
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住给大家分享一下。点击跳转到网站:https://www.captainai.net/dongkelun

1、基本概念和用法(摘自spark官方文档中文版)
Spark SQL 还有一个能够使用 JDBC 从其他数据库读取数据的数据源。当使用 JDBC 访问其它数据库时,应该首选 JdbcRDD。这是因为结果是以数据框(DataFrame)返回的,且这样 Spark SQL操作轻松或便于连接其它数据源。因为这种 JDBC 数据源不需要用户提供 ClassTag,所以它也更适合使用 Java 或 Python 操作。(注意,这与允许其它应用使用 Spark SQL 执行查询操作的 Spark SQL JDBC 服务器是不同的)。
使用 JDBC 访问特定数据库时,需要在 spark classpath 上添加对应的 JDBC 驱动配置。例如,为了从 Spark Shell 连接 postgres,你需要运行如下命令 :1
bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jar
通过调用数据源API,远程数据库的表可以被加载为DataFrame 或Spark SQL临时表。支持的参数有 :
| 属性名 | 含义 |
|---|---|
| url | 要连接的 JDBC URL。 |
| dbtable | 要读取的 JDBC 表。 注意,一个 SQL 查询的 From 分语句中的任何有效表都能被使用。例如,既可以是完整表名,也可以是括号括起来的子查询语句。 |
| driver | 用于连接 URL 的 JDBC 驱动的类名。 |
| partitionColumn, lowerBound, upperBound, numPartitions | 这几个选项,若有一个被配置,则必须全部配置。它们描述了当从多个 worker 中并行的读取表时,如何对它分区。partitionColumn 必须是所查询表的一个数值字段。注意,lowerBound 和 upperBound 都只是用于决定分区跨度的,而不是过滤表中的行。因此,表中的所有行将被分区并返回。 |
| fetchSize | JDBC fetch size,决定每次读取多少行数据。 默认将它设为较小值(如,Oracle上设为 10)有助于 JDBC 驱动上的性能优化。 |
