
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
本文总结如何只用SQL迁移关系型数据库中的表转化为Hudi表,这样的意义在于方便项目上对Spark、Hudi等不熟悉的人员运维。
Spark Thrift Server
首先将Orace的驱动拷贝至Spark jars目录下
启动Spark Thrift Server 扩展支持Hudi
1 | /usr/hdp/3.1.0.0-78/spark2/bin/spark-submit --master yarn --deploy-mode client --executor-memory 2G --num-executors 6 --executor-cores 2 --driver-memory 4G --driver-cores 2 --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift-20003 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' --principal spark/indata-192-168-44-128.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab --hiveconf hive.server2.thrift.http.port=20003 >~/server.log 2>&1 & |
Beeline连接
1 | /usr/hdp/3.1.0.0-78/spark2/bin/beeline -u "jdbc:hive2://192.168.44.128:20003/hudi;principal=HTTP/indata-192-168-44-128.indata.com@INDATA.COM?hive.server2.transport.mode=http;hive.server2.thrift.http.path=cliservice" |
SQL 转化
首先建好Hive数据库
Oracle 表结构及数据

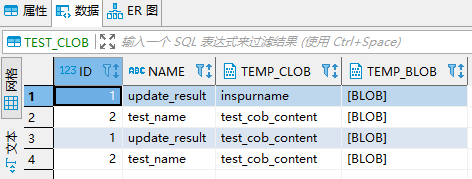
将Oracle表映射为临时表
1 | CREATE TEMPORARY VIEW temp_test_clob |
字段类型字段匹配
Hudi Spark SQL 支持 CTAS语法
1 | create table test_hudi.test_clob_oracle_sync using hudi options(primaryKey = 'ID',preCombineField = 'ID') as select * from temp_test_clob; |
注意这里的ID为大写,是因为在Oracle表中的字段名为大写
1 | show create table test_clob_oracle_sync; |
可以看到这里Spark为字段类型做了适配
提前建表
提前建表的好处是,字段类型可以自己掌握
1 | create table test_hudi.test_clob_oracle_sync1( |
1 | show create table test_clob_oracle_sync1; |
可以根据需求选择是否配置主键、分区字段等;另hudi0.9.0版本支持非主键表,当前0.10版本主键字段必填,未来的版本也许会有所变化
MySQL
1 |
|


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:SparkSQL JDBC 查询Oracle、MySQL 转化为Hudi表
本文链接:https://dongkelun.com/2022/02/15/sparkSqlJdbc2Hudi/
欢迎关注我的公众号