
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
学习总结Python处理Excel
文件
一个测试有两个sheet页的Excel测试文件 test.xlsx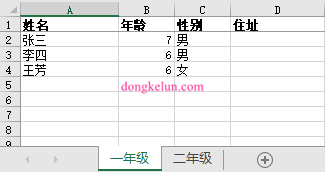

代码
完整代码已上传到GitHub sheetDemo.py
1 | import pandas as pd |
1 | <pandas.io.excel._base.ExcelFile object at 0x0000021DE525DF88> |
分析
pd.read_excel读出来是一个dataframe可以直接打印出内容,但是只能读取一个sheet页,默认第一个sheet页1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
def read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skip_footer=0,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
**kwds
):
for arg in ("sheet", "sheetname", "parse_cols"):
if arg in kwds:
raise TypeError(
"read_excel() got an unexpected keyword argument " "`{}`".format(arg)
)
if not isinstance(io, ExcelFile):
io = ExcelFile(io, engine=engine)
elif engine and engine != io.engine:
raise ValueError(
"Engine should not be specified when passing "
"an ExcelFile - ExcelFile already has the engine set"
)
return io.parse(
sheet_name=sheet_name,
header=header,
names=names,
index_col=index_col,
usecols=usecols,
squeeze=squeeze,
dtype=dtype,
converters=converters,
true_values=true_values,
false_values=false_values,
skiprows=skiprows,
nrows=nrows,
na_values=na_values,
keep_default_na=keep_default_na,
verbose=verbose,
parse_dates=parse_dates,
date_parser=date_parser,
thousands=thousands,
comment=comment,
skipfooter=skipfooter,
convert_float=convert_float,
mangle_dupe_cols=mangle_dupe_cols,
**kwds
)
pd.ExcelFile 返回值是一个Excel对象,不能直接用,但是可以读取整个Excel内容
pd.ExcelFile
1 | file = pd.ExcelFile('D:\\data\\py\\test.xlsx') |
sheet页名称
1 | print(file.sheet_names) |
1 | ['一年级', '二年级'] |
遍历读取每个sheet页的内容
1 | for name in file.sheet_names: |
1 | 姓名 年龄 性别 住址 |
将两个sheet页的内容合并,并添加一列内容为sheet页名称
1 | df_list=[] |
1 | 姓名 年龄 性别 住址 班级 |
忽略掉原来的index
1 | df = pd.concat([_df for _df in df_list],ignore_index=True,sort=False) |
1 | 姓名 年龄 性别 住址 班级 |
修改列名为英文
1 | df = df.rename(columns={'姓名': 'name', '年龄': 'age', '性别': 'sex', '住址': 'address', '班级': 'class'}) |
1 | name age sex address class |
将df保存为CSV、Excel文件
sheet合并.csv sheet合并.xls1
2df.to_csv('../data/sheet合并.csv',index=False)
df.to_excel('../data/sheet合并.xls',index=True)
总结
可以发现Python读写Excel文件还是很方便的!


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Python 处理Excel总结(1)
本文链接:https://dongkelun.com/2019/12/30/pythonExcel/
欢迎关注我的公众号