- 其实该部分翻译自Spark官方文档,所以对于翻译有疑问的可直接看官方文档
2、scala代码实现连接mysql
2.1 添加mysql 依赖
在sbt 配置文件里添加:1
"mysql" % "mysql-connector-java" % "6.0.6"
然后执行:1
sbt eclipse
2.2 建表并初始化数据
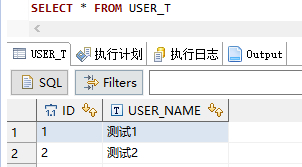
1 | DROP TABLE IF EXISTS `USER_T`; |
1 | INSERT INTO `USER_T`(`ID`,`USER_NAME`) VALUES (1,'测试1'); |
2.3 代码
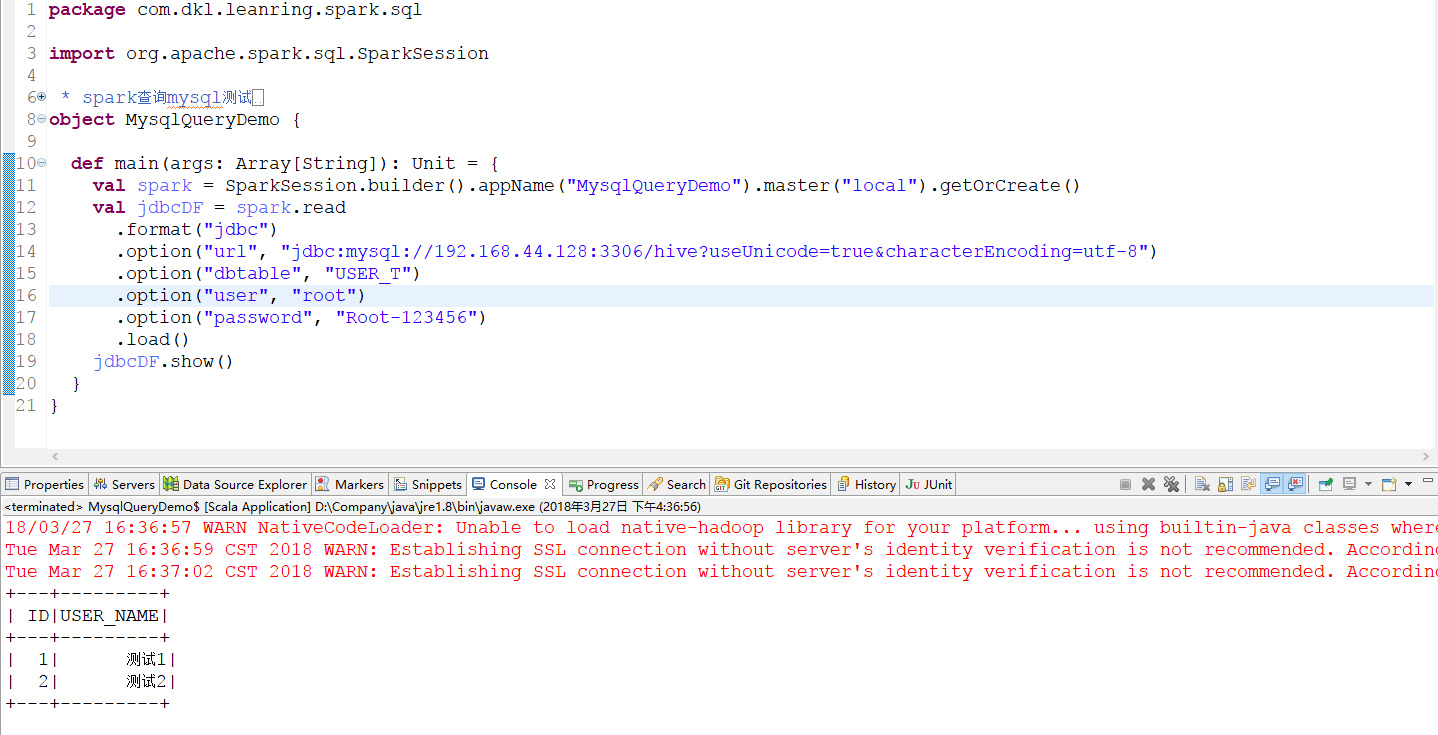
2.3.1 查询
1 | package com.dkl.leanring.spark.sql |
2.3.2 插入数据
新建USER_T.csv,造几条数据如图:
(需将csv的编码格式转为utf-8,否则spark读取中文乱码,转码方法见:https://jingyan.baidu.com/article/fea4511a092e53f7bb912528.html)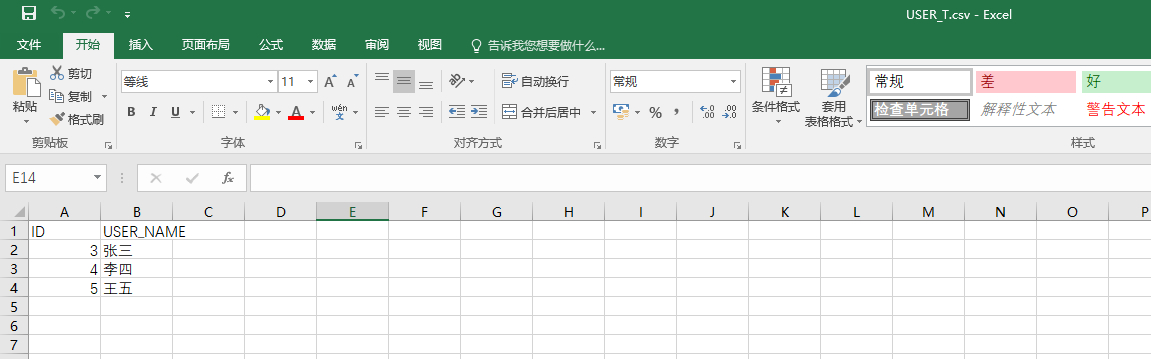
1 | package com.dkl.leanring.spark.sql |
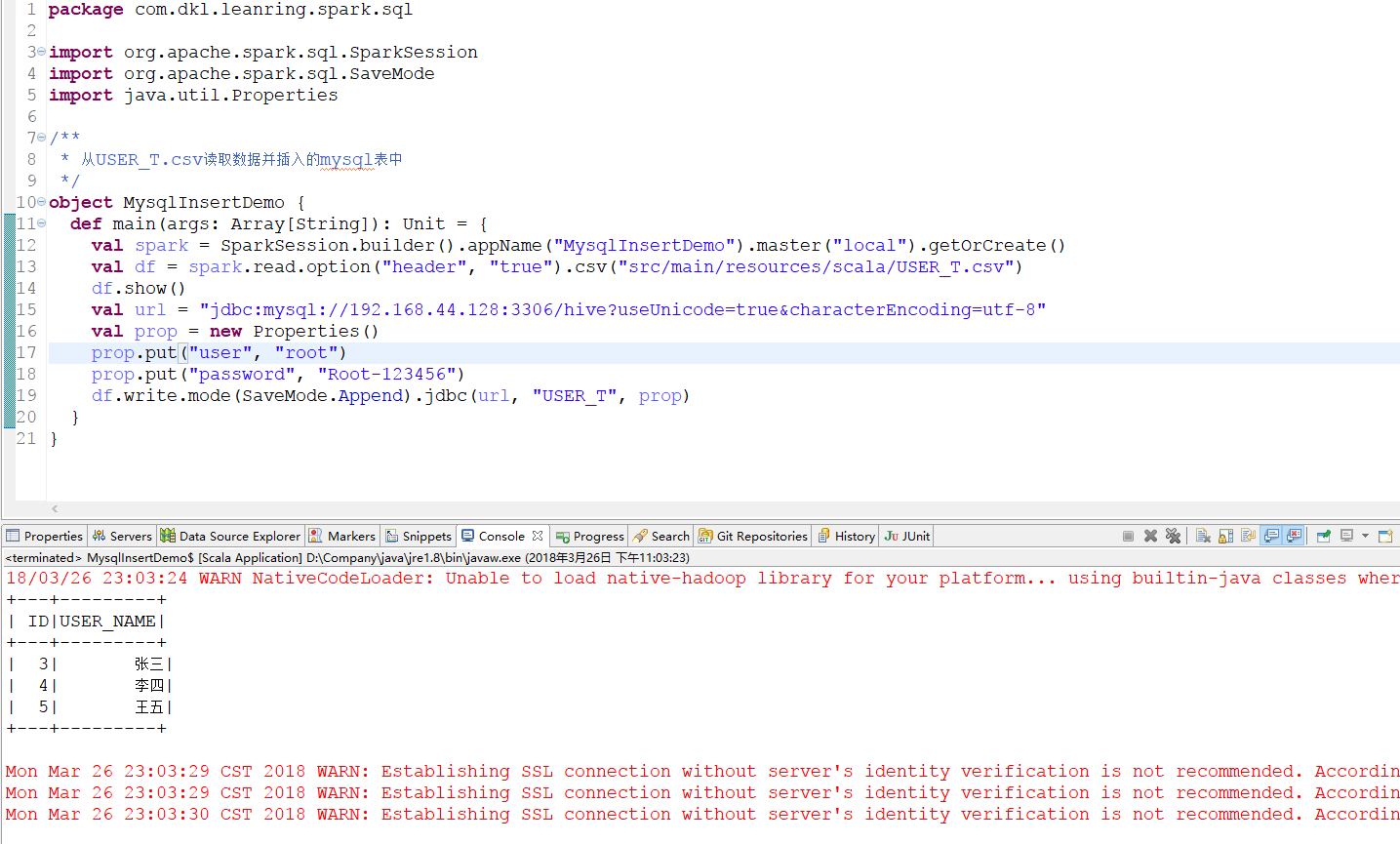
再查询一次,就会发现表里多了几条数据

3、注意(更新)
上面的代码在本地eclipse运行是没有问题的,如果放在服务器上用spark-submit提交的话,可能会报异常1
java.sql.SQLException:No suitable driver
解决方法是在代码里添加
mysql:1
.option("driver", "com.mysql.jdbc.Driver")
oracle:1
.option("driver", "oracle.jdbc.driver.OracleDriver")
具体可参考我的另一篇博客:spark-submit报错:Exception in thread “main” java.sql.SQLException:No suitable driver
