQL有自己的一套建表逻辑,而只有在写数据时才会用到HiveSyncTool,这也就是上面讲到的SparkSQL和DF同步建出来的表有差异的原因,接下来我们插入一条数据,来看一下结果
1 | insert into test_hudi_table_mor values (1,'hudi',10,100,'2021-05-05'); |
我们发现多了两张表,因为这两张表,是insert 数据然后利用同步工具类HiveSyncTool创建的表,所以和程序中用DF写数据同步建的表是一样的,区别是内部表和外部表的区别,其实SparkSQL的逻辑如果表路径不等于库路径+表名,那么为外部表,这是合理的,而我们用DF建的表是因为我们程序中指定了内部表的参数,这样我们drop其中一张表就可以删掉数据,而用SparkSQL建的表,其实多了一张表内部表test_hudi_table_mor,我们可以通过drop这张表来删除数据。
1 | +----------------------------------------------------+ |
我们再插入一条数据和更新一条数据,目的是为了生成log文件,来看两个表的不同
1 | insert into test_hudi_table_mor values (2,'hudi',11,110,'2021-05-05'); |
1 | select * from test_hudi_table_mor_ro; |
1 | select * from test_hudi_table_mor_rt; |
我们发现_ro只能将新插入的查出来,而没有将更新的那条数据查出来,而_rt是将最新的数据都查出来,我们再插入和更新时看一下存储文件
1 | hadoop fs -ls hdfs://cluster1/warehouse/tablespace/managed/hive/test.db/test_hudi_table_mor/dt=2021-05-05 |
发现,insert时是生成新的parquet文件,而更新时是生成.log文件,所以_ro表将新插入的数据也出来了,因为_ro只能查parquet文件(基本文件)中的数据,而_rt表可以动态合并最新文件切片的基本文件(例如parquet)和增量文件(例如avro)来提供近实时数据集(几分钟的延迟),至于MOR表的写入逻辑(什么条件下写增量文件)和合并逻辑(什么情况下合并增量文件为parquet),这里不深入讲解,以后我会单独总结。


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Hudi查询类型/视图总结
本文链接:https://dongkelun.com/2022/06/29/hudiQueryTypes/
欢迎关注我的公众号