
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
本文讲Spark Streamming使用Direct方式读取Kafka,并在输出(存储)操作之后提交offset到Kafka里实现程序读写操作有且仅有一次,即程序重启之后之前消费并且输出过的数据不再重复消费,接着上次消费的位置继续消费Kafka里的数据。
Spark Streamming+Kafka官方文档:http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
1、提交offset的程序
根据官方文档可知,在spark代码里可以获取对应的offset信息,并且可以提交offset存储到kafka中。
代码:
1 | package com.dkl.leanring.spark.kafka |
说明:
- auto.offset.reset设置为earliest,即当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始,这样设置的目的是为了一开始可以获取到kafka对应主题下的所有的历史消息。
- enable.auto.commit 设置为false,如果是true,则这个消费者的偏移量会在后台自动提交,这样设置目的是为了后面自己提交offset,因为如果虽然获取到了消息,但是后面的转化操作并将结果写到如hive中并没有完成程序就挂了的话,这样是不能将这次的offset提交的,这样就可以等程序重启之后接着上次失败的地方继续消费
- group.id 是不能变得,也就是offset是和topic和group绑定的,如果换一个group的话,程序将从头消费所有的历史数据
- 这个api是将offset存储到kakfa的一个指定的topic里,名字为__consumer_offsets,而不是zookeeper中
2、测试程序
1、首先创建对应的topic
2、生产几条数据作为历史消息1
