
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

1、需求背景
和上一篇文章Spark通过修改DataFrame的schema给表字段添加注释一样,通过Spark将关系型数据库(以Oracle为例)的表同步的Hive,这里讲的只是同步历史数据,不包括同步增量数据。
2、Oracle和Hive的字段类型对应
利用Spark的字段类型自动匹配,本来以为Spark匹配的不是很好,只是简单的判断一下是否为数字、字符串,结果经验证,Spark可以获取到Oracle的小数点精度,Spark的字段类型对应和我自己整理的差不多,所以就索性用Spark自带的字段类型匹配,而不是自己去Oracle相关表获取每个字段类型,然后一一转化为Hive对应的字段类型,下面是Oracle和Hive的字段类型对应,只是整理了大概:
| Oracle | Hive |
|---|---|
| VARCHAR2 | String |
| NVARCHAR2 | String |
| NUMBER | DECIMAL/Int |
| DATE | TIMESTAMP |
| TIMESTAMP | TIMESTAMP |
| CHAR | String |
| CLOB(一般用不到) | String |
| BLOB(一般用不到) | BINARY |
| RAW (一般用不到) | BINARY |
| Other | String |
2.1 看一下Spark字段类型对应
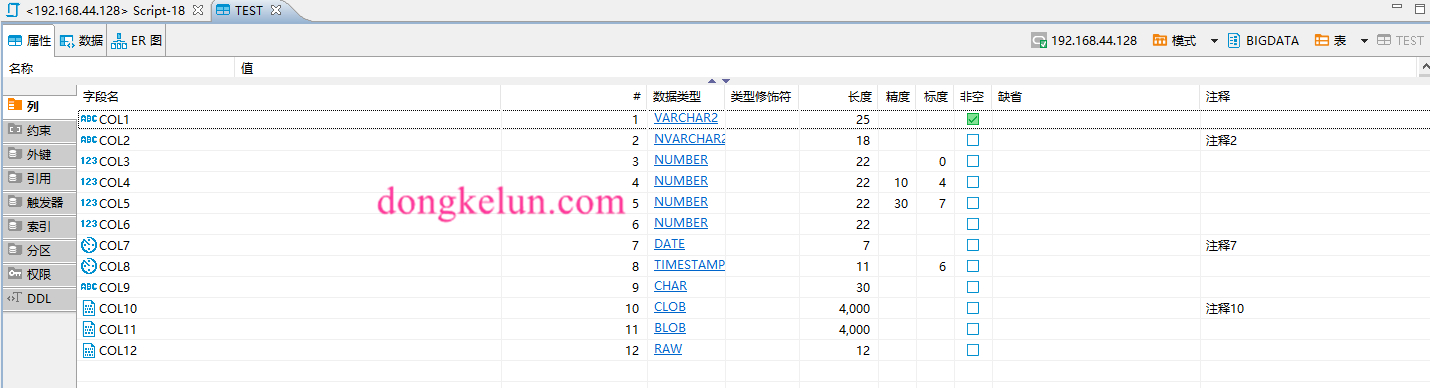