4、其他读取mysql的方法(更新于2018.08.22)
发现还有Spark还有其他读取mysql的方法,其实只是上面讲的快捷方式(2.3.1),只附上用法,具体看以看api或参考其他博客,如spark:scala读取mysql的4种方法
(我就是在这篇博客看到的,该博客是Spark1.x的写法,若用Spark2.x将sqlContext改为本文的spark即可)1
2
3spark.read.jdbc(url, table, columnName, lowerBound, upperBound, numPartitions, connectionProperties)
spark.read.jdbc(url, table, predicates, connectionProperties)
spark.read.jdbc(url, table, properties)
- 只要在2.3.1的代码里用.option(key,value)即可
5、关于读取mysql的分区设置(更新于2018.08.22)
按照2.3.1的代码读取的DataFrame的分区数为1,若想改变分区数,一种方法是重分区1
df.repartition(numPartitions)
另一种是在读的时候设置分区数,在第一部分可以看到,通过numPartitions可以设置分区数,但是注意partitionColumn, lowerBound, upperBound, numPartitions需要同时设置
如:1
2
3
4
5
6
7
8
9
10
11val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://192.168.44.128:3306/hive?useUnicode=true&characterEncoding=utf-8")
.option("dbtable", "USER_T")
.option("user", "root")
.option("password", "Root-123456")
.option("numPartitions", "160")
.option("partitionColumn", "ID")
.option("lowerBound", "1")
