
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
总结Spark Thrift Server、Hive Server以及如何用Java连接
启动
hive server
1 | hiveserver2 |
默认端口是1000
spark thrift server
修改hive.server2.transport.mode为http(默认值为binary(TCP),可选值HTTP)
将hive-site.xml拷贝到spark conf 目录下,并添加1
2
3
4
5<property>
<name>hive.server2.transport.mode</name>
<value>http</value>
</property>
启动命令($SPARK_HOME/sbin)
1 | start-thriftserver.sh --端口默认值为10001 |
当hive.server2.transport.mode为http时,默认端口为10001,通过–hiveconf hive.server2.thrift.http.port修改端口号,当然hive.server2.transport.mode为默认值TCP 时,默认端口为10000,通过–hiveconf hive.server2.thrift.port修改端口号, 也就是默认端口号和是否为hive或者spark无关,这里为啥spark不选默认值,因为当为默认值时,虽然也能正常使用,但是spark server日志里会有异常,原因未知,待研究
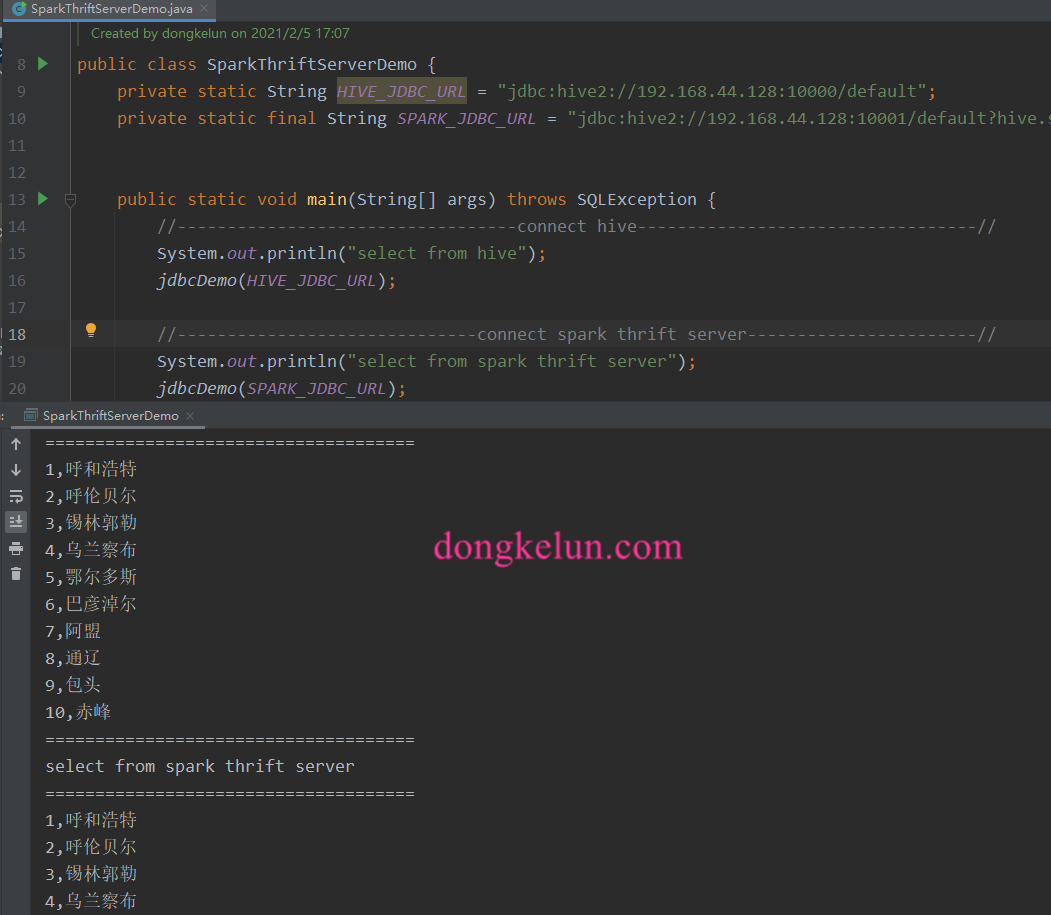
Java 代码
pom 依赖
1 | <dependencies> |
更新:2021-05-07
这里提一下依赖的版本问题,上面写的版本是我自己搭建的开源的hive和hadoop,所以版本可以很清楚的知道是多少,并且和spark版本是适配的。后来在连接hdp对应的hive和spark时,在版本对应关系上出现了问题,这里总结一下。首先提一下在连接Spark Thrift Server时,对版本适配要求比较高,而hive server对依赖的版本适配较低。
总结一下hdp如何对应版本,在ambari界面添加服务即可看到各个组件包括hive对应的版本信息,或者在命令行看一下jar包,比如hive-jdbc-3.1.0.3.1.0.0-78.jar,则代表hive本本为3.1.0,后面的是hdp的版本号,这样配置依赖连接Hive Server是没有问题的,而在连接Spark Server时发现了问题,报了版本不匹配的异常,比如spark/jars下的jar包为hive-jdbc-1.21.2.3.1.0.0-78.jar,那么hive-jdbc的版本应该为1.21.2可实际上没有这个版本的依赖,且即使用上面的3.1.0版本去连接Spark Sever一样版本不匹配,那么这种情况下该如何确定hive-jdbc的版本的?我用的是下面的方法:
首先确认Spark的版本为2.4.,然后我去github上查找对应的版本的spark源码的依赖,发现hive的版本号为1.2.1,
hadoop的版本号为2.6.5,那么最终hive-jdbc:1.2.1,hadoop-common:2.6.5,这样配置依赖就可以连接hdp下的spark thrift server了,且该版本的hive-jdbc一样可以连接hive server即上面说的hive server对依赖的版本适配较低。最后提一下,当hive-jdbc版本为3.1.0即3..*时,不用再另外添加hadoop-common的依赖即可连接hive server,因为hive-jdbc的包里已经包含了对应的依赖,即使同时添加也会依赖冲突的。