首先建一张包含大部分字段类型的Oracle表1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17CREATE TABLE TEST (
COL1 VARCHAR2(25),
COL2 NVARCHAR2(18),
COL3 INTEGER,
COL4 NUMBER(10,4),
COL5 NUMBER(30,7),
COL6 NUMBER,
COL7 DATE,
COL8 TIMESTAMP,
COL9 CHAR(30),
COL10 CLOB,
COL11 BLOB,
COL12 RAW(12)
) ;
COMMENT ON COLUMN TEST.COL2 IS '注释2' ;
COMMENT ON COLUMN TEST.COL7 IS '注释7' ;
COMMENT ON COLUMN TEST.COL10 IS '注释10' ;
然后用Spark打印一下获取到的字段类型。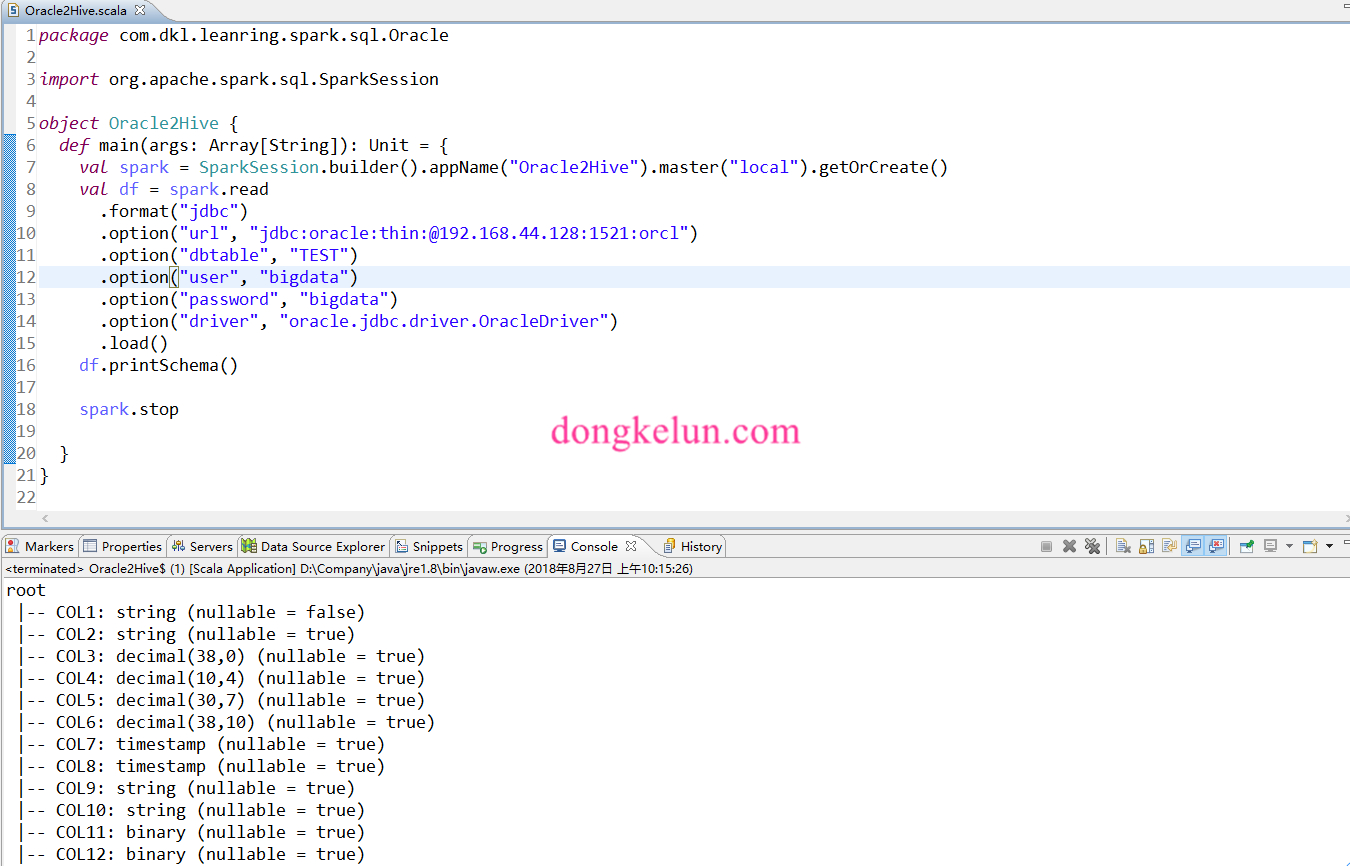
可以看到Spark成功的完成上述表格的字段类型转化,小数的精度和是否为空都可以获取到,但是不完美的一点是没有将NUMBER标度为零的转换为Int,而还是以DECIMAL(38,0)的形式表示,虽然都是表示的整数,但是在后面Spark读取hive的时候,还需要将DECIMAL转为Int。
2.2 按需修改字段类型对应
以上面讲的将DECIMAL(38,0)转为Int为例:
先尝试通过修改schema实现1
2
3
4
5
6
7
8
9
10
11import org.apache.spark.sql.types._
