
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

前言
旧版本spark不能直接读取csv转为df,没有spark.read.option(“header”, “true”).csv这么简单的方法直接将第一行作为df的列名,只能现将数据读取为rdd,然后通过map和todf方法转为df,如果csv(txt)的列数很多的话用如(1,2,…,n),即创建元组很麻烦,本文解决如何用旧版spark读取多列txt文件转为df
1、新版
为了直观明白本文的目的,先看一下新版spark如何实现
1.1 数据
data.csv,如图: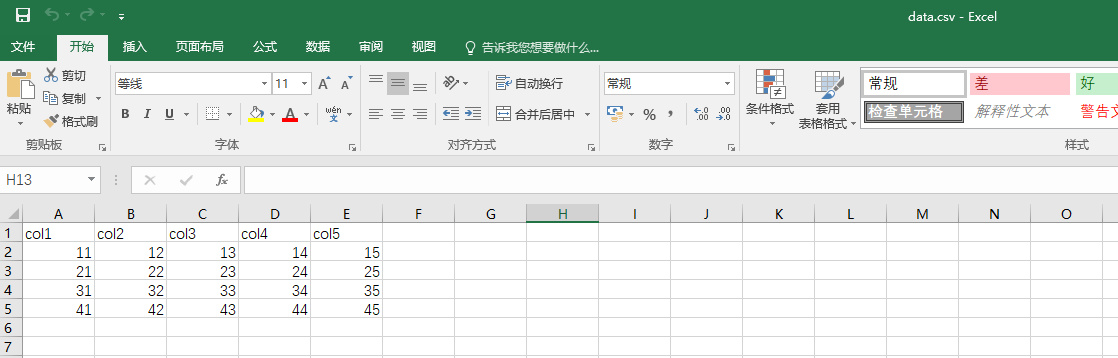
1.2 代码
新版代码较简单,直接通过spark.read.option(“header”, “true”).csv(data_path)即可实现!
1 | package com.dkl.leanring.spark.sql |
1.3 结果
1 | +----+----+----+----+----+ |
2、旧版
2.1 数据
data.txt1
2
3
4
5col1,col2,col3,col4,col5
11,12,13,14,15
21,22,23,24,25
31,32,33,34,35
41,42,43,44,45
其中列数可任意指定
2.2 代码
先看一下,利用rdd.map().toDF()遇到的问题1
2
3
4
5
6
7
8
9val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val data_path = "files/data.txt"
val data = sc.textFile(data_path)
val first = data.first //第一行作为列名
val colName = first.split(",")
val rdd = data.filter(_ != first) //注意first是列名,在这里的txt里是唯一的,否则会过滤掉多行
val df = rdd.map(_.split(",")).map(p => (p(0), p(1), p(2), p(3), p(4))).toDF(colName: _*)
df.show
通过上面的代码可以完成rdd转df,但是在构造元组的时候:(p(0), p(1), p(2), p(3), p(4)),只能通过()来构造,而每多一列就要手写加一列,不能通过:_*给构造函数传数组的方式来完成(目前我没有找到~),所以当列数很多的时候如上百列,这种方式很麻烦,可通过下面的代码解决。
1 | package com.dkl.blog.spark.rdd |
2.3 结果
1 | +----+----+----+----+----+ |
根据结果看,符合预期的效果!


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:旧版Spark(1.6版本) 将RDD动态转为DataFrame
本文链接:https://dongkelun.com/2018/05/11/rdd2df/
欢迎关注我的公众号