附:版本不匹配时的异常信息:
2
3
4
5
6
7
8
9
10
11
12
13
org.apache.thrift.TApplicationException: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=sjtt})
at org.apache.thrift.TApplicationException.read(TApplicationException.java:111) ~[libthrift-0.9.3.jar:0.9.3]
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79) ~[libthrift-0.9.3.jar:0.9.3]
at org.apache.hive.service.rpc.thrift.TCLIService$Client.recv_OpenSession(TCLIService.java:168) ~[hive-service-rpc-2.3.7.jar:2.3.7]
at org.apache.hive.service.rpc.thrift.TCLIService$Client.OpenSession(TCLIService.java:155) ~[hive-service-rpc-2.3.7.jar:2.3.7]
at org.apache.hive.jdbc.HiveConnection.openSession(HiveConnection.java:680) [hive-jdbc-2.3.7.jar:2.3.7]
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:200) [hive-jdbc-2.3.7.jar:2.3.7]
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:107) [hive-jdbc-2.3.7.jar:2.3.7]
at java.sql.DriverManager.getConnection(DriverManager.java:664) [?:1.8.0_161]
at java.sql.DriverManager.getConnection(DriverManager.java:270) [?:1.8.0_161]
at com.dkl.blog.SparkThriftServerDemoWithKerberos.jdbcDemo(SparkThriftServerDemoWithKerberos.java:41) [classes/:?]
at com.dkl.blog.SparkThriftServerDemoWithKerberos.main(SparkThriftServerDemoWithKerberos.java:35) [classes/:?]
代码
1 | package com.dkl.blog; |
代码已上传到 github


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Java 连接 Spark Thrift Server/Hive Server总结
本文链接:https://dongkelun.com/2021/02/19/javaSparkThriftServer/
欢迎关注我的公众号