val schema = df.schema.map(s => {
if (s.dataType.equals(DecimalType(38, 0))) {
new StructField(s.name, IntegerType, s.nullable)
} else {
s
}
})
//根据添加了注释的schema,新建DataFrame
val new_df = spark.createDataFrame(df.rdd, StructType(schema)).repartition(160)
new_df.printSchema()
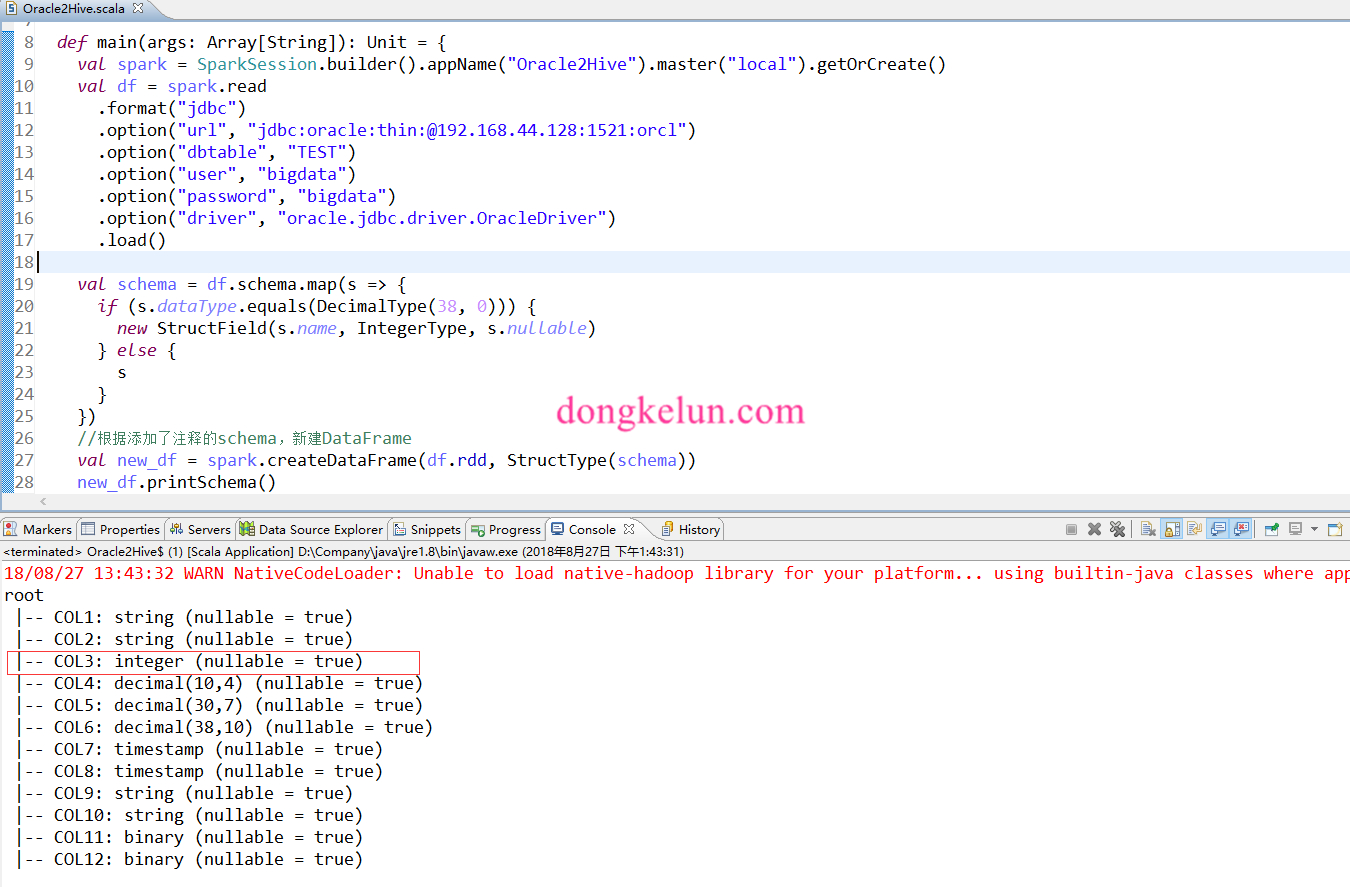
可以看到,已经成功的将COL3的字段转为了Int。但是这样构造的DataFrame是不能用的,如执行new_df.show会报如下错误:1
java.lang.RuntimeException: Error while encoding: java.lang.RuntimeException: java.math.BigDecimal is not a valid external type for schema of int
原因是rdd的数据类型和schema的数据类型不匹配。
最后可以通过如下方式实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
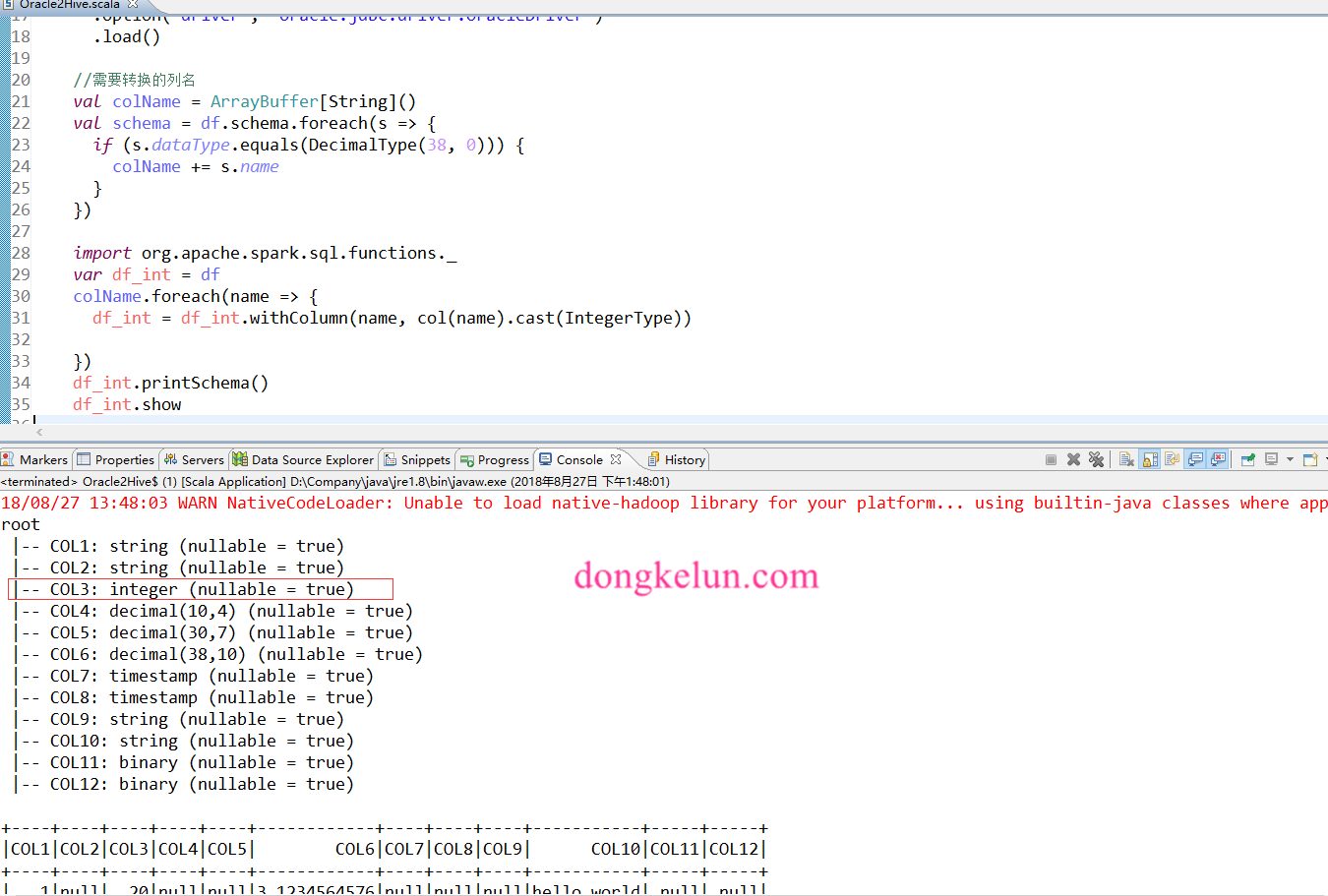
16import scala.collection.mutable.ArrayBuffer