.option("upperBound", "1000")
.load()
6、关于partitionColumn、lowerBound、upperBound(更新于2018.09.07)
一般只有当关系型数据库表数据量很大时,才会通过设置上面的参数设置分区,否则读进来再repartition即可,设置分区数的目的是可以使Spark读取数据库更快一点,经验证,合理的设置分区,Spark是可以并行的读取关系型数据库的。
- partitionColumn是用于进行分区的字段,一般最好是表的索引字段,且要求为字段类型为数字,并最好是连续的,这样分区才不会数据倾斜,也就是每个并行的任务读取的数量级差不多,才会更快的读取大表。
- lowerBound upperBound官网说是用来决定分区跨度的,对于这个说法我一开始理解的不太准确,它的值为partitionColumn在表里具体的范围,比如partitionColumn为ID,ID的范围为[1,1000],lowerBound、upperBound分别为1 100,numPartitions为10,那么可以分为10个并行的任务去读,比如第二个分区的认为的sql大概是这样过滤的”where ID>=11 and ID<10”。每个分区的ID的范围如下:0: 1-10 ,1:11-20,2:21-30,3:31;40,4:41-50,5:51-60,6:61-70,7:71-80,8:81-90,9:91-1000,需要注意的是Spark会把lowerBound、upperBound范围的数据按照ID等比例(按ID区间)分到每个分区上,而小于lowerBound的部分被分到了第一个分区,大于upperBound的部分则被分到了最后一个分区(大概sql就是第一个分区的过滤条件没有下限,最后一个没有上限~),大家可以自己写程序测试下,这里就不贴程序了。
- 另numPartitions应该小于等于upperBound-lowerBound


本文由 董可伦 发表于 伦少的博客 ,采用署名-非商业性使用-禁止演绎 3.0进行许可。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题:Spark Sql 连接mysql
本文链接:https://dongkelun.com/2018/03/21/sparkMysql/
欢迎关注我的公众号