bin/kafka-console-producer.sh --broker-list ambari.master.com:6667 --topic top1
3、启动上面的程序
4、继续生产几条数据
接下来先看一下结果:

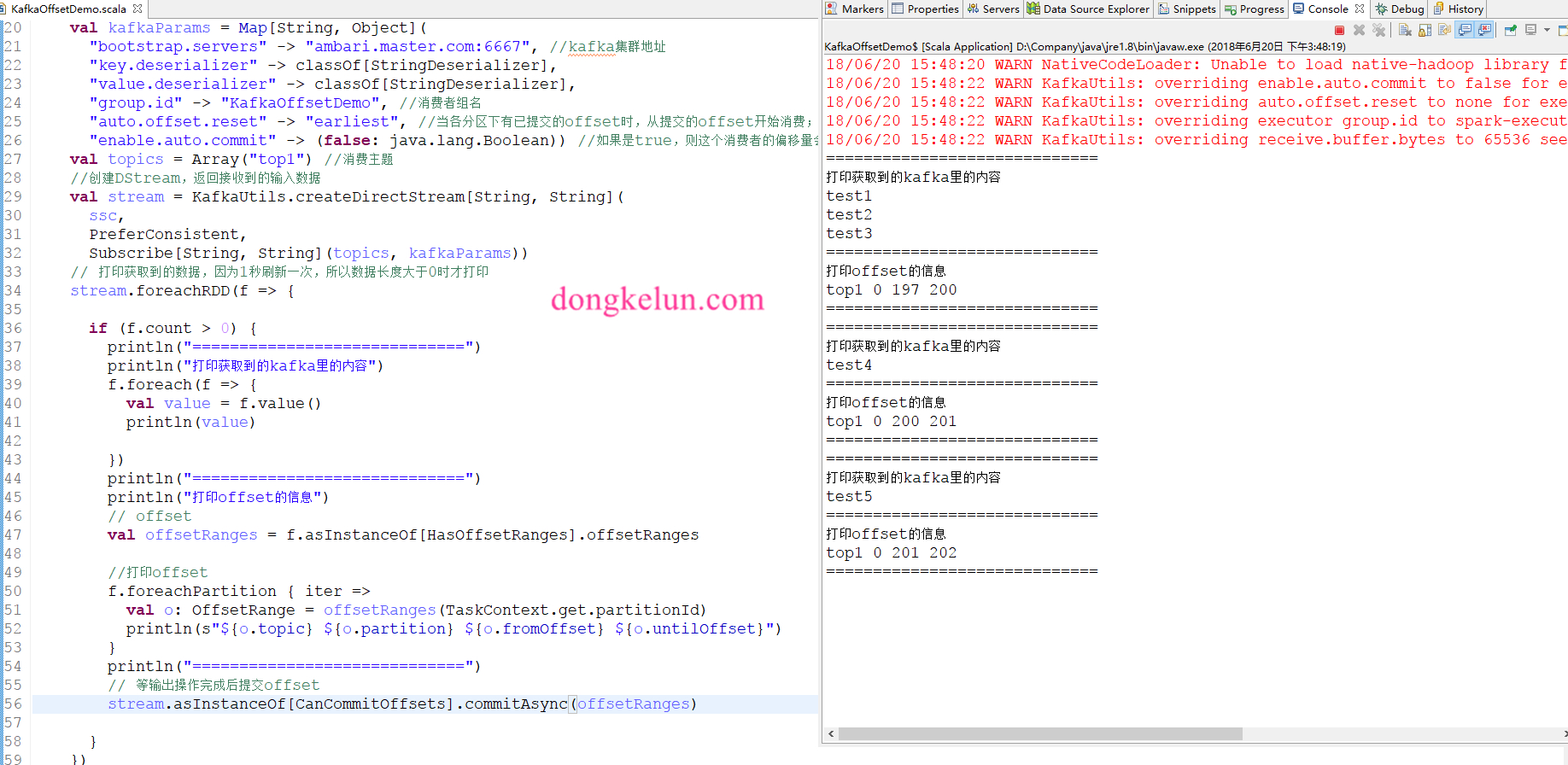
由图可得,这样可以将历史数据全部打印出来,并且后面实时增加的数据,也打印出来了,且可以看到offset是在增加的,最后一个offset是202,那么接下来测试一下程序重启之后是否会接着之前的数据继续消费呢
5、停止程序
6、生产几条数据
7、启动程序
看一下结果: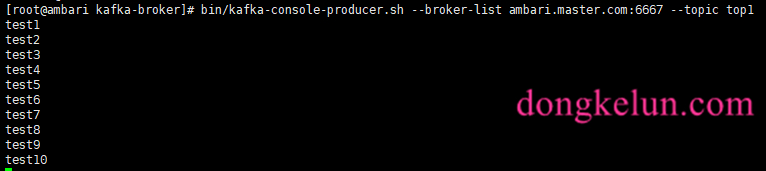
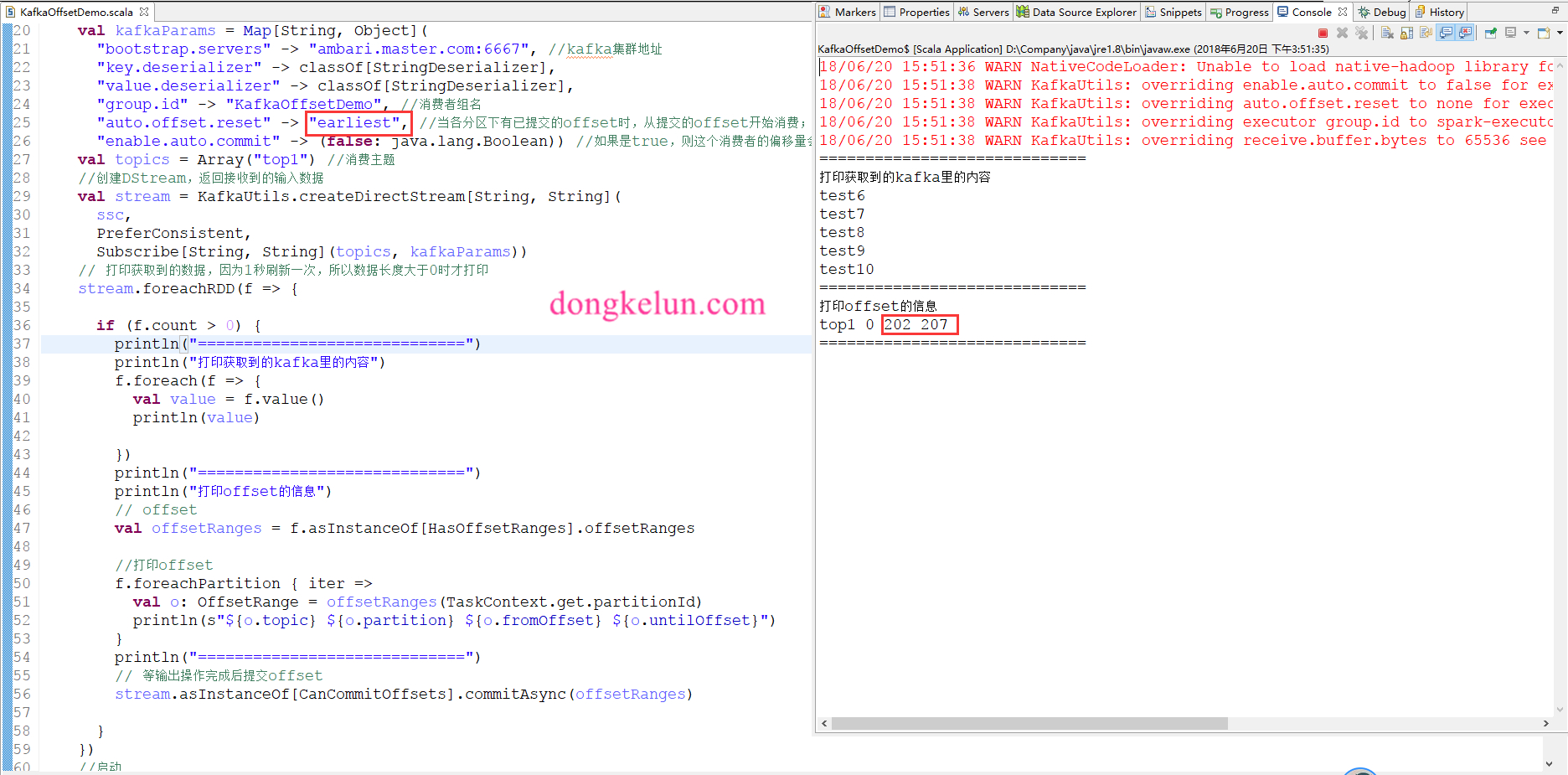
可以看出,程序确实是接着上次消费的地方消费的,为了证实这一点,我将earliest和offset圈了起来,从offset可以看到是从上次的202开始消费的。
3、关于offset过期时间
kafka offset默认的过期时间是一天,当上面的程序挂掉,一天之内没有重启,也就是一天之内没有保存新的offset的话,那么之前的offset就会被删除,再重启程序,就会从头开始消费kafka里的所有历史数据,这种情况是有问题的,所以可以通过设置offsets.retention.minutes自定义offset过期时间,该设置单位为分钟,默认为1440。
修改kafka的offset过期时间详细信息见:https://dongkelun.com/2018/06/21/modifyKafkaOffsetTime/
4、自己保存offset
可以通过自己保存offset的信息到数据库里,然后需要时再取出来,根据得到的offset信息消费kafka里的数据,这样就不用担心offset的过期的问题了,因为没有自己写代码实现,所以先给出官网的示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// The details depend on your data store, but the general idea looks like this
// begin from the the offsets committed to the database
val fromOffsets = selectOffsetsFromYourDatabase.map { resultSet =>
new TopicPartition(resultSet.string("topic"), resultSet.int("partition")) -> resultSet.long("offset")
}.toMap
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets)
)
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val results = yourCalculation(rdd)
// begin your transaction
// update results
// update offsets where the end of existing offsets matches the beginning of this batch of offsets
// assert that offsets were updated correctly
// end your transaction
}


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Spark Streaming+Kafka提交offset实现有且仅有一次(exactly-once)
本文链接:https://dongkelun.com/2018/06/20/sparkStreamingOffsetOnlyOnce/
欢迎关注我的公众号