//需要转换的列名
val colName = ArrayBuffer[String]()
val schema = df.schema.foreach(s => {
if (s.dataType.equals(DecimalType(38, 0))) {
colName += s.name
}
})
import org.apache.spark.sql.functions._
var df_int = df
colName.foreach(name => {
df_int = df_int.withColumn(name, col(name).cast(IntegerType))
})
df_int.printSchema()
df_int.show
3、Oracle全部历史数据同步Hive
3.1 再新建一张表
这里的目的是表示多个表,而不是一个表,上面已经建了一张表,再建一张表,以验证代码可以将所有的表都同步过去,这里用上一篇博客上的建表Sql即可1
2
3
4
5
6
7CREATE TABLE ORA_TEST (
ID VARCHAR2(100),
NAME VARCHAR2(100)
);
COMMENT ON COLUMN ORA_TEST.ID IS 'ID';
COMMENT ON COLUMN ORA_TEST.NAME IS '名字';
COMMENT ON TABLE ORA_TEST IS '测试';
再在每张表里造点数据,这里就不截图了。
3.2 代码
上篇博客里用到的注释,是在程序里手工添加的注释,下面的代码是从Oracle里取的,且同步的是一个用户下所有的表。
1 | package com.dkl.leanring.spark.sql.Oracle |
3.3 看一下Hive里的结果
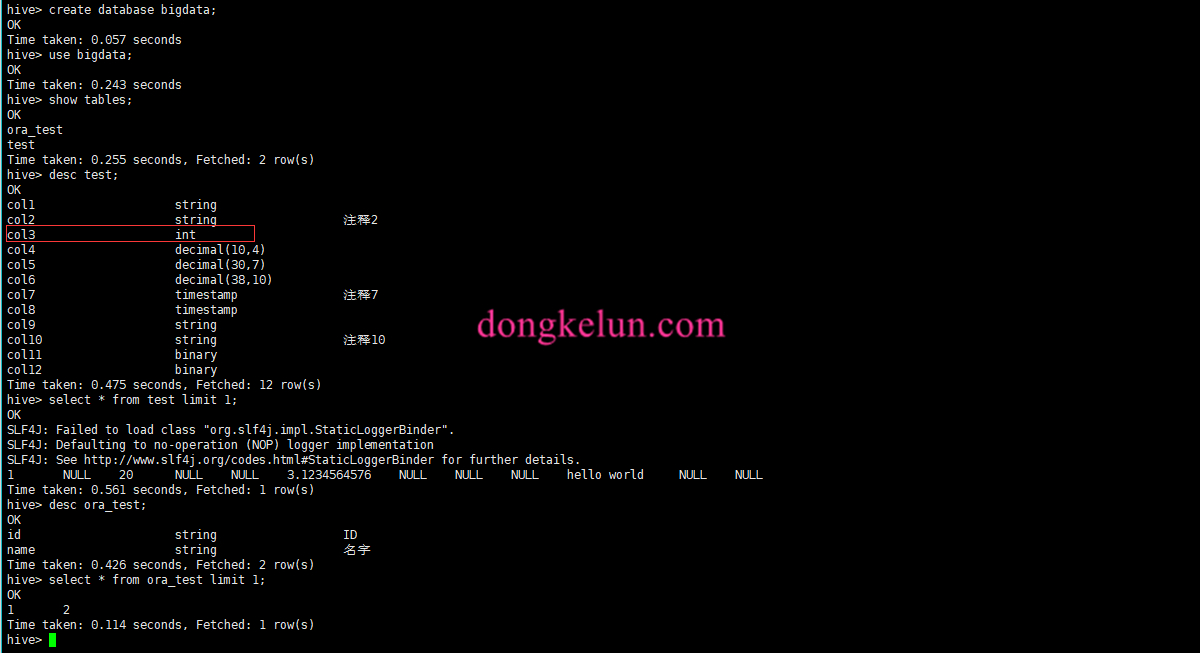
这样就成功的完成了Oracle历史数据到Hive的同步!
4、关于增量数据的同步
4.1 实时同步
可以考虑这样,先用ogg将Oracle的增量数据实时同步到kafka,再用Spark Streaming实现kafka到hive的实时同步。
- 下面两篇文章提供参考:利用ogg实现oracle到kafka的增量数据实时同步、Spark Streamming+Kafka提交offset实现有且仅有一次,其中Spark Streaming的代码并没有实现写入hive的功能,但是实时读取kafka的功能已经实现,只要自己处理一下解析kafka里json格式的增量数据,转成DataFrame保存到hive表里即可。
4.2 非实时
如果Oracle的每个表里都有时间字段,那么可以通过时间字段来过滤增量数据,用上面的Spark程序去定时的跑,如果没有时间字段的话,可以用ogg的colmap函数增加时间字段,先实时同步到中间的Oracle库,再根据时间字段来同步。


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:利用Spark实现Oracle到Hive的历史数据同步
本文链接:https://dongkelun.com/2018/08/27/sparkOracle2Hive/
欢迎关注